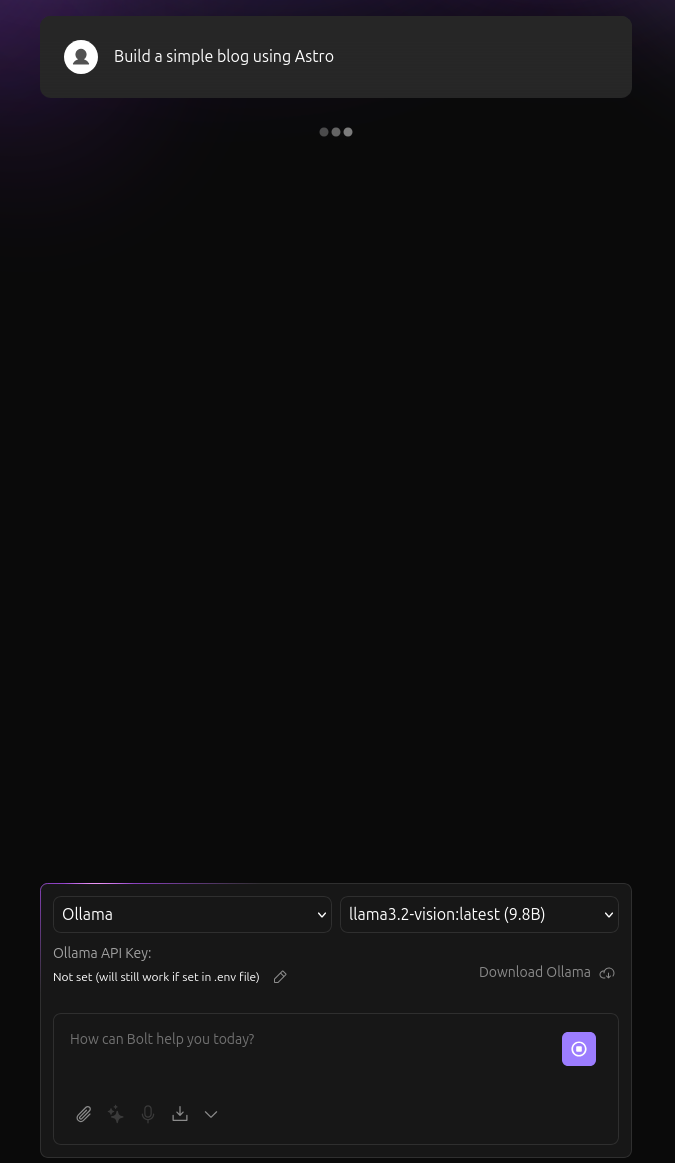
I managed to install the program locally (using pnpm) and am able to access it via localhost:5173. I also managed to connect the API (I connected the OpenAI - I have a paid account - and my Ollama - which correctly lists my two llamas that I have installed locally)
However, when I want to interact with the program, after I give in my prompt, nothing happens - the “…” loading animation is in an neverending loop, and I get no messages from the system or console that there are any errors.
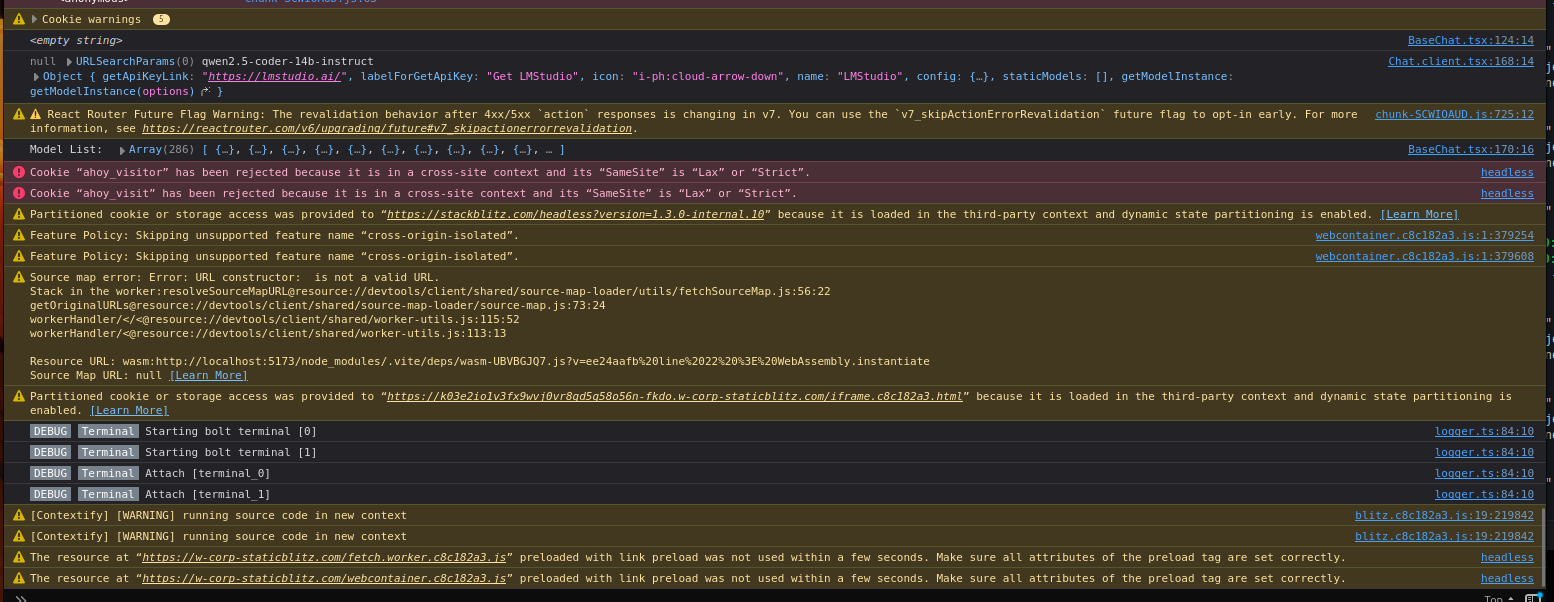
when i click on the logo of bolt.diy, there is a quick flash of an error (…something something fetch something…), i have just seen that, but it is gone too quick to take a screenshot)
I’ll gladly give you any further info, thank you so much for help
I have “http://127.0.0.1:11434/” under Ollama link settings. I checked the endpoint with curl and, as far as i am understanding, it works - i get a response)
my llama is running and if I run the model in cmd I can talk to it. is there something else that i am missing or not understanding correctly ?
As often mentioned and discussed in other topics => I am not a great fan of local models unless you got a very powerfull pc to run bigger models, which then can produce useful code within a aceptable time.
I would recommend using OpenRouter.ai with very cheep models, or use free models like on Google atm.
Also see the General Chat. @wonderwhy.er just did a test with ab 14B Qwen Coder, which worked.
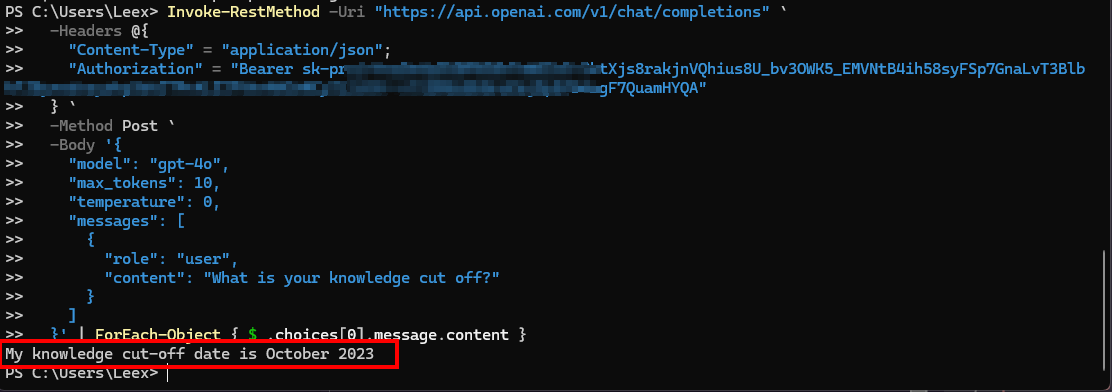
Understood, but the exact same thing is happening when I use OpenAI API - on the OpenAI platform, under dashboard, I can see that the API i am using was accessed by bolt.diy (as no other program could access the freshly made API).
but the result is the same - endless animation of “…”
do i still need to create a server and test the API, I think that dashboard indicator should signal that the connection was made after all…
The dashboard just says that you tried to request something, but could end up in an error, because of maybe you are not on a paid plan and dont have the permission to access this model or whatever.
For testing the curl you dont need to create an server. Just do it in git bash or do an Invoke-Webrequest instead of curl in Powershell.
I have tested the API and learned something new - funds for API usage are not included in the payment playn for ChatGPT (noob mistake, but I learned). Switching to Anthropic anyhow.
Still cannot get over the fact that Ollama is outright not working for me in bolt. I can understand that it is sub-optimal, but I need to run my project via the local LLM (school project). I have tested the llama via curl and am getting a result, also the port iscorrectly linked as far as the trouleshooting on this page tells me.
Thanks for helping a noob out. I am out of ideas what to do or which model to choose
Downloaded it a second ago.
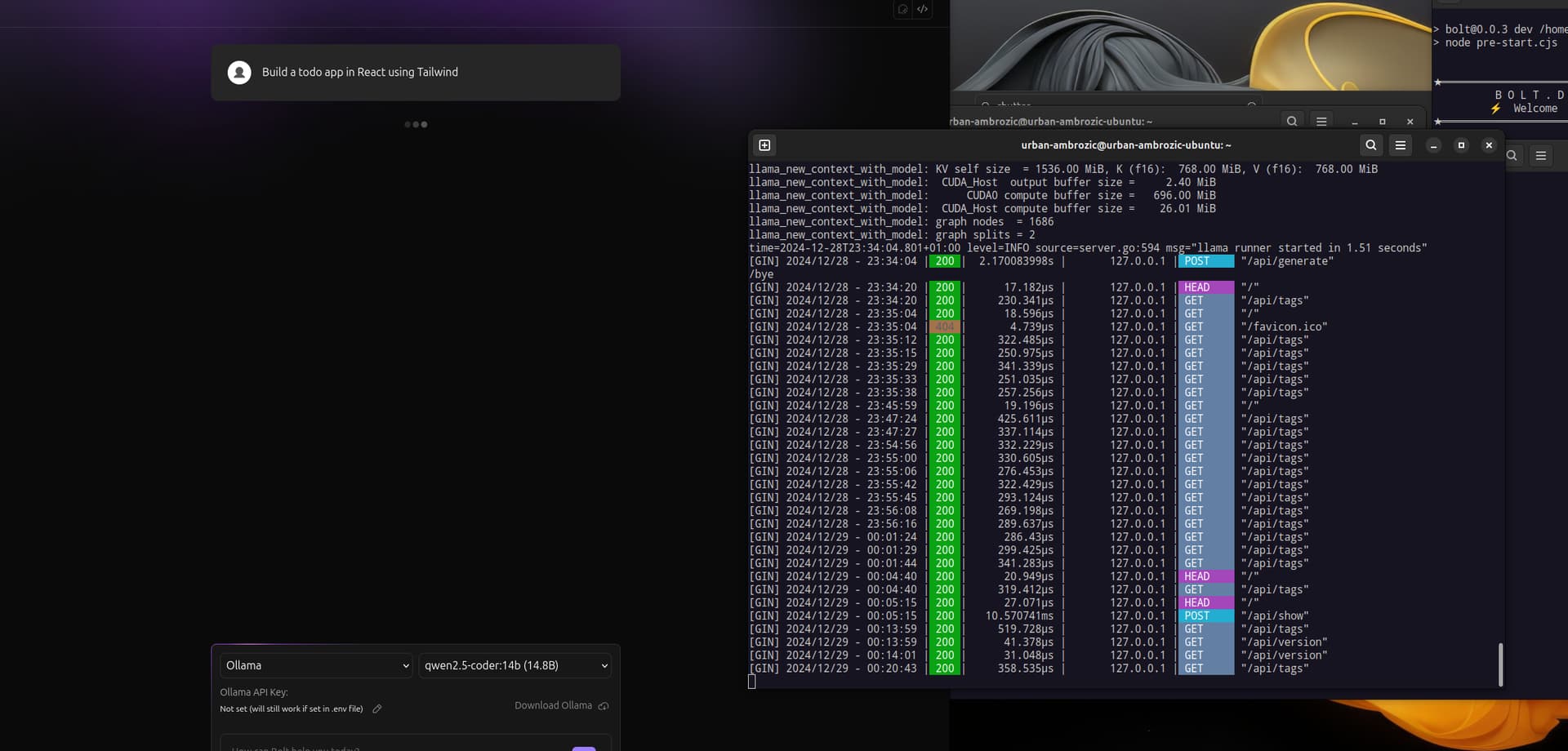
i can converse with it via bash and via OpenWebUI (running thru Docker).
It was listed immediately in bolt.diy - however, same results as with other models - no response
You can start a server there and load your models which then will be displayed in bolt.
You also can enable cors and as I say this, maybe you missing some params for ollama that allows access from outside the terminal.
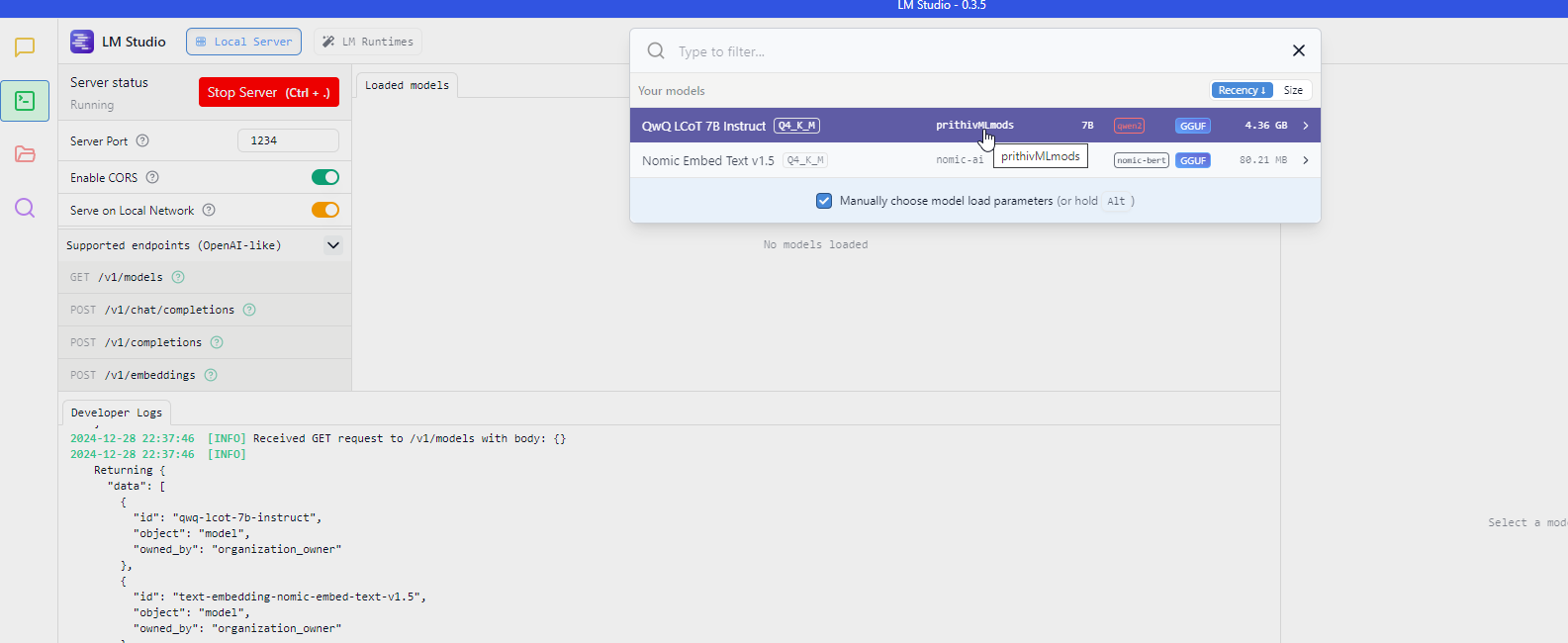
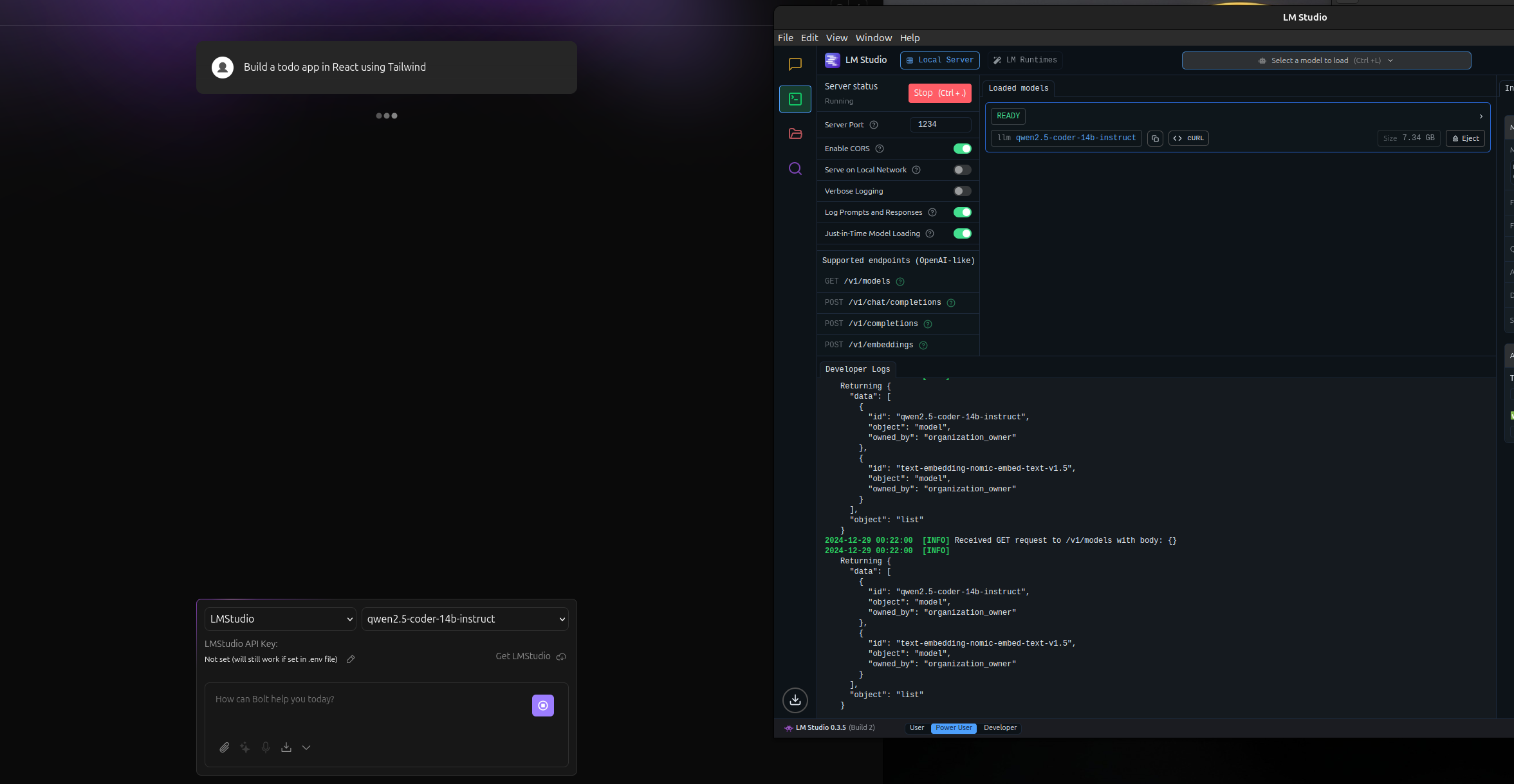
I managed to install lm-studio.
not sure why it is not picking up my models when i direct it to the folder, but then when I download the model it can access it - i think i do not get the fact where and why my llamas are downloaded…
anyhow, LM studio is successfully booting qwen2.5-coder:14b, I have set up the localhost:1234 and linked it to bolt.diy. The model is recognised, but the system is returning no results - same as before
I can see the requests getting made to ollama (via bash) and to LM Studio (via integrated cmd line)
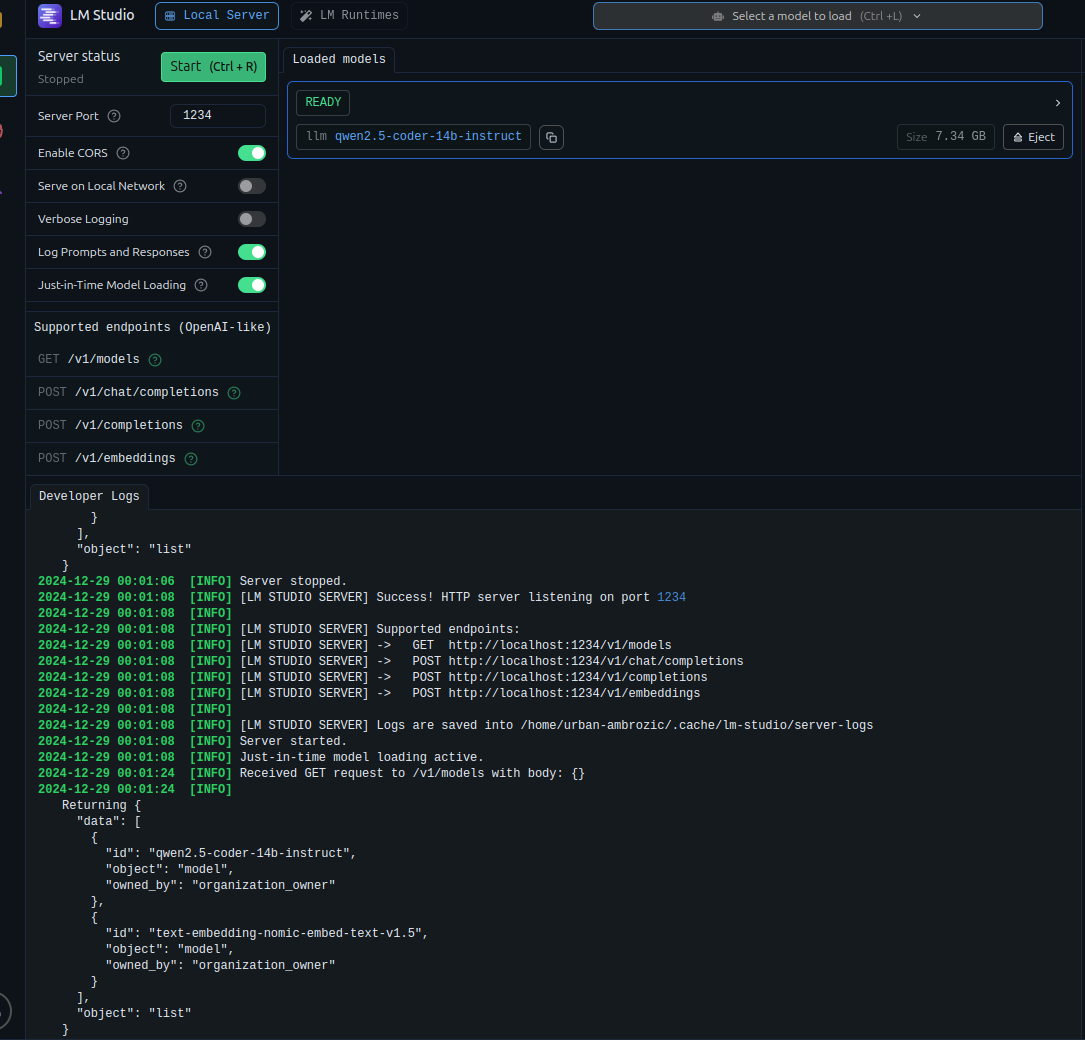
the cmd of LM-Studio looks like this:
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] Success! HTTP server listening on port 1234
2024-12-29 00:01:08 [INFO]
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] Supported endpoints:
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] → GET http://localhost:1234/v1/models
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] → POST http://localhost:1234/v1/chat/completions
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] → POST http://localhost:1234/v1/completions
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] → POST http://localhost:1234/v1/embeddings
2024-12-29 00:01:08 [INFO]
2024-12-29 00:01:08 [INFO] [LM STUDIO SERVER] Logs are saved into /home/urban-ambrozic/.cache/lm-studio/server-logs
2024-12-29 00:01:08 [INFO] Server started.
2024-12-29 00:01:08 [INFO] Just-in-time model loading active.
2024-12-29 00:01:24 [INFO] Received GET request to /v1/models with body: {}
2024-12-29 00:01:24 [INFO]
Returning {
“data”: [
{
“id”: “qwen2.5-coder-14b-instruct”,
“object”: “model”,
“owned_by”: “organization_owner”
},
{
“id”: “text-embedding-nomic-embed-text-v1.5”,
“object”: “model”,
“owned_by”: “organization_owner”
}
],
“object”: “list”
}
2024-12-29 00:01:29 [INFO] Received GET request to /v1/models with body: {}
2024-12-29 00:01:29 [INFO]
Returning {
“data”: [
{
“id”: “qwen2.5-coder-14b-instruct”,
“object”: “model”,
“owned_by”: “organization_owner”
},
{
“id”: “text-embedding-nomic-embed-text-v1.5”,
“object”: “model”,
“owned_by”: “organization_owner”
}
],
“object”: “list”
}
Strange,
is CORS enabled in LM Studio as seen in my Screenshot?
Also maybe just take some screenshots and past it (bolt + dev tools open, LM Studio, terminal where bolt is running,…)
I dont see where the problem is yet.