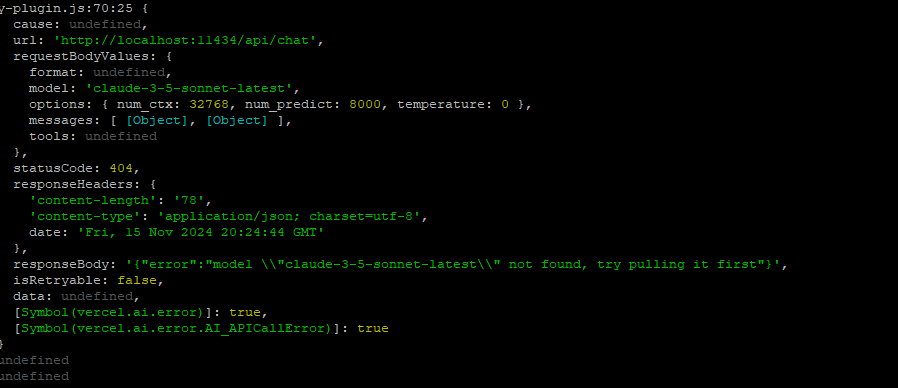
I think we have this recognized as a stale system state for the provider/model selection interface. I’ll be reviewing and most likely merging @wonderwhy.er’s PR #251 soon, best way to keep track of progress is via the GitHub PR page.
Standby if you’re here to say the same thing, I use Ollama too
I am having the same problem here.
I’ve install everything, ollama is running (accepts curl) but I can’t run it in oTToDev.
Same problem setting up LM Studio server, always show error 500 and in console show claude 3.5 sonnet.
try to console.log the error on the catch and see what is the actual error there.
You can try to change http://localhost:11434 to maybe http://127.0.0.1:11434 becuase maybe your OS does not resolve the localhost within the container.
btw do you check if ollama has any model running ?
ollama ps
should return at least one model
NAME ID SIZE PROCESSOR UNTIL
qwen2.5-coder:latest 4a26c19c376e 6.0 GB 100% GPU 4 minutes from now
Thanks for the additional tips @nicolaslercari - I am focused on collecting provider issues into an umbrella issue/upcoming pull request in the order they’ve come in, Ollama being first. I would suggest a re-pull of main as there is a PR that went in today related to the provider & model support.
I’ll post any updates with findings related to Ollama if/when they arise, thanks for the patience!
I’m reproducing this reliably during my own PR work, so I’m shifting over to focus on it now. Most likely just the need to update the backing store state of the provider/model selection when it changes on load.
I am a newbie to Ubuntu (22.04) and my installation of ottodev with ollama is not working. My error is attached, as stated, I do not know linux and will not be able to troubleshoot.
@mahoney -Thank you, I got Ollama working.
My system: Dell C4130, Ubuntu 22.04, 4 x Tesla M40 (24GB), 6.25 Token/sec, qwen2.5-coder:14b-instruct-fp16.
I have one more question, using “pnpm run dev” I can access the system locally, but how can I access it from another system on my network, as stated before I am new to linux and can only follow details steps given. Thanks again in advance.
You’ll notice in the vite terminal on run that it mentions a --host flag, that’s not being executed on the dev call but I believe you can pass that in somehow. I would like that to be a flag for the same reason, local network access but I’m not sure where to add that to the run process top of mind right now. That will (I believe) run the server on all of your external interfaces and be accessible on the network via external IP.
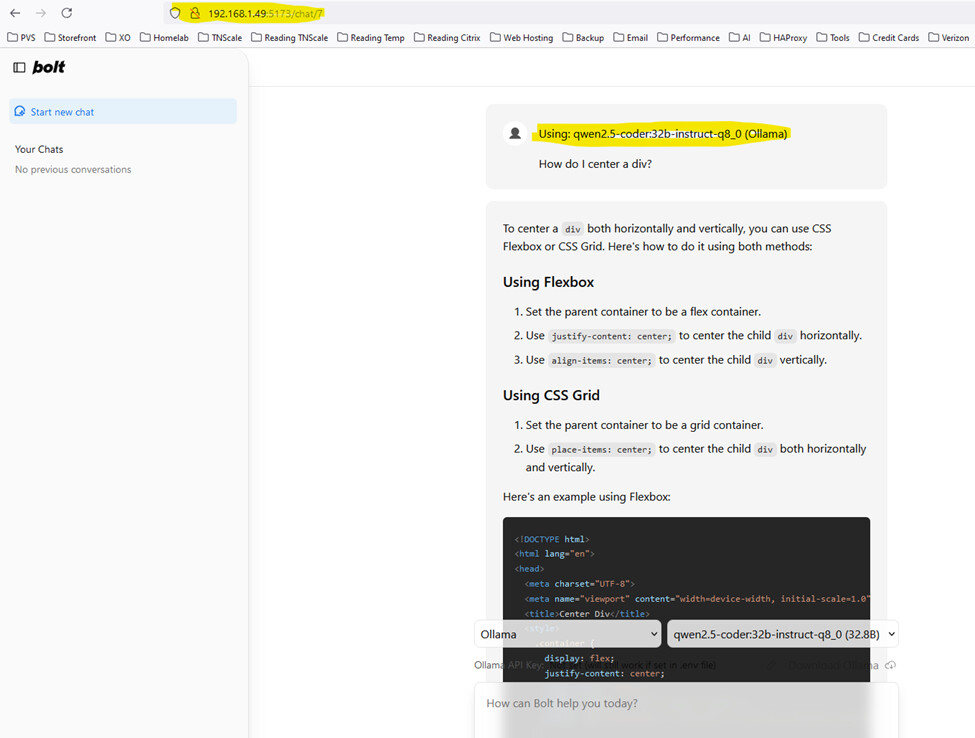
@Mahoney – I am not sure if this is anything that may be of interest but after adding the “–host” parameter to “pnpm run dev”, I decided to also change the host parameter at “bolt.new-any-llm/app/utils/cat constants.ts” to point to my computer ip address “192.168.1.49:11434”
After doing this I noticed OTTODEV got very slow. I ran “ollama ps” and saw that the model was loaded 100% in the CPU and was twice the size it should be ”110 GB”. Stopping and restarting the Ollama.service did not help, so I reinstall Ollama “curl -fsSL https://ollama.com/install.sh | sh” and restarted OTTODEV and this fixed both issues of seeing the ollama models externally and having the models loaded fully into the GPU.
when I reset the “constants.ts” parameter back to “localhost” it broke the external access with the error.
Again, I am not sure if this is of any use to you but just in case it may help someone else having slowness because the model is not loaded in GPU, or not able to access their models remotely. ( Note: I did not create a Modelfile as the num_ctx was already at 32768 for qwen32 /qwen14; ollama-dolphin was at 256000 by default)
It’s going to take a while for me to process these results, but thank you so much for sharing them. I do believe I’ve seen a similiar thing before, just as an FYI sometimes it has been because I’m focused on a solution and my battery is at 3% (goes into a wild hibernation mode) but I have a feeling you already keep an eye on your battery level
Edit: If you’re getting a dropdown to CPU only, that sounds not fun and any context around your hardware setup would help to resolve that