You are welcome, they mention in the office hours that was difficult problem to solve. And recommended several workarounds to mitigate the token usage. One is to lock the files that they talk here: https://youtu.be/xpXvb7bvipc?t=1635 and the other is to Ask bolt to extract the logic and structure into smaller files here is the tip and the prompt: x.com maybe add those features to bolt.diy would help in the mean time until we get a diff functionality.
1 Like
Yeah, we discussed those things before.
We may need to do file locking as intermediate step. I am not big fan of it.
I would probably rather go with “file focus” like Aider or Cursor does, that you select files to work on, rather than files you exclude.
And about changing prompt to ask to code to as small files as possible is also a good thing yes. This I do want.
Is holiday seasons though, I am bit out of it atm.
Do want to get back to more actively working on these things and helping others to contribute too.
For me next things are “show token usage when possible” to start measuring what is happening.
Then to make LM Studio and Ollama work from hosted version.
Then I do want to get to focus/splitting to smaller files stuff.
And then to diff editing if no one gets there faster.
1 Like
So I’ve been working on something that I think may help quite a bit, is there any way we could chat? It’s a lot to fit me to just post on here, needless to say, if done correctly, it could reduce the number of tokens sent back and fourth dramatically
2 Likes
this is something specific for Claude, but we can pick some concepts and aspirations
1 Like
Most providers now do prompt caching but in slightly different way
OpenAI just does it.
Google needs setup
Antropic needs parameters.
Batching is async. You send a lot of stuff and it processes over next 24 hours when their hardware is less used, and for that you get discount.
I guess addding support for Antropic API caching makes sense for small wins for only those who use those models.
3 Likes
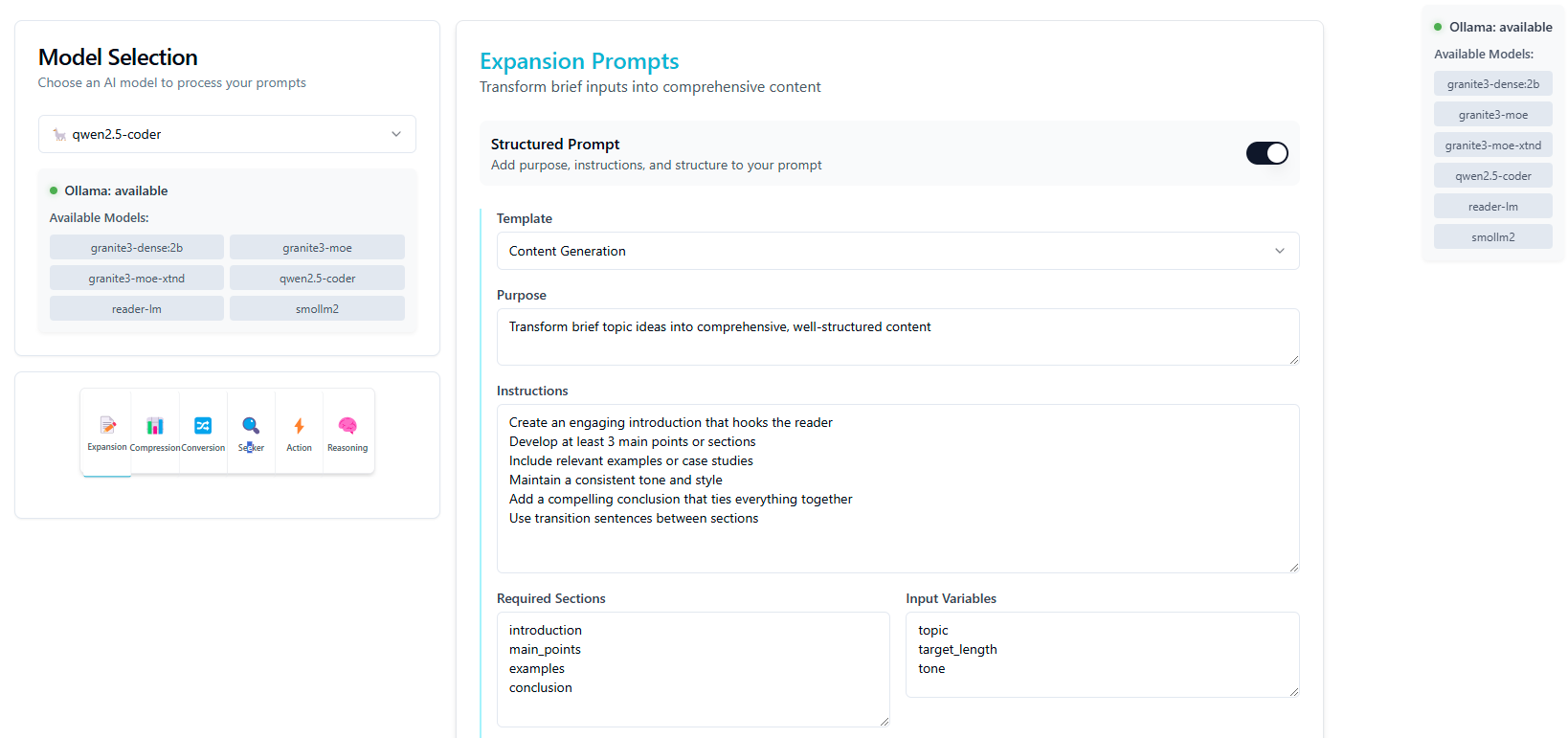
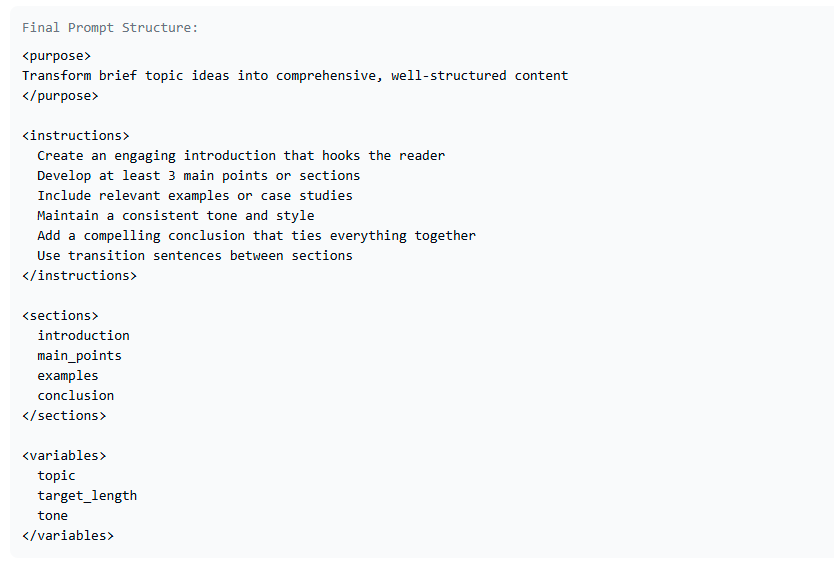
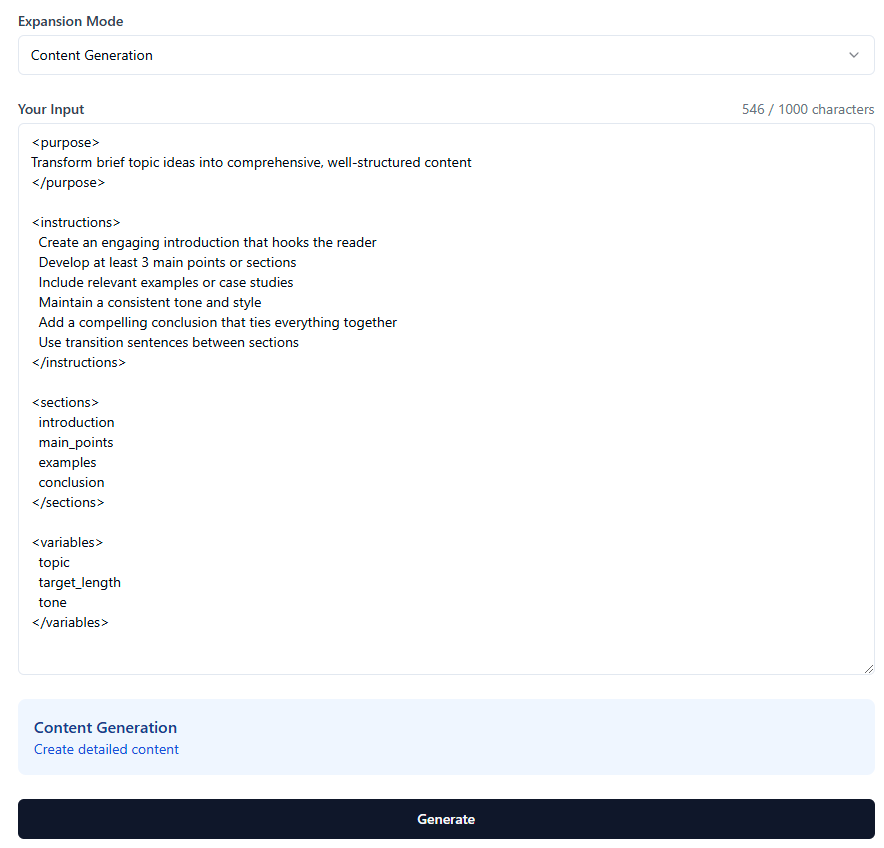
I made a web app to try and illustrate this concept…sorry if it makes zero sense ![]() the repo is on my [github] (https://github.com/dsmflow/expand-o-matic/)
the repo is on my [github] (https://github.com/dsmflow/expand-o-matic/)
I got it working with Ollama locally, using the pydantic.ai “agent” masterclass from @ColeMedin. I did not setup anything for the cloud LLMs for now, but they are staged.
The order of the dropdowns is a bit out of sync and I only have a template for the first “category” of Expansion prompt. Toggle on structured prompt and half way down select the “Content Generation” option, then back up near the top of the page the “template” should be selectable. I got the category ideas from @IndyDevDan on YT.
I think coupled with --verbose mode in Ollama you get the token output values.

Link shows me 404
Sadly I did not understood what you were trying to achieve and how with this from reading.
May be try to discuss this with AI until you think it understands you and then ask it to make some kind of summary? Just and idea, I hope it does not insult you.
i recently made a post for a way to deal w/ context length / reduce token count:
Whoops, it wasn’t public. Hehe no offense, it’s really just a mirror of how chaotic my process is when I try something on the fly ![]()
I wasn’t sure how else to really visualize and validate how many tokens the various styles of structuring data offered.
I’m certain there’s an easier way, I just have trouble wrapping my head around the conventional way of doing stuff without trying my own weird way first.