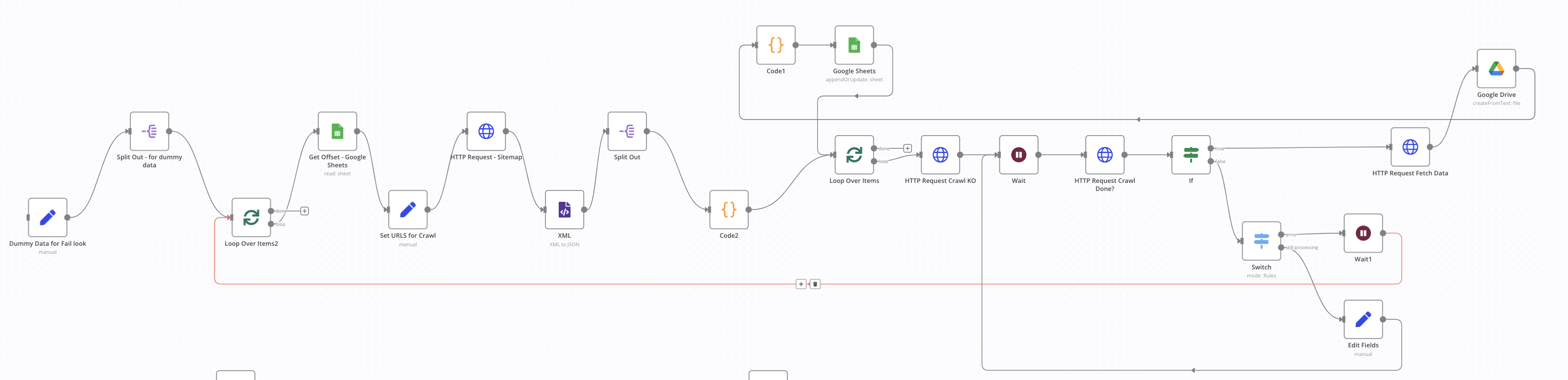
Would you be able to add some additional information about the change you made? The only place I could find to add the TTL parameter was on HTTP Request1 which didn’t seem to solve the issue. The issue seems to be related to HTTP Request2 but I couldn’t find a way to add ttl to it.
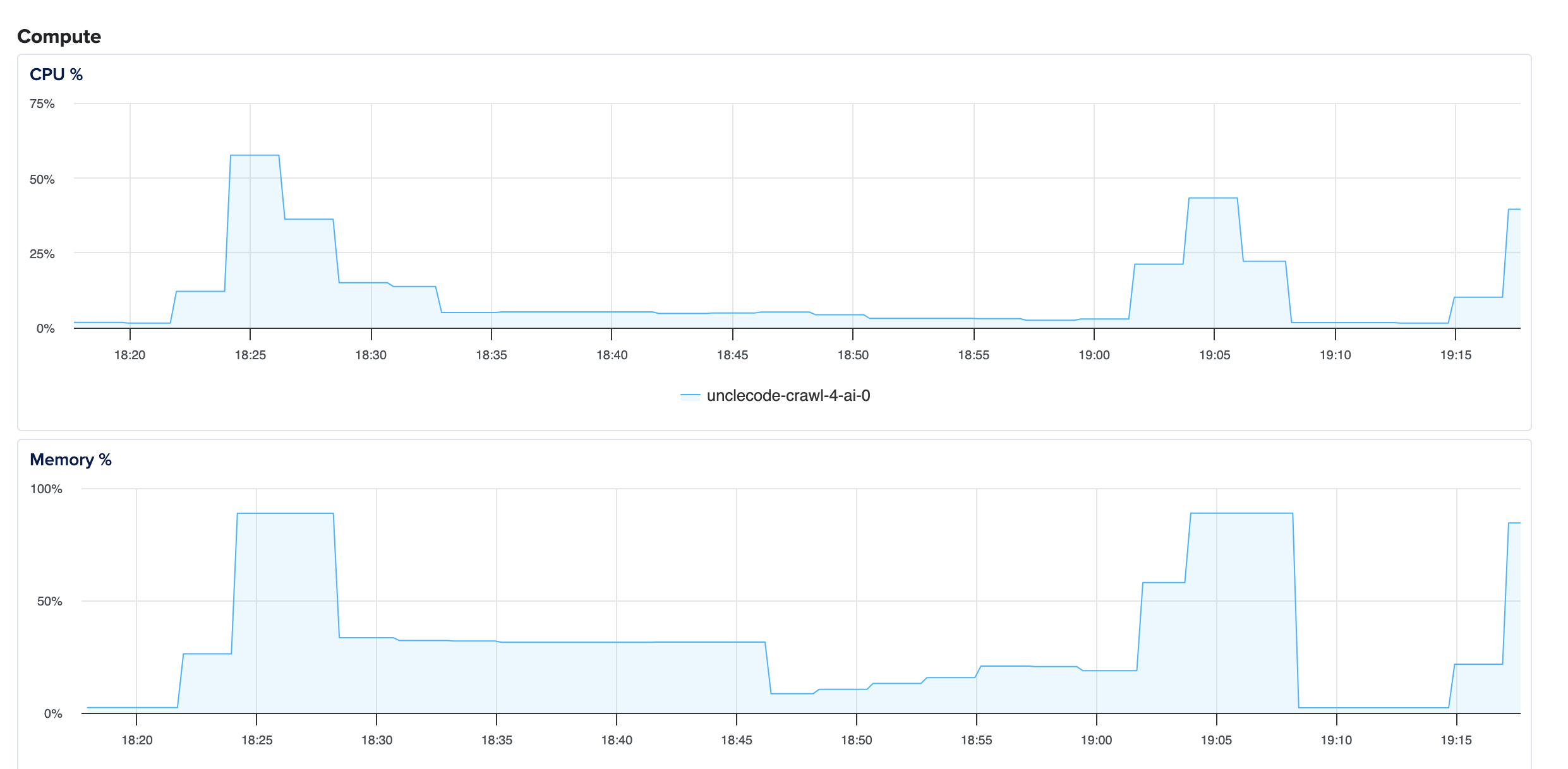
You definitely seem to be onto something though because I checked the resources on digital ocean and memory pegged at 100% and then the process crashed. I even bumped up to a server with 16GB of ram and it still crashed so there’s definitely an efficiency issue.
@cabro This did though… in essence I accepted it will fail, and then created a loop to have another go. As there are no state variables, I created a counter in google sheet so that when it re starts, it starts from where it left off.
Ah, I was wondering about that because how it is now, when I run it again it will just dump duplicates into Supabase so I would have to do a check for that.
Thanks for the info, i’ll try to make similar changes.
Ok, small update. I moved the whole project to a local docker desktop install and it’s completely fixed the issue of running out of memory. The new problem I have is that after pulling a few hundred url’s is that is errors out referencing https://seashell-app-gvc6l.ondigitalocean.app which i’m not using anymore.
I changed HTTP Request1 and HTTP Request2 to point to my local docker install but there still must be something else I can’t seem to find pointing to that old docker container. I searched the json file and cant find anything.
Hey guys, very interesting thread! I’ve followed Cole’s video (Massive thank you) but am just starting out with n8n.
If I’m using Cole’s flow, how do I add parameters so I can either use css_selector or exclude_tags - or both.
Would these be set in the HTTP Request2 node, using the send query parameters option?
I played around a little but couldn’t get it to work.