Hey @ColeMedin Great to be here and thanks so much for all your videos.
I’d like to setup Craw4Ai within an n8n automation after watching your latests.
Is that possible?
3 Likes
I was wondering this also! I hope @ColeMedin will be able to fill us in on the details for this. Or maybe some of the other community members will have some details on it. Thanks for bringing it up!
Jay
3 Likes
My pleasure. I’ve just this week worked out how install the starter kit with Docker on Digital ocean… this made my head spin (haha)… but I’m at a loss as to how to setup the envionment and get n8n to talk with this tool. It looks amazing and I’m keen to get the content in to Supabase.
Great question @samir and @southbayjay!
So Crawl4AI is a Python library, so you aren’t going to be able to use it directly in an n8n workflow unfortunately. Even if you were to try to create a custom n8n node, you have to use JavaScript not Python for that.
However, what you can do is create a implementation around Crawl4AI with Python and set it up as an API endpoint using something like FastAPI. Then you can have n8n call the API endpoint as a part of the workflow or as a tool for the agent!
Of course this requires you to code and not just leverage no-code, but that will be a requirement no matter what for Crawl4AI until someone builds a nice wrapper around it (would be an amazing project!).
2 Likes
LangFlow and Windmill are a few other options that support Python. Though I’m still a noob at both (and I’m only beginning to get comfortable with n8n).
Also, there are several others like Node-RED, Apache Airflow, Prefect, and StackStorm. But I haven’t personally used them.
Apologies if TMI.
1 Like
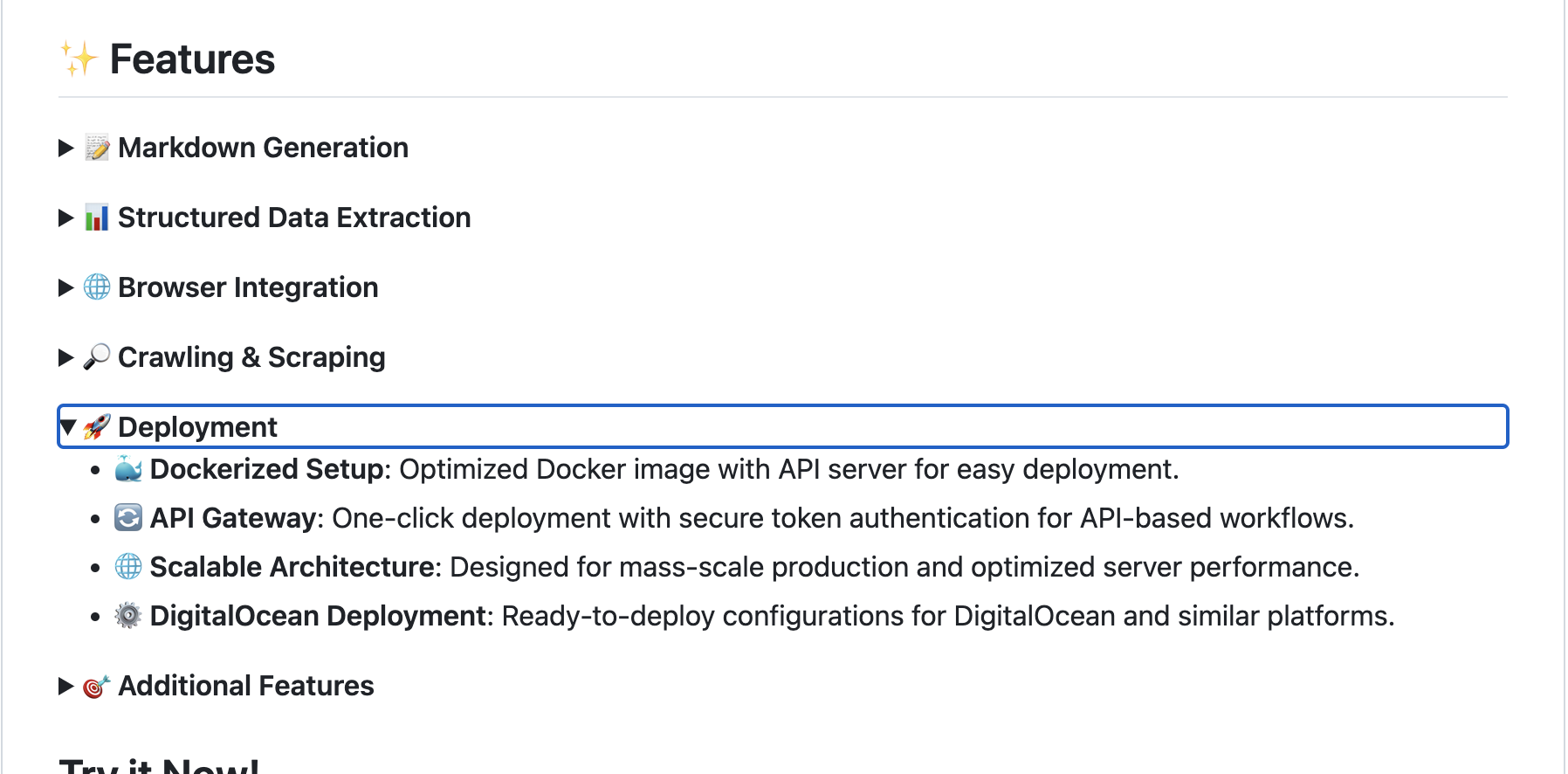
Thanks for the reply. I guessed as much. What confused me is this in their readme in the Features section it says:
Deployment : ![]() API Gateway: One-click deployment with secure token authentication for API-based workflows.
API Gateway: One-click deployment with secure token authentication for API-based workflows.
Maybe I miss understood?
My usecase is that we’ve a website we’d like to monitor (ethically - it contains regulartory information). It has sitemap.xml which includes dates of last update. I want to scrape the site once and put this into Supabase. Then scrape the changes (say comparing status v new to a reference table in Airtable) once a day to keep the vectors up to date. It’s quite a big site so I’d just like the changes. Anyhow. I will have another think about this. Really liked the Craw4Ai features though… now if only their was something simlar for pdfs!
There are many options for Web Scraping with n8n, including Puppeteer with an HTTP Request node, and setting up a schedule. Then you could do a comparison between the two sets of data over time, and you could just store changes which would reduce space. Then create a dashboard, possibly with email notifications, etc.
So, unless you are 100% committed to using Craw4Ai, I wouldn’t constrain yourself to it.
P.S. Nothing would stop you from just doing this in JavaScript or even a GitHub/Cloudflare Worker though. And that’s maybe the problem, there are a lot of options to do what you want.
However, I did find this tutorial Agent-Driven Schedule: Build a calendar scheduling agent with Composio and CrewAI in Langflow | Medium.
2 Likes
I got it setup like Cole showed in the video and tested it out, everything is working wonderfully!! BUT how do I set it up to crawl a site that doesn’t have a sitemap? I tried editing the URL in the crawl_pydantic_ai_docs.py file but it didn’t like that, my guess because it wasn’t a sitemap.
Actually I’m going to crawl the craw4ai docs website and use the UI to ask it that question.
@ColeMedin it would be great if in the next video you could show us how to use this with a local database? The only reason I ask that is because if the supabase sites for a week they pause it. I’m not a cheapskate but I don’t want to pay $25 a month for it, yet. I’m not making any money on this stuff yet. ![]()
2 Likes
Haha I love the idea of setting up a Crawl4AI expert to then ask your question! If a site doesn’t have a sitemap.xml then you’ll probably want to start on the home page, scrape any URLs to visit there, and do that recursively.
You can host Supabase locally! So in the next video I show how to do it with Supabase in the cloud but you can very much do it for free too.
1 Like
I did set it up to crawl the crawl4ai docs and got my answer and even used it (and Windsurf) to help with some errors. It worked out perfectly!
I need to go back and watch some of your old videos to refresh on connecting to a local database.
Thanks for all your help!
Jay
1 Like
Perfect - Sounds like a plan.
Yeah you bet!
1 Like
Hey @ColeMedin Thanks for the video on setting this up. Got it going today. Any tips on how to control the markdown it generates? At the moment it is filled with all kinds of rubbish from the page - I have tried in vain to get the fit_markdown working.
{
"urls": "{{ $json.loc }}",
"priority": 10,
"crawler_params": {
"browser_type": "chromium",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36",
"simulate_user": true,
"magic": true,
"override_navigator": true,
"wait_until": "networkidle0",
"verbose": true
},
"output_formats": ["fit_markdown"],
"content_filter": {
"include_selectors": [".entry-content"],
"exclude_selectors": ["nav", "header", "footer", ".sidebar", ".popup", "form"]
}
}
1 Like
You’re welcome!
Have you checked out the bottom of the Crawl4AI Docker docs page?
There are a few great examples there of doing intelligent extraction with LLMs. That would be my suggestion to take all the junk out of the crawl results!
Thank you. I looked at this but think the version of the docs was seeing is out of date. This has lots of useful suggestions. Lost 6 hrs of my life tweaking in vain with this so far - hopefully this is the trick (I’ve set Nate off looking now too haha!) Thanks again
@ColeMedin sorry to bother you again with this. So I got decent results (thanks for the links) and happy with the scrape content.
1- I’ve now spent hours trying to deal with memory issues. I setup the same Digital Ocean App Platform setup as you showed. But rather than Crawl4Ai being really memory efficient - like you showed in the PydanticAi example - I’m struggling to scrap more than a handful of page before it tops out of memory.
I’ve tried:
- Lots of conbinations of the crawler_params (with guidance from chatbots)
- I’ve tried modifying the scraps into batchs - so each job takes x number of urls in one go.
- restarting the instance
Nothing works.
Any tips?! Tearing hair out here! … At least when you visit us over in Nates community I won’t badger you with this haha
1 Like
No need to apologize!
I noticed this as well with Crawl4AI in DigitalOcean - I had to get a machine with at least 4GB of RAM and even then I got into memory issues when scraping hundreds of pages.
I think there is a problem with the Crawl4AI container itself. Something that is optimized horribly haha
I know they are totally revamping their container setup soon and I’m guessing making it WAY more efficient is going to be a part of it. I don’t think you are doing anything wrong!
Spent a day iterating on ideas for this! haha … hope they can improve things because when you demo’d in the pydantic example it as amazing. Tbh I would try that too but I don’t know how to setup a server to run it! Will keep at it and thanks for the reply.
1 Like
Dang that’s a while, sorry you spent so much time on it! I really hope they improve it soon too.
You mean a server to run the scraper periodically? I would look into getting a DigitalOcean droplet and hosting it there! And if you have any specific questions please feel free to ask!
Let me add my thanks, @ColeMedin. Your video on this topic kickstarted some ideas that have turned out to be very useful not just for me and my company, but I’ve also forwarded the link to others who are also interested in the value of some quick wins in this area.
In my case, the memory problem was solved by reducing the time-to-live (TTL) on crawl requests. It looks like each request (and, consequently, its result) is cached in memory for a period of time that defaults to an hour (3600 seconds). Since we are looping through and obtaining the results almost instantaneously, this consumes more memory than is really needed.
Prior to making any changes, my failures started at around 75 page requests, but I have now reduced the TTL to 60 seconds and successfully crawled over 300 pages. During this execution, memory usage barely tipped the scales past 3GB and CPU usage was significantly reduced (I don’t have specific measurements, but yesterday my 8 threads were fully loaded to 100%, whereas today I’m hovering between 20-30% during execution with peaks up to around 50%.
You can reduce the TTL on each request by adding an additional parameter named ttl with a value of 60 to the HTTP Request step that makes the POST request to crawl endpoint.
As always, your mileage may vary, but I hope this suggestion also gets you past this hurdle so that you can continue making progress.
2 Likes