### Describe the bug
when using ollama its requesting claude-3-5-sonnet-latest …model this only seem to have happen in a recent PR
4:00:15 PM [vite] ✨ new dependencies optimized: vite-plugin-node-polyfills/shims/buffer, vite-plugin-node-polyfills/shims/global, vite-plugin-node-polyfills/shims/process, nanostores, @remix-run/cloudflare, remix-utils/client-only, js-cookie, @radix-ui/react-tooltip, @nanostores/react, react-toastify, ignore
4:00:15 PM [vite] ✨ optimized dependencies changed. reloading
4:00:16 PM [vite] ✨ new dependencies optimized: remix-island, ai/react, framer-motion, diff, node:path, jszip, file-saver, @octokit/rest, date-fns, @radix-ui/react-dialog, react-resizable-panels, istextorbinary, @webcontainer/api, @codemirror/autocomplete, @codemirror/commands, @codemirror/language, @codemirror/search, @codemirror/state, @codemirror/view, @radix-ui/react-dropdown-menu, react-markdown, @xterm/addon-fit, @xterm/addon-web-links, @xterm/xterm, @uiw/codemirror-theme-vscode, @codemirror/lang-javascript, @codemirror/lang-html, @codemirror/lang-css, @codemirror/lang-sass, @codemirror/lang-json, @codemirror/lang-markdown, @codemirror/lang-wast, @codemirror/lang-python, @codemirror/lang-cpp, rehype-raw, remark-gfm, rehype-sanitize, unist-util-visit, shiki
4:00:16 PM [vite] ✨ optimized dependencies changed. reloading
APICallError [AI_APICallError]: Not Found
at /app/node_modules/.pnpm/@ai-sdk+provider-utils@1.0.20_zod@3.23.8/node_modules/@ai-sdk/provider-utils/dist/index.js:505:14
at process.processTicksAndRejections (node:internal/process/task_queues:95:5)
at async postToApi (/app/node_modules/.pnpm/@ai-sdk+provider-utils@1.0.20_zod@3.23.8/node_modules/@ai-sdk/provider-utils/dist/index.js:398:28)
at async OllamaChatLanguageModel.doStream (/app/node_modules/.pnpm/ollama-ai-provider@0.15.2_zod@3.23.8/node_modules/ollama-ai-provider/dist/index.js:485:50)
at async fn (file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:3938:23)
at async file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:256:22
at async _retryWithExponentialBackoff (file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:86:12)
at async startStep (file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:3903:13)
at async fn (file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:3977:11)
at async file:///app/node_modules/.pnpm/ai@3.4.9_react@18.3.1_sswr@2.1.0_svelte@4.2.18__svelte@4.2.18_vue@3.4.30_typescript@5.5.2__zod@3.23.8/node_modules/ai/dist/index.mjs:256:22
at async chatAction (/app/app/routes/api.chat.ts:64:20)
at async Object.callRouteAction (/app/node_modules/.pnpm/@remix-run+server-runtime@2.10.0_typescript@5.5.2/node_modules/@remix-run/server-runtime/dist/data.js:37:16)
at async /app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:4612:21
at async callLoaderOrAction (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:4677:16)
at async Promise.all (index 1)
at async callDataStrategyImpl (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:4552:17)
at async callDataStrategy (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:4041:19)
at async submit (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:3900:21)
at async queryImpl (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:3858:22)
at async Object.queryRoute (/app/node_modules/.pnpm/@remix-run+router@1.17.0/node_modules/@remix-run/router/dist/router.cjs.js:3827:18)
at async handleResourceRequest (/app/node_modules/.pnpm/@remix-run+server-runtime@2.10.0_typescript@5.5.2/node_modules/@remix-run/server-runtime/dist/server.js:413:20)
at async requestHandler (/app/node_modules/.pnpm/@remix-run+server-runtime@2.10.0_typescript@5.5.2/node_modules/@remix-run/server-runtime/dist/server.js:156:18)
at async /app/node_modules/.pnpm/@remix-run+dev@2.10.0_@remix-run+react@2.10.2_react-dom@18.3.1_react@18.3.1__react@18.3.1_typ_qwyxqdhnwp3srgtibfrlais3ge/node_modules/@remix-run/dev/dist/vite/cloudflare-proxy-plugin.js:70:25 {
cause: undefined,
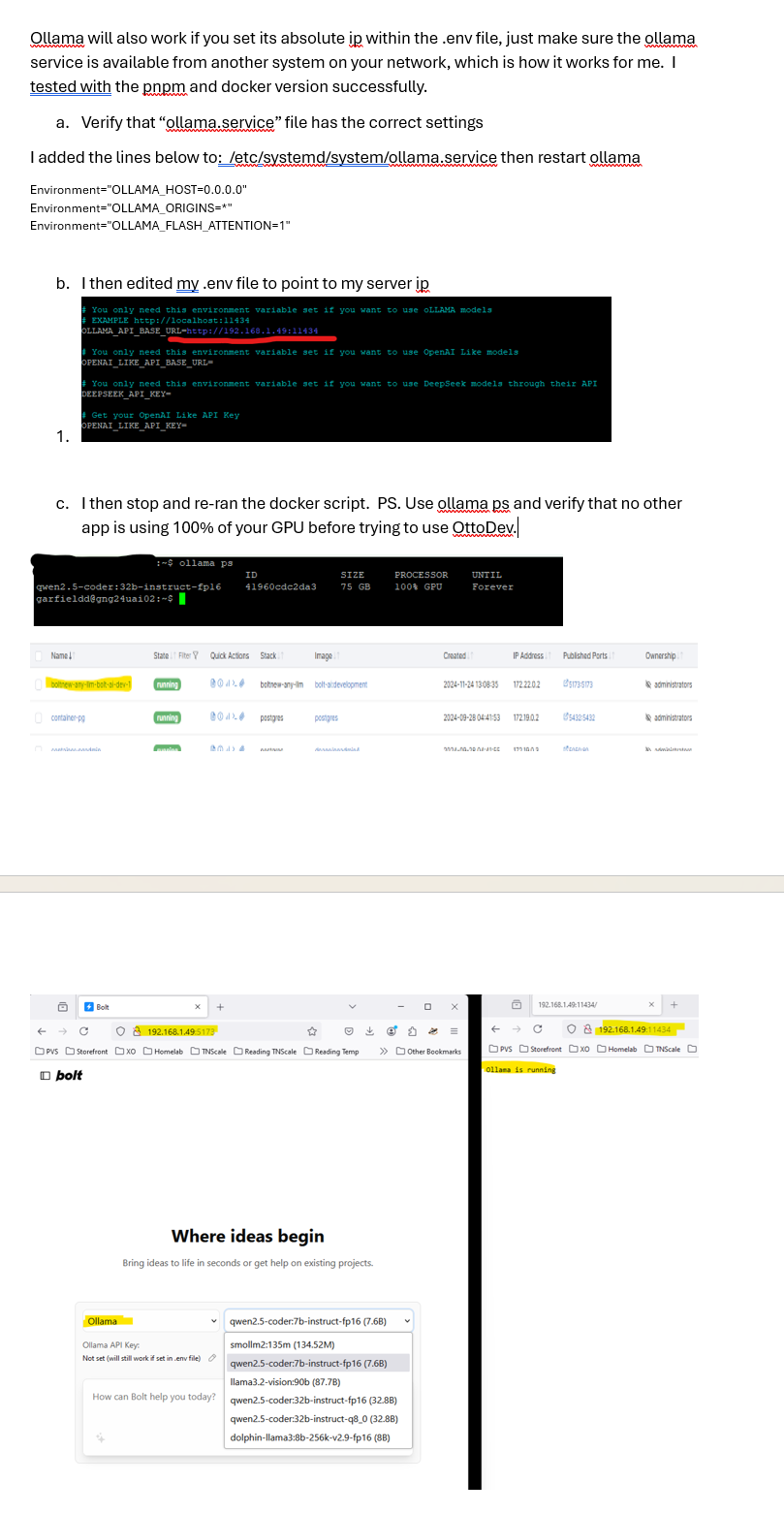
url: 'https://ollama.mydomain.com/api/chat',
requestBodyValues: {
format: undefined,
model: 'claude-3-5-sonnet-latest',
options: { num_ctx: 24576, num_predict: 8000, temperature: 0 },
messages: [ [Object], [Object] ],
tools: undefined
},
statusCode: 404,
responseHeaders: {
'content-length': '78',
'content-type': 'application/json; charset=utf-8',
date: 'Wed, 27 Nov 2024 16:00:45 GMT'
},
responseBody: '{"error":"model \\"claude-3-5-sonnet-latest\\" not found, try pulling it first"}',
isRetryable: false,
data: undefined,
[Symbol(vercel.ai.error)]: true,
[Symbol(vercel.ai.error.AI_APICallError)]: true
}
### Link to the Bolt URL that caused the error
n/a
### Steps to reproduce
select ollama, select ollama model
### Expected behavior
produce output from ollama
### Screen Recording / Screenshot
_No response_
### Platform
- OS: [e.g. macOS, Windows, Linux]
- Browser: [e.g. Chrome, Safari, Firefox]
- Version: [e.g. 91.1]
### Additional context
_No response_