A major roadblock for me using Bolt/OD is token use running out. I am not a developer so I prefer to keep it in oTToDev as long as possible.
With the goal to keep developing an app in OD indefinitely with low token use, here are a few simple ideas:
Add a Reset Context button - removes all context from the conversion except the current/latest version of the app.
Add a timeline or checkbox feature to select which app versions/prompts/context to keep. Typically for me, I would frequently like to keep only the 1st user prompt (my instructions for the app), and the most recent system message (latest version of the app). I rarely, if ever, want to keep past/intermediate versions of the entire app loaded in context (correct me if wrong but I believe this is currently the case).
Existing project upload - already on the roadmap but too exciting not to mention
Killer work guys, keep it up!
If others have ideas on how to improve token use please comment!
It might be interesting to create a file where a timestamp is added along with a summary of the user’s request and a summary of the changes made by the model, plus the updated file structure (if there are new files or if any have been deleted). In this way, instead of feeding the full context of the chat filled with code and files, you can provide just this file and, at most, the part that needs to be modified or the specific portion of code to be changed.
I’m testing this technique with Cursor, and it needs refinement, but it helps a lot.
This is usually where Cursor will let you choose the number of files added into context.
But with something like Bolt, we’re talking about automatically maintaining context.
One of the earlier approaches for this - especially when LLMs had much smaller context windows - was to do embeddings, and automatically pull content that was relevant to a specific request.
That can work when you’re mainly working with text, but when dealing with code, it may require a more complex approach to make sure that the right information is pulled to help out.
Yes, some form of RAG.
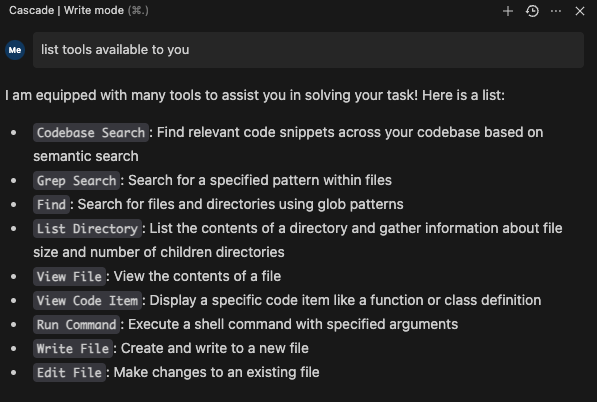
Here is what Windsurf provides for LLM/Chat as tools for that
What we will need is similar things, build/curate/filter context.
But it should be done as API with ability to try and setup different approaches, plugin in CGRAG if possible and so on.
Problem with some of solutions though is that they are not portable.
Bolt is full stack javascript app with webassembly container.
Largely meant to work locally, server is just a proxy.
Server does not even know about files.
A big one for me would be to have the LLM use templates wherever possible. It would not only save on Token usage but also produce a working baseline. The LLM could determine the category and template that best meets your needs, such as examples provided on the main page:
Build a todo app in React using Tailwind
Build a simple blog using Astro
Create a cookie consent form using Material UI
Make a space invaders game
Make a Tic Tac Toe game in HTML, CSS and JS only
Beyond that, modifying parts of a file instead (using diffs would be great because you also could implement history, compare features, etc.) of updating it each load, in conjunction with caching would dramatically reduce the token usage. And of course, yes a RAG (but I see that done at more the workflow level, say using n8n).
Imo, I think those things could reduce token usage by like 90% in most cases.
My testing shows that using straight chat uses only a few tokens (less than 100 usually, maybe a bit more; notice the OpenRouter: Chat… line). But doing a one-shot sample project in Bolt.New like “Build a todo app in React using Tailwind” as a baseline uses 3-5K tokens.
Definitely would be nice to see token usage and stats (it/s, latency, etc.) integrated into oTToDev… But the point stands the UI has inefficient token usage (namely re-writing files, trying steps, back and forth, etc. are causing most of the use).
Hello Edwards great youtube channel by the way, i dont know exactly what dsmflow refering to, but follow Mckay Wrigley on x and mention on his post about his o1 pro workflow about a XML Parser x.com his full workflow here https://www.youtube.com/watch?v=RLs-XUjmAfc and mention using a git repo for 01 XML Parser linked in the youtube video
Also i found this on reddit talking about that workflow and someone mention that Aider works better even than the XML workflow here: “Nice workflow. Your XML Parser is what Aider does with --copy-paste mode to apply changes from the Web UI to your code. Aider is just probably more robust with diff and whole editing modes. He (author Paul) also has an article of how LLMs don’t usually follow code editing instructions in JSON or XML, hence the SEARCH/REPLACE we use in Aider. The workflow is great, using the open-source Aider might save you more time” this is the post: https://www.reddit.com/r/ChatGPTCoding/comments/1hbccol/this_openai_o1_pro_coding_workflow_is_insane/
Thanks for sharing. We were discussing these things and I was sharing Aider as example to look at too for diff editing.
Was playing with making ChatGPT do that for a while in
Tried to make LLMs to output line changes(does not work), git patches(very bad) and tried merge conflict syntax and search/replace.
Both are not perfect and have issues.
But I found workarounds for that.
Usually issues are in very small differences.
All in all we will get to experimental diff editing.
Its not really a rocket science but still lot of trial and errors.
And opensource tools like Aider already did much of it.
I have no experience in doing this but would a ML model that’s built into bolt.diy work where every time you start a new project the model learns about your code and how it works then when you submit a prompt it could suggest files to send for the context?
Its tricky to do that. I don’t think I have ever seen that to work.
Its kinda like making AI summarise and document things.
And then use documentation. But that documentation would miss details and itself would add to things model would need to know.
Usually RAG works better. For well commented code searching for examples of real working code would work better.
If you take a look at how Cursor and Windsurf work they just index and search code as part of the multi step generation flow.
basically what you are suggesting is whats called contextual rag, before chunking the documents add some context about the chunk so that its easy to understand what that snippet is for in the overall picture.
then use that along with the content of the snippet to create the semantic vector.
it works great but is resource intensive. we will also need a vector store to save these details for RAG. and now the question is do should go for that route or not as this will require a db integration