(≈10min)
Wisdom of 8 LLM Agents
The scent of trampled hay mingles with the earthy musk of livestock, the crisp bite of cold air settling over the crowd. In 1906, at the West of England Fat Stock and Poultry Exhibition in Plymouth, England, Sir Francis Galton observed a competition in which attendees guessed the weight of an ox ![]() .
.
Nearly 800 people—exhibitors, traders, farmers—submitted estimates on slips of paper. Galton calculated the average of all guesses and discovered something remarkable: distributed intelligence. The collective estimate was 1,197 pounds, one pound shy of the ox’s true weight.
This phenomenon is called the Wisdom of Crowds, the idea that independent contributions, when aggregated, can outperform expert assessments. Rather than pursuing uniform agreement, the strength of this approach lies in the variety of perspectives—each adding unique insights that refine the overall judgment. The same principle underlies the agentic system proposed in this paper, where distinct LLM personas—each representing a specialized viewpoint—converge.
Just as Galton’s livestock crowd unknowingly simulated a distributed intelligence model, the AI agents outlined in this paper mirror the interdisciplinary reasoning of human engineering teams, harnessing structured collaboration to refine complex problem-solving.
Harnessing Multi-Agent LLMs for Complex Engineering Problem-Solving: A Framework for Senior Design Projects
Key Takeaways
Multi-Agent LLMs provide a structured and adaptive evaluation framework, surpassing single-agent systems by offering expert-style feedback that mirrors real-world engineering collaboration.
By integrating diverse expert perspectives, multi-agent LLM systems enhance
student learning, bridging the gap between theoretical education and industry expectations.
Setting 
The power of distributed intelligence, as demonstrated in Galton’s observation, is also fundamental to senior design projects (SDP), where engineering students must synthesize diverse perspectives to address real-world challenges that balance technical, ethical, and regulatory constraints. Structured frameworks help break down these challenges, encouraging diverse perspectives to refine solutions.
By mirroring these dynamics, Multi-Agent Systems (MAS) offer a structured approach to evaluating student problem-solving, integrating specialized viewpoints to refine engineering proposals and enhance decision-making.
The proposed MAS assigns eight specialized Large Language Model (LLM) agents to distinct roles to replicate expert collaboration. Each agent operates independently, yet together, they provide structured SDP evaluations that assess technical feasibility and broader societal impacts. This system fosters interdisciplinary collaboration, encouraging students to refine their critical thinking skills in response to expert-style feedback.
The MAS provides a structured feedback mechanism that helps students navigate real-world problem-solving challenges by embedding evaluative considerations into engineering education.
8 LLM Agents 
Each agent is responsible for a specific aspect of SDP evaluation, functioning as a domain specialist. By adopting role-specific personas, these agents simulate expert reasoning, ensuring that different dimensions of the project are thoroughly addressed. Table 1 outlines the roles and responsibilities of the eight specialized LLM agents in the MAS.
| Agents | Tasks |
|---|---|
| A.1 Problem Formulation | Ensures the problem is clearly defined and appropriately complex |
| A.2 Breadth and Depth | Confirms the project moves beyond simple tasks and requires deep engineering expertise |
| A.3 Ambiguity and Uncertainty | Identifies areas of uncertainty and assesses the need for assumptions or estimates |
| A.4 System Complexity | Evaluates if the project incorporates advanced methods or new technology |
| A.5 Technical Innovation and Risk Management | Determines if the project introduces novel ideas while addressing potential risks |
| A.6 Societal and Ethical Consideration | Checks that the project considers its broader impact and ethical responsibilities |
| A.7 Methodology and Approach | Ensures the chosen methodology effectively addresses complex engineering challenges using appropriate analytic tools |
| A.8 Comprehensive Evaluation | Provides an overall assessment of the project’s formulation, analysis, and methodology |
Table 1. Agent Roles
Multi-Agent System Workflow 
The MAS operates through a structured workflow that ensures coordination, efficiency, and quality control. At its core, the Coordinator Agent ♔ manages task execution and oversees collaboration. ⥬ Working alongside it, the Tasks Agent ♕ breaks each SDP into precise, manageable components, ensuring tasks are well-defined before distribution. Fig. 1 illustrates the MAS workflow.
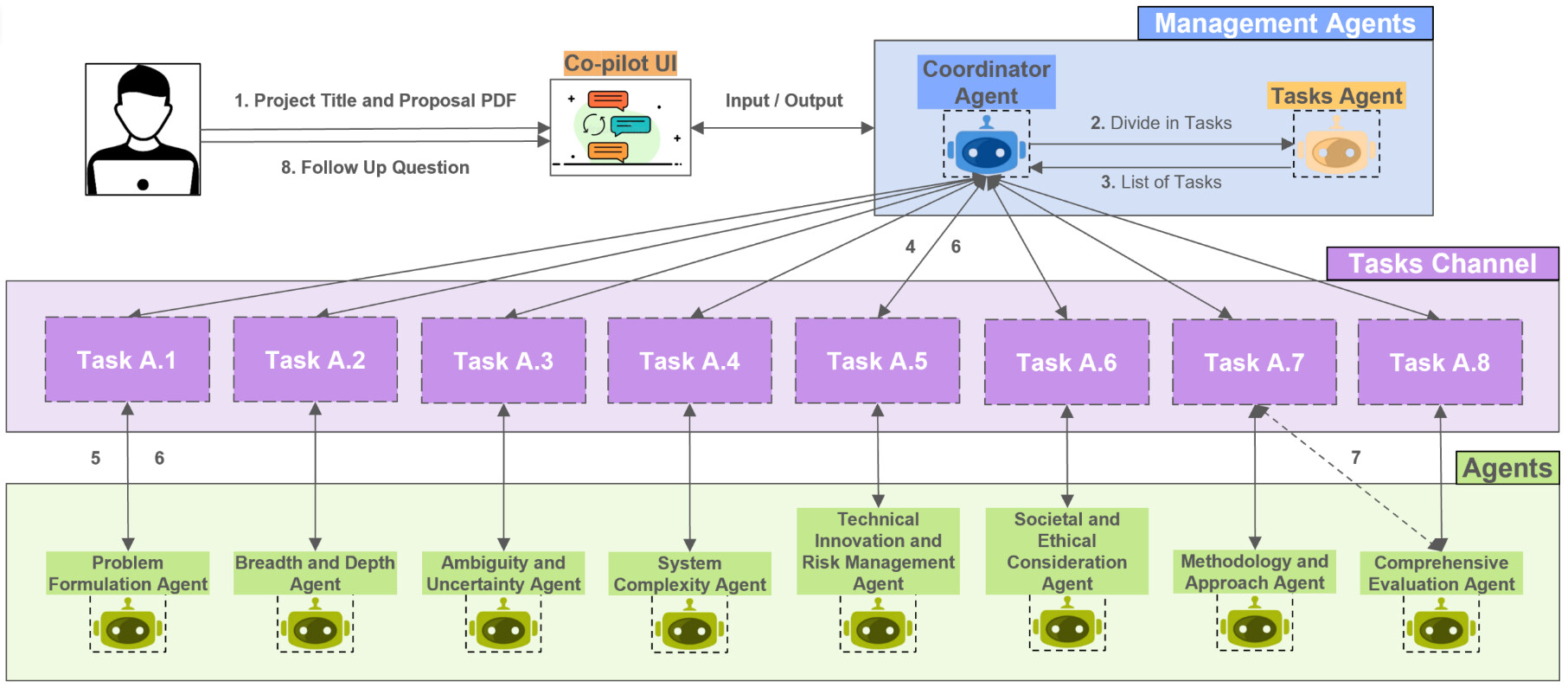
Fig. 1. Multi-Agent Workflow Overview
⥬ Tasks are assigned through Camel AI’s Tasks Channel, a system designed to streamline allocation and monitoring. Once assigned, the eight agents ♙ process their tasks sequentially, applying their domain-specific expertise. ⇌ As they complete their work, outputs are routed back through the Tasks Channel, where the Coordinator Agent evaluates results against predefined standards.
⇌ The Coordinator Agent dynamically routes outputs between agents when needed, ensuring that one agent’s analysis informs another’s work. Each agent functions as a Critic Agent, providing constructive feedback and refining decision-making. ╞ To enhance accuracy, agents leverage tools such as Camel AI’s Internet Search Toolkit and Mathematics Toolkit, equipping them with the necessary resources for well-rounded responses.
⥓ Once all tasks are complete, the Coordinator Agent synthesizes the outputs into a final deliverable, ensuring coherence and alignment with project objectives. This structured yet flexible system mirrors real-world engineering collaboration, fostering an adaptive and rigorous approach to complex problem-solving.
RESULTS
Evaluation Methodology & Alignment with Faculty Scores 
The Faculty Evaluation Score serves as the benchmark for assessing project quality. The MAS consistently outperforms the Single Agent (SA) approach in aligning with faculty evaluations. Notably, MAS reduces variability, enhances structured evaluation, and provides expert-style feedback across multiple assessment criteria. Table 2 illustrates the comparative evaluation accuracy between the MAS and the SA System.
| Multi-Agent System Score | Single Agent Score |
|---|---|
| Generated by multiple specialized agents, each evaluating a specific criterion (e.g., problem formulation, system complexity, ethical considerations). | Generated by a SA using Tree of Thoughts (TOT) to simulate multiple expert evaluations within a single response. |
| More closely aligned with faculty evaluations, particularly in technical depth and ethical considerations. | Shows higher error rates, often oversimplifying responses. |
| Excels in structured, systematic evaluation, offering more comprehensive and reliable feedback. | Struggles with capturing interdisciplinary depth and nuanced feedback. |
| 89% more accurate than single-agent evaluations when compared to faculty scores. | Less aligned with faculty scores, higher deviation in evaluation accuracy. |
| Mean Absolute Error (MAE): 0.205, closely matching faculty scores. | Mean Absolute Error (MAE): 0.388, showing a greater deviation. |
| Provides standardized evaluations, reducing variability seen in human assessments. | Inconsistent evaluations across different projects, lacking stability in scoring. |
Table 2. Comparative Evaluation Accuracy
Performance in Specific Evaluation Areas 
When assessing specific engineering and computing aspects, MAS consistently demonstrates superior accuracy across most criteria. However, the SA System (SA) performs slightly better in the Breadth and Depth category, suggesting that a unified evaluation approach may be preferable in this area. That said, MAS excels in technical evaluations, ambiguity detection, and ethical considerations, making it the more reliable tool for assessing complex project proposals. Table 3 presents the performance comparison of MAS and SA Systems across key engineering evaluation criteria.
| Multi-Agent System Score | Single Agent Score |
|---|---|
| Highly effective in technical categories such as Technical Innovation and Risk Management (MAE 0.345 vs. SA 0.855) and System Complexity (MAE 0.272 vs. SA 0.355). | Performs better than MAS in Breadth and Depth (MAE 0.208 vs. MAS 0.292), suggesting some aspects may favor a unified evaluation approach. |
| MAS outperforms SA in ambiguity detection (MAE 0.440 vs. SA 0.857) and societal/ethical considerations (MAE 0.355 vs. SA 0.772). | Struggles with ambiguity and ethical considerations, performing significantly worse than MAS. |
| MAS enables more structured, iterative refinement, providing expert-style critiques across multiple domains. | Struggles with depth in feedback, making it less effective in guiding improvements. |
| Stronger thematic consistency and lexical cohesion, aligning closely with faculty scoring trends. | More fragmented responses, weaker cohesion compared to MAS. |
Table 3. Comparative Performance Across Evaluation Criteria
Scalability, Efficiency, and Practical Application 
A major advantage of MAS is its scalability and efficiency. While faculty evaluations remain the gold standard, they are labor-intensive and subject to variability. The SA approach is faster but lacks depth, whereas MAS provides both efficiency and structured assessment, making it the optimal tool for large-scale evaluation. Table 4 compares the scalability and efficiency of MAS and SA Systems for project evaluation.
| Multi-Agent System Score | Single Agent Score |
|---|---|
| Automates structured evaluation, improving consistency while maintaining faculty-like scoring trends. | Attempts to simulate multi-agent reasoning but lacks the depth and structured collaboration of MAS. |
| Highly scalable—capable of evaluating large numbers of projects efficiently. | Scalable but less reliable, lacking the robustness of MAS evaluations. |
| Speeds up evaluation, reduces faculty workload, making feedback more accessible. | Faster than faculty evaluations, but not as structured or efficient as MAS. |
| MAS provides real-time, structured feedback, supporting rapid iteration in the student design process. | Responses can be generic and lacking in actionable depth, limiting their usefulness. |
Table 4. Comparative Scalability and Efficiency
The comparison highlights the clear advantages of MAS over SA systems, especially in alignment with faculty evaluations, structured assessment, and scalability. However, faculty evaluations remain the most authoritative and nuanced, making MAS an optimal tool for supporting, rather than replacing, expert assessments.
MODEL IMPROVEMENTS 
The study outlines several ways to enhance the MAS framework for improved performance in SDP evaluations:
-
Improved Agent Coordination 🫱🏻🫲🏽: Enhancing collaboration and negotiation between agents would allow them to exchange insights dynamically rather than relying solely on predefined roles.
-
Integration with External Tools
 : Current MAS evaluations depend on LLM-based reasoning. Future versions could integrate specialized engineering software and databases for more data-driven assessments.
: Current MAS evaluations depend on LLM-based reasoning. Future versions could integrate specialized engineering software and databases for more data-driven assessments. -
Advanced Prompting & Iterative Reasoning
 : Incorporating recursive prompting techniques and meta-reasoning would enhance response refinement, reducing inconsistencies across agent outputs.
: Incorporating recursive prompting techniques and meta-reasoning would enhance response refinement, reducing inconsistencies across agent outputs. -
Expanded Evaluation Metrics
 : Introducing domain-specific scoring methods, such as technical feasibility and regulatory compliance metrics, could improve MAS alignment with real-world engineering standards.
: Introducing domain-specific scoring methods, such as technical feasibility and regulatory compliance metrics, could improve MAS alignment with real-world engineering standards. -
Addressing Breadth & Depth Limitations
 : While MAS excels in most aspects, the SA System outperforms it in Breadth & Depth. A hybrid model incorporating both structured feedback (MAS) and holistic evaluation (SA System) may be beneficial.
: While MAS excels in most aspects, the SA System outperforms it in Breadth & Depth. A hybrid model incorporating both structured feedback (MAS) and holistic evaluation (SA System) may be beneficial. -
Increased System Autonomy
 : Reducing reliance on manual task structuring by the Coordinator Agent and allowing agents to self-organize and refine tasks in real-time would enhance system adaptability.
: Reducing reliance on manual task structuring by the Coordinator Agent and allowing agents to self-organize and refine tasks in real-time would enhance system adaptability.
The MAS framework demonstrates a promising approach to structured, expert-style evaluation in engineering education. By integrating specialized LLM agents, MAS enhances assessment accuracy, reduces variability, and provides scalable feedback that aligns closely with faculty evaluations. While challenges remain—such as optimizing inter-agent coordination and refining evaluation depth—future enhancements in adaptive reasoning, tool integration, and autonomy will further elevate MAS as a robust solution for complex problem-solving in senior design projects.
@Luke ![]()
PAPERstreams
Resources
CMX. (2016). James Surowiecki: The Power of the Collective. YouTube. https://www.youtube.com/watch?v=pTI6u_gbilY
Mushtaq, A., Naeem, M. R., Ghaznavi, I., Taj, M. I., Hashmi, I., & Qadir, J. (2025). Harnessing Multi-Agent LLMs for Complex Engineering Problem-Solving: A Framework for Senior Design Projects. arXiv preprint arXiv:2501.01205. (Reviewed Article)
O’Connor, J., & Robertson, E. (2003). Francis Galton - Biography. Maths History. Francis Galton (1822 - 1911) - Biography - MacTutor History of Mathematics
Index.
- Distributed Intelligence: A system in which knowledge, decision-making, or
computation is spread across multiple agents, networks, or nodes rather than
centralized in one entity.
- Large Language Model (LLM): A neural network trained on vast amounts of text
data, designed to process, generate, and understand human language. LLMs use
probabilistic methods to predict and construct text.
- Multi-Agent System (MAS): A computational framework where multiple autonomous
agents interact, collaborate, or compete to solve complex tasks. Agents operate
independently but share goals, information, or roles, allowing for emergent
behavior and distributed problem-solving.
Wisdom of 8 LLM Agents by Luke T Ingersoll is marked with CC0 1.0 Universal ![]()
![]()