Trying to add llama 3.3 70B with my API keys from Together.ai or Deepinfra (cheaper) and I am unclear how to proceed. The bolt.diy readme says to refer to the youtube video for new llms but I can’t find it. Can anyone provide a step by step process how to implement. thank you in advance!
you need to rename .env.example to .env (or .env.local)
and then edit it with notepad.
in OPENAI_LIKE_API_BASE_URL=
you need to add url from deepinfra or another provider, for example:
OPENAI_LIKE_API_BASE_URL=https://api.deepinfra.com/v1/openai
and in OPENAI_LIKE_API_KEY=
you need to put your API key from deepinfra
2 Likes
The Models you can use with together.ai though are hardcoded within the bolt-code within “app/utils/constants.ts”
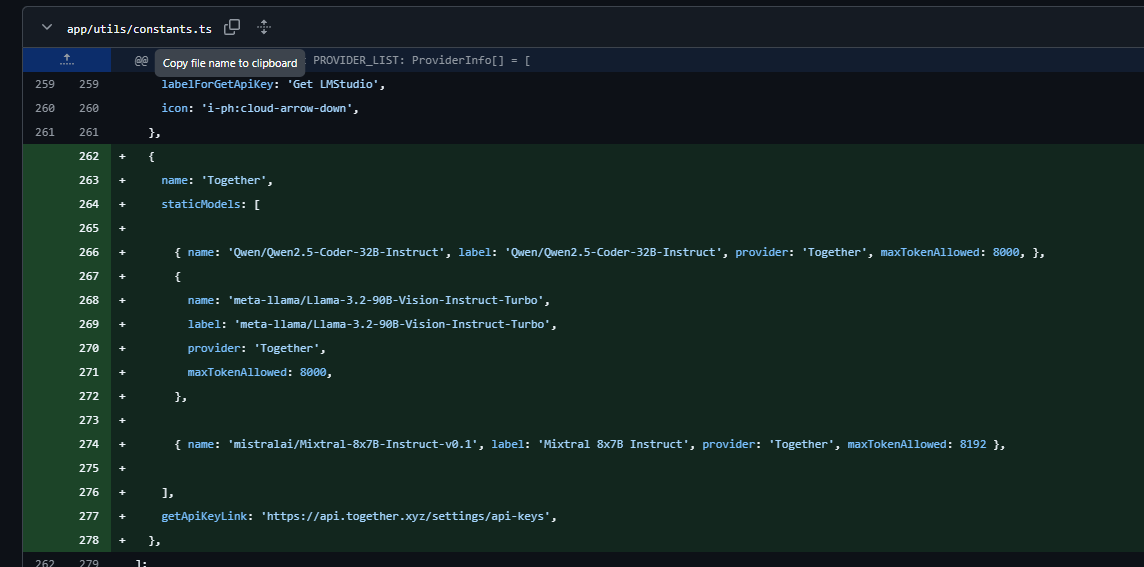
So you would need to change the constant.ts and add your model (unless someone correct me and I got it wrong ![]() )
)
actually dynamic model loading works for togatherai…
i guess this is an older file,
here is what the current one looks like
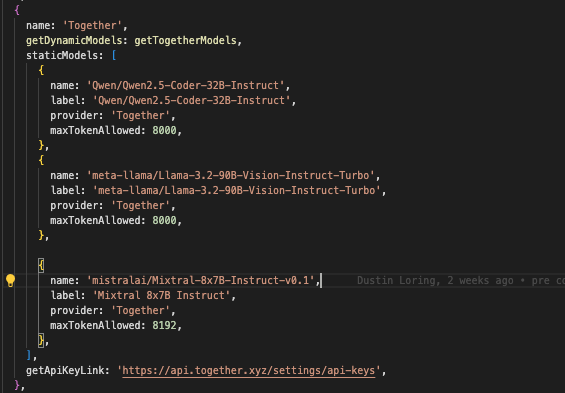
not sure stable branch has this or not
@thecodacus thanks for clarification.
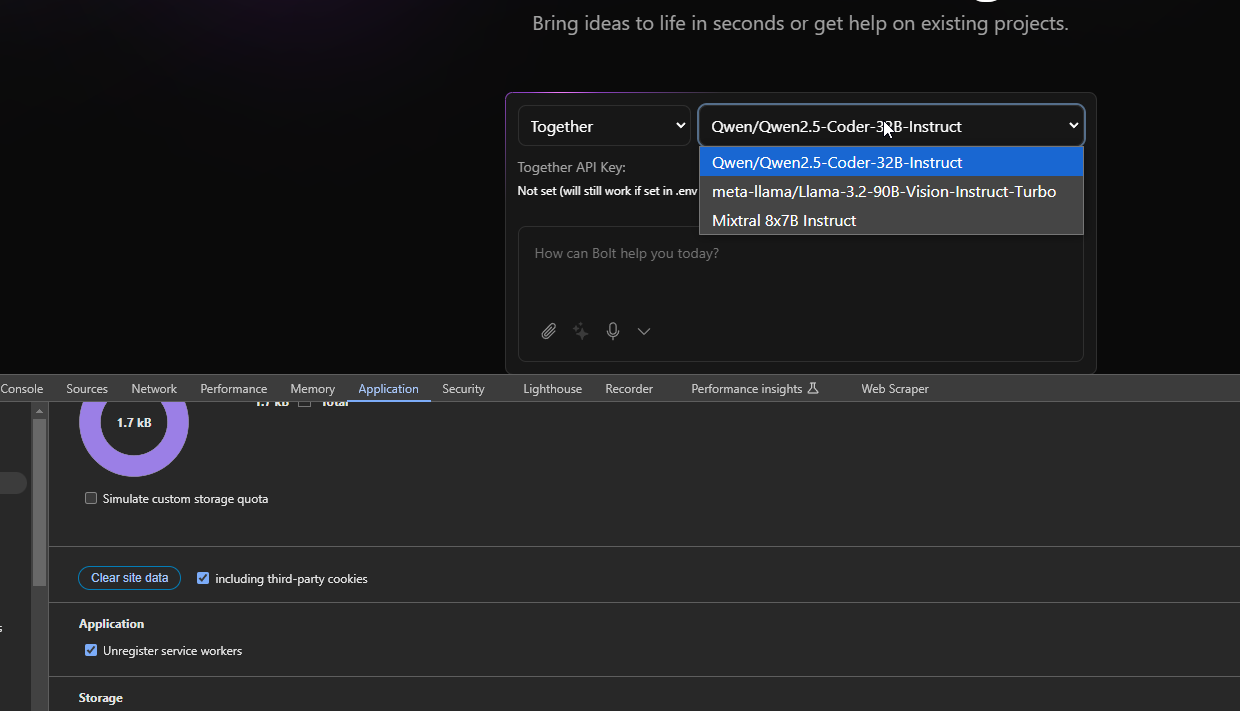
Can you also tell how to configure more Models that also show then over the API, because I registered and only get 3 models and I dont see an option in the TogetherAI-UI to add more, or do I need to be on Tier 1 for this (Add credit card)?
try putting the api key in the ui and refresh the page, was able to see more models when I added the dynamic models option… not sure if its still working
edit: just checked its working for me (didn’t add any cc FYI)
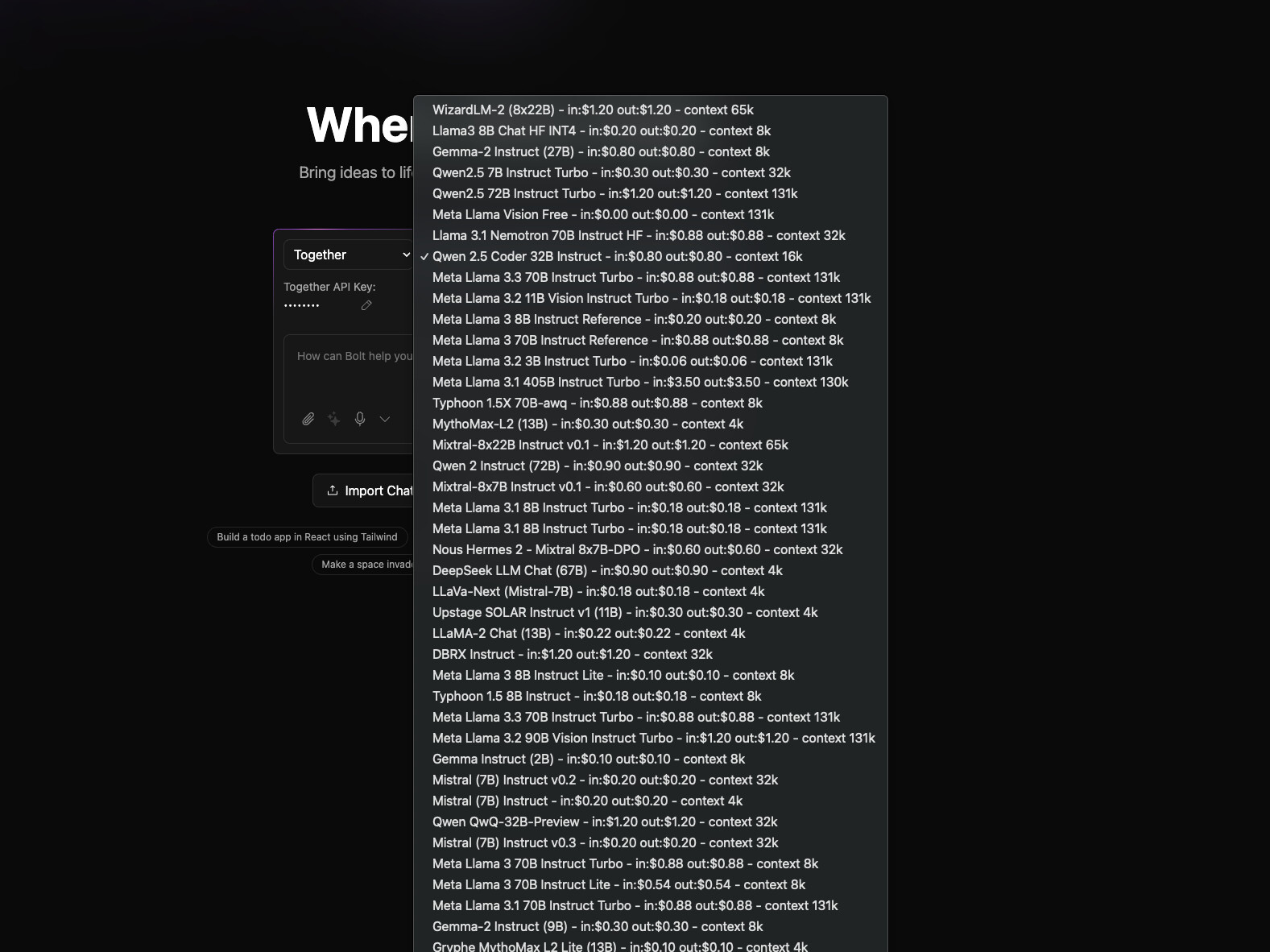
Ok, dont know whats wrong here then for me.
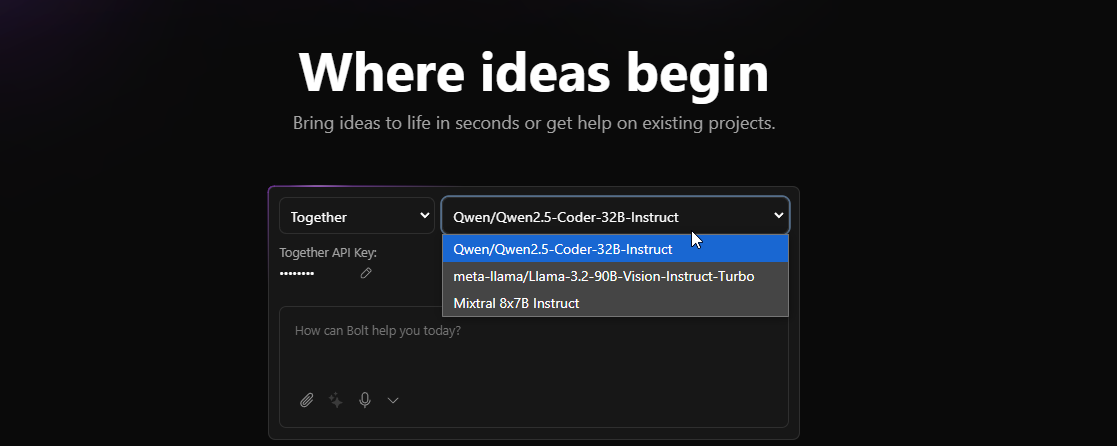
- I am on the latest main branch (just pulled).
- API inserted within the UI
- Refreshed the page
- Still just these 3 LLMs
What do you mean with “added the dynamic models option”
=> where is this option?
its in the constants file…
can you go to the settings tab and enable debug tab and share the details its showing there ?
Here you go:
{
"System": {
"os": "Windows",
"browser": "Chrome 131.0.0.0",
"screen": "1920x1080",
"language": "en-US",
"timezone": "Europe/Berlin",
"memory": "4 GB (Used: 80.13 MB)",
"cores": 16,
"deviceType": "Desktop",
"colorDepth": "24-bit",
"pixelRatio": 1,
"online": true,
"cookiesEnabled": true,
"doNotTrack": true
},
"Providers": [],
"Version": {
"hash": "1e72d52",
"branch": "main"
},
"Timestamp": "2024-12-16T22:27:37.397Z"
}
can you raise an issue in gh if not already raised… will look into this
ok, done: Together AI not showing all models available · Issue #782 · stackblitz-labs/bolt.diy · GitHub
thanks
1 Like
Thank you! Same issue for me ie can’t see list of together llm after entering key. I even tried addind Llama 3.3 70b in the constant file and still can only choose from the default 3 together llms.
Please also consider adding Deepinfra as they seem pretty much the lowest cost option outside of self host.

Thanks, but did not change anything for me.
Steps I did:
git fetch origin pull/816/head:pr-816
git checkout pr-816
pnpm install
pnpm run dev
Browser => Clear Site Data (Dev-Tools=>Applications)
Refresh
thank you. will run it tonight and let you know. Have a great day and thanks again.
1 Like
ahh for dynamic models what requires api to load models like “Togather.ai” you have to place the apikey in the UI…
ui cannot access apikeys from env files, only servers can
This doesnt change anything ![]() Still not working.
Still not working.
ok will try removing together AI API key from the .env.local file and only add the API key to the ui (not settings either). Will see if that works. Thanks
True, but you could parse their Serverless models page:
const axios = require('axios');
const fs = require('fs');
// URL for the TogetherAI model documentation page
const url = 'https://docs.together.ai/docs/serverless-models';
const modelRegex = /[\|]\s*(\S[\w\s\-\.]*)\s*\|\s*(\S[\w\s\-\.]*)\s*\|\s*(\S[\w\s\-\.\/\-]*)\s*\|\s*(\d+)\s*\|\s*(FP8|FP16)/g;
async function fetchAndParseModels() {
try {
const { data } = await axios.get(url);
// Match all model rows using the regex
let models = [];
let match;
while ((match = modelRegex.exec(data)) !== null) {
models.push({
organization: match[1].trim(),
modelName: match[2].trim(),
apiModelString: match[3].trim(),
contextLength: parseInt(match[4], 10),
quantization: match[5].trim(),
});
}
// Save the results to a JSON file
fs.writeFileSync('modelsData.json', JSON.stringify(models, null, 2));
console.log('Models data saved to modelsData.json');
} catch (error) {
console.error('Error fetching or parsing data:', error);
}
}
fetchAndParseModels();
36 Results:
[
{
"organization": "Meta",
"modelName": "Llama 3.3 70B Instruct Turbo",
"apiModelString": "meta-llama/Llama-3.3-70B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 8B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 70B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 405B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo",
"contextLength": 130815,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3 8B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3-8B-Instruct-Turbo",
"contextLength": 8192,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3 70B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3-70B-Instruct-Turbo",
"contextLength": 8192,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.2 3B Instruct Turbo",
"apiModelString": "meta-llama/Llama-3.2-3B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP16"
},
{
"organization": "Meta",
"modelName": "Llama 3 8B Instruct Reference",
"apiModelString": "meta-llama/Llama-3-8b-chat-hf",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Meta",
"modelName": "Llama 3 70B Instruct Reference",
"apiModelString": "meta-llama/Llama-3-70b-chat-hf",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Nvidia",
"modelName": "Llama 3.1 Nemotron 70B",
"apiModelString": "nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 Coder 32B Instruct",
"apiModelString": "Qwen/Qwen2.5-Coder-32B-Instruct",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "QwQ-32B-Preview",
"apiModelString": "Qwen/QwQ-32B-Preview",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Microsoft",
"modelName": "WizardLM-2 8x22B",
"apiModelString": "microsoft/WizardLM-2-8x22B",
"contextLength": 65536,
"quantization": "FP16"
},
{
"organization": "Google",
"modelName": "Gemma 2 27B",
"apiModelString": "google/gemma-2-27b-it",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Google",
"modelName": "Gemma 2 9B",
"apiModelString": "google/gemma-2-9b-it",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "databricks",
"modelName": "DBRX Instruct",
"apiModelString": "databricks/dbrx-instruct",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 7B Instruct Turbo",
"apiModelString": "Qwen/Qwen2.5-7B-Instruct-Turbo",
"contextLength": 32768,
"quantization": "FP8"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 72B Instruct Turbo",
"apiModelString": "Qwen/Qwen2.5-72B-Instruct-Turbo",
"contextLength": 32768,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.3 70B Instruct Turbo",
"apiModelString": "meta-llama/Llama-3.3-70B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 8B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 70B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-70B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.1 405B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3.1-405B-Instruct-Turbo",
"contextLength": 130815,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3 8B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3-8B-Instruct-Turbo",
"contextLength": 8192,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3 70B Instruct Turbo",
"apiModelString": "meta-llama/Meta-Llama-3-70B-Instruct-Turbo",
"contextLength": 8192,
"quantization": "FP8"
},
{
"organization": "Meta",
"modelName": "Llama 3.2 3B Instruct Turbo",
"apiModelString": "meta-llama/Llama-3.2-3B-Instruct-Turbo",
"contextLength": 131072,
"quantization": "FP16"
},
{
"organization": "Meta",
"modelName": "Llama 3 8B Instruct Reference",
"apiModelString": "meta-llama/Llama-3-8b-chat-hf",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Meta",
"modelName": "Llama 3 70B Instruct Reference",
"apiModelString": "meta-llama/Llama-3-70b-chat-hf",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Nvidia",
"modelName": "Llama 3.1 Nemotron 70B",
"apiModelString": "nvidia/Llama-3.1-Nemotron-70B-Instruct-HF",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 Coder 32B Instruct",
"apiModelString": "Qwen/Qwen2.5-Coder-32B-Instruct",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "QwQ-32B-Preview",
"apiModelString": "Qwen/QwQ-32B-Preview",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Microsoft",
"modelName": "WizardLM-2 8x22B",
"apiModelString": "microsoft/WizardLM-2-8x22B",
"contextLength": 65536,
"quantization": "FP16"
},
{
"organization": "Google",
"modelName": "Gemma 2 27B",
"apiModelString": "google/gemma-2-27b-it",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "Google",
"modelName": "Gemma 2 9B",
"apiModelString": "google/gemma-2-9b-it",
"contextLength": 8192,
"quantization": "FP16"
},
{
"organization": "databricks",
"modelName": "DBRX Instruct",
"apiModelString": "databricks/dbrx-instruct",
"contextLength": 32768,
"quantization": "FP16"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 7B Instruct Turbo",
"apiModelString": "Qwen/Qwen2.5-7B-Instruct-Turbo",
"contextLength": 32768,
"quantization": "FP8"
},
{
"organization": "Qwen",
"modelName": "Qwen 2.5 72B Instruct Turbo",
"apiModelString": "Qwen/Qwen2.5-72B-Instruct-Turbo",
"contextLength": 32768,
"quantization": "FP8"
}
]
For Deepinfra using Openrouter (could use them directly or through Openrouter):
const axios = require('axios');
const cheerio = require('cheerio');
const fs = require('fs');
async function fetchAndParseWebsite() {
try {
const url = 'https://openrouter.ai/provider/deepinfra';
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const models = [];
$('.flex.w-full.items-center.justify-between.group.py-4.flex-col.md\\:flex-row.gap-3').each((index, element) => {
const container = $(element);
// Extracts attribute from the HTML
const href = container.find('a').attr('href');
const modelName = href ? href.split('/').pop() : '';
const organization = container.find('.text-inherit.underline.hover\\:text-muted-foreground').text().trim();
const contextLength = container.find('span:contains("context")').text().replace(' context', '').trim();
const inputTokenCost = container.find('span:contains("input")').text().replace(' input tokens', '').trim();
const outputTokenCost = container.find('span:contains("output")').text().replace(' output tokens', '').trim();
// Add the parsed data to the models array
models.push({
organization,
modelName,
contextLength,
inputTokenCost,
outputTokenCost,
});
});
// Save the parsed data to a JSON file
const outputFile = 'deepinfra_models.json';
fs.writeFileSync(outputFile, JSON.stringify(models, null, 2));
console.log(`Successfully parsed data saved to ${outputFile}`);
} catch (error) {
console.error('Error fetching or parsing data:', error.message);
}
}
fetchAndParseWebsite();
29 Results:
[
{
"organization": "google",
"modelName": "gemma-2-9b-it",
"contextLength": "8K",
"inputTokenCost": "$0.03/M",
"outputTokenCost": "$0.06/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.1-70b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.13/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "mistralai",
"modelName": "mistral-nemo",
"contextLength": "128K",
"inputTokenCost": "$0.04/M",
"outputTokenCost": "$0.1/M"
},
{
"organization": "sao10k",
"modelName": "l3-euryale-70b",
"contextLength": "8K",
"inputTokenCost": "$0.35/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "nousresearch",
"modelName": "hermes-3-llama-3.1-405b",
"contextLength": "131K",
"inputTokenCost": "$0.9/M",
"outputTokenCost": "$0.9/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.3-70b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.13/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "openchat",
"modelName": "openchat-7b",
"contextLength": "8K",
"inputTokenCost": "$0.055/M",
"outputTokenCost": "$0.055/M"
},
{
"organization": "microsoft",
"modelName": "wizardlm-2-7b",
"contextLength": "32K",
"inputTokenCost": "$0.055/M",
"outputTokenCost": "$0.055/M"
},
{
"organization": "mistralai",
"modelName": "mistral-7b-instruct",
"contextLength": "33K",
"inputTokenCost": "$0.03/M",
"outputTokenCost": "$0.055/M"
},
{
"organization": "qwen",
"modelName": "qwen-2.5-72b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.23/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.2-90b-vision-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.35/M$0.5058/K input imgs",
"outputTokenCost": "$0.4/M"
},
{
"organization": "sao10k",
"modelName": "l3-lunaris-8b",
"contextLength": "8K",
"inputTokenCost": "$0.03/M",
"outputTokenCost": "$0.06/M"
},
{
"organization": "mistralai",
"modelName": "mixtral-8x7b-instruct",
"contextLength": "33K",
"inputTokenCost": "$0.24/M",
"outputTokenCost": "$0.24/M"
},
{
"organization": "sao10k",
"modelName": "l3.1-euryale-70b",
"contextLength": "8K",
"inputTokenCost": "$0.35/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "lizpreciatior",
"modelName": "lzlv-70b-fp16-hf",
"contextLength": "4K",
"inputTokenCost": "$0.35/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.1-405b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.9/M",
"outputTokenCost": "$0.9/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.2-1b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.01/M",
"outputTokenCost": "$0.02/M"
},
{
"organization": "gryphe",
"modelName": "mythomax-l2-13b",
"contextLength": "4K",
"inputTokenCost": "$0.08/M",
"outputTokenCost": "$0.08/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.1-8b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.02/M",
"outputTokenCost": "$0.05/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3-8b-instruct",
"contextLength": "8K",
"inputTokenCost": "$0.03/M",
"outputTokenCost": "$0.06/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.2-3b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.018/M",
"outputTokenCost": "$0.03/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3.2-11b-vision-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.055/M$0.07948/K input imgs",
"outputTokenCost": "$0.055/M"
},
{
"organization": "mistralai",
"modelName": "mistral-7b-instruct-v0.3",
"contextLength": "33K",
"inputTokenCost": "$0.03/M",
"outputTokenCost": "$0.055/M"
},
{
"organization": "nvidia",
"modelName": "llama-3.1-nemotron-70b-instruct",
"contextLength": "131K",
"inputTokenCost": "$0.23/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "microsoft",
"modelName": "wizardlm-2-8x22b",
"contextLength": "66K",
"inputTokenCost": "$0.5/M",
"outputTokenCost": "$0.5/M"
},
{
"organization": "meta-llama",
"modelName": "llama-3-70b-instruct",
"contextLength": "8K",
"inputTokenCost": "$0.23/M",
"outputTokenCost": "$0.4/M"
},
{
"organization": "google",
"modelName": "gemma-2-27b-it",
"contextLength": "8K",
"inputTokenCost": "$0.27/M",
"outputTokenCost": "$0.27/M"
},
{
"organization": "qwen",
"modelName": "qwen-2.5-coder-32b-instruct",
"contextLength": "128K",
"inputTokenCost": "$0.08/M",
"outputTokenCost": "$0.18/M"
},
{
"organization": "qwen",
"modelName": "qwq-32b-preview",
"contextLength": "33K",
"inputTokenCost": "$0.15/M",
"outputTokenCost": "$0.6/M"
}
]
Or use Models | Deep Infra and parse pages 1-7 (109 models currently).
But worth noting, they are actually cheaper through Openrouter. However, Openrouter does charge a processing fee, so it depends. Not sure about Deepinfra directly. So, if you strictly pay as you go, then Deepinfra direct is likely better but if you pay in bulk (say rotating $100 or something) then Openrouter is probably better.
1 Like