Hi @ColeMedin , thanks so much for what you’ve thrown together!
Yes! I wanted to take a bit of time to get my thoughts together as I got a bit ahead of myself it seems haha!
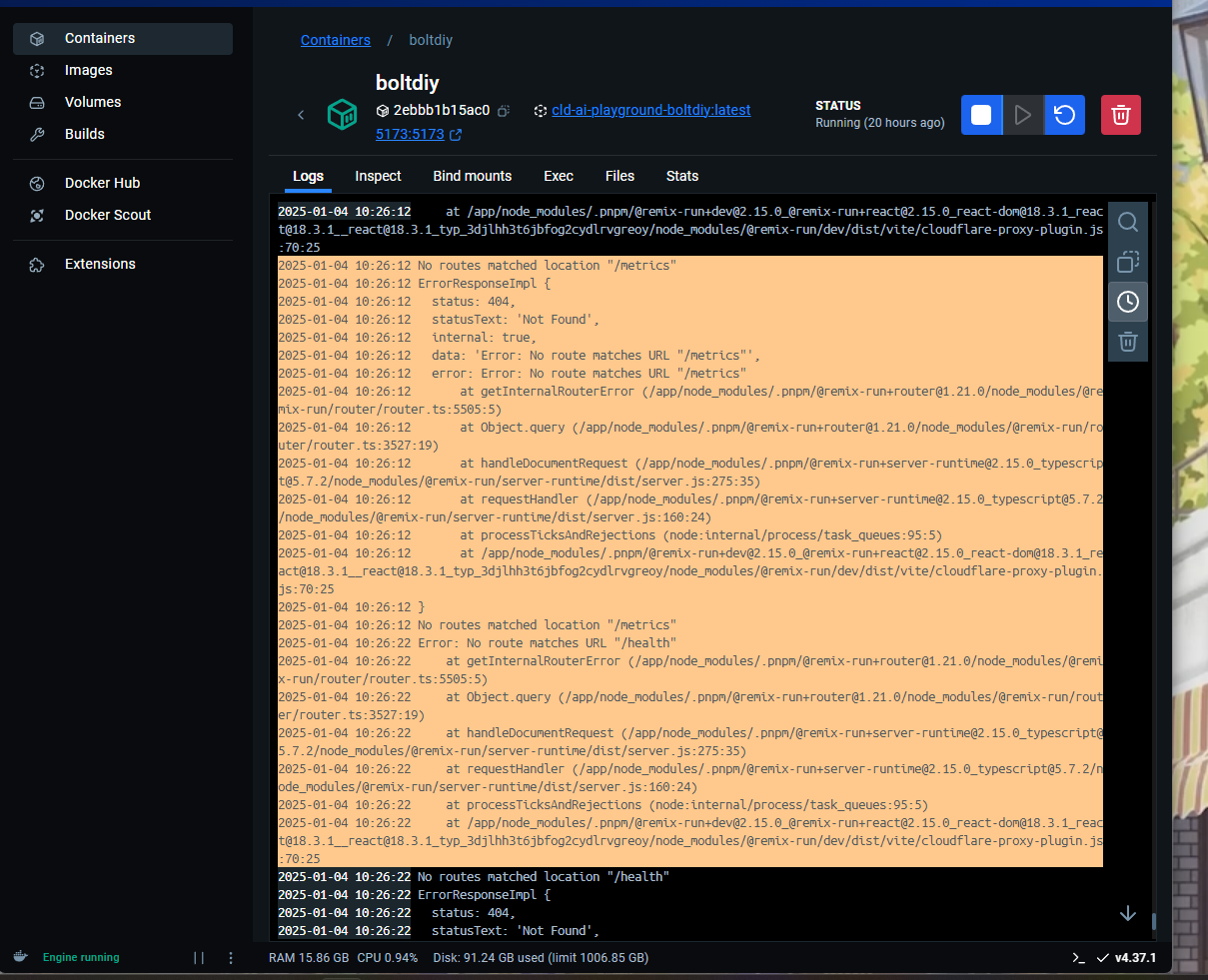
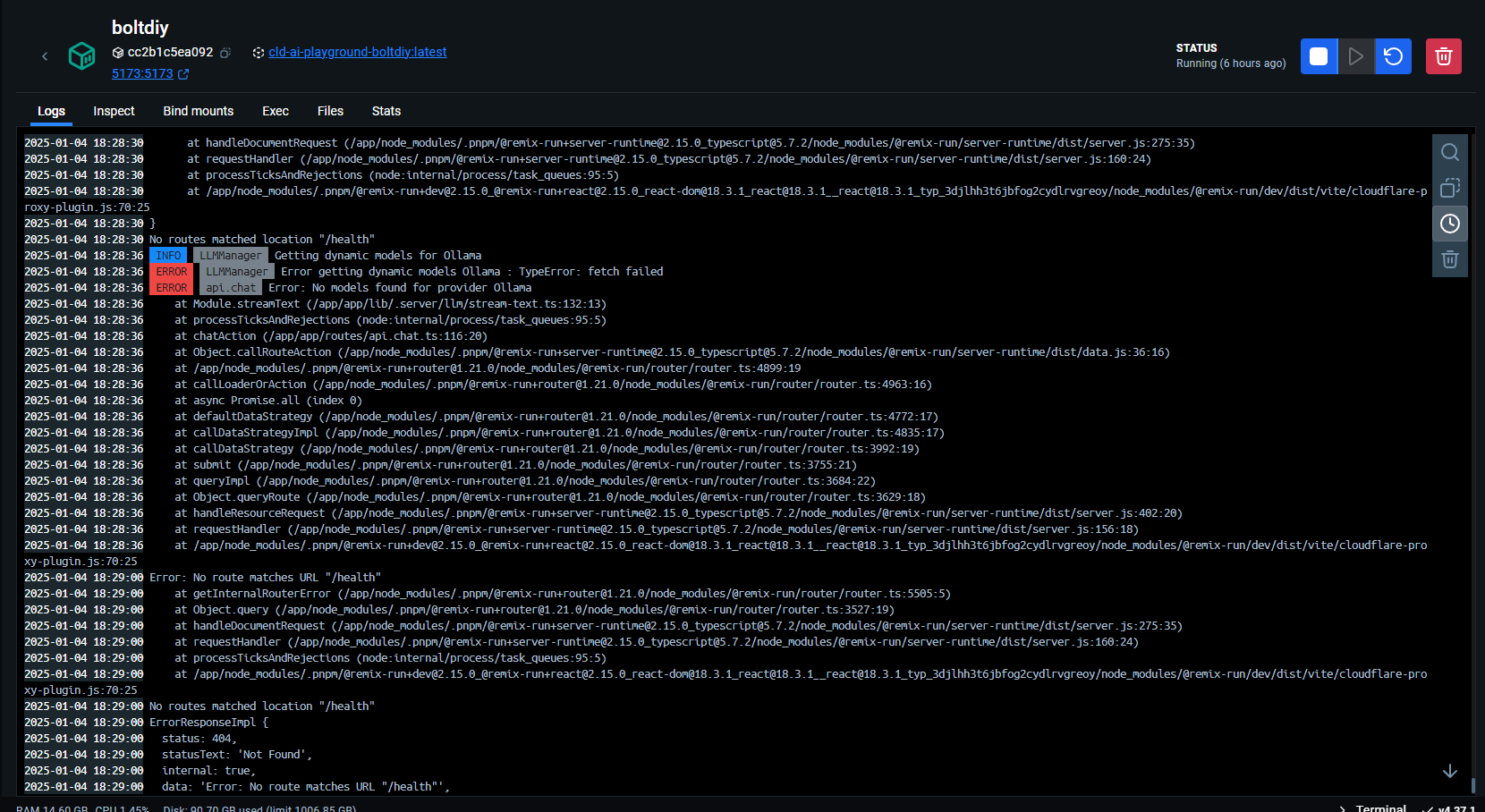
So, after doing some deeper digging, I’ve found that every time I launch bolt.diy (my stack, really), I get this error…
Strangely, when I refresh the page, it works as normal. I’m not sure if it has anything to do with my Docker logs below…
…but this appears in my logs, too.
The reason I bring this up is because while Bolt.diy can see my local models via Ollama, every time I try to select them to use them, I get an error saying “No details can be returned”.
My Ollama “install” is a Docker container as well; I didn’t want to install it on my desktop as a standalone app. Any advice or tips you can give me in helping to diagnose this error so I can use my local models and still use them like normally in Open WebUI? I’m installing on Windows 11 (via Docker Compose), and I’ve included my .yaml that I launch my stack with if it helps narrow anything down.
services:
# -----------------------
# 1) WATCHTOWER
# -----------------------
watchtower:
image: containrrr/watchtower
container_name: watchtower
runtime: nvidia
volumes:
- /var/run/docker.sock:/var/run/docker.sock
environment:
- WATCHTOWER_CLEANUP=true
- WATCHTOWER_POLL_INTERVAL=3000
- WATCHTOWER_TIMEOUT=300s
- WATCHTOWER_INCLUDE_STOPPED=true
networks:
- shared-network
restart: unless-stopped
env_file:
-my-keys.env
# -----------------------
# 2) OLLAMA
# -----------------------
ollama:
image: ollama/ollama
container_name: ollama
depends_on:
- watchtower
ports:
- "11434:11434"
runtime: nvidia
volumes:
- ./ollama:/root/.ollama
networks:
- shared-network
restart: always
env_file:
-my-keys.env
# -----------------------
# 3) TABBYAPI
# -----------------------
tabbyapi:
image: ghcr.io/theroyallab/tabbyapi:latest
container_name: tabbyapi
depends_on:
- watchtower
ports:
- "5000:5000"
runtime: nvidia
environment:
- NAME=TabbyAPI
- NVIDIA_VISIBLE_DEVICES=all
volumes:
- ./models:/app/models
- ./config.yml:/app/config.yml
networks:
- shared-network
restart: always
healthcheck:
test: ["CMD", "curl", "-f", "http://127.0.0.1:5000/health"]
interval: 30s
timeout: 10s
retries: 3
env_file:
-my-keys.env
# -----------------------
# 4) LITELLM
# -----------------------
litellm:
image: ghcr.io/berriai/litellm:main-latest
container_name: litellm
depends_on:
- watchtower
- tabbyapi
- ollama
- db
ports:
- "8000:8000"
runtime: nvidia
environment:
- DATABASE_URL=postgresql://llmproxy:dbpassword9090@db:5432/litellm
- STORE_MODEL_IN_DB=True
- PORT=8000
volumes:
- ./proxy_config.yaml:/app/config.yaml
- ./litellm-data:/app/backend/data
command: ["--config", "/app/config.yaml", "--num_workers", "8"]
networks:
- shared-network
restart: always
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8000/health"]
interval: 30s
timeout: 300s
retries: 3
env_file:
-my-keys.env
# -----------------------
# 5) BOLT.DIY
# -----------------------
boltdiy:
build:
context: ./bolt.diy
dockerfile: Dockerfile
target: bolt-ai-development
container_name: boltdiy
depends_on:
- watchtower
- litellm
- ollama
ports:
- "5173:5173"
runtime: nvidia
environment:
- NODE_ENV=development
- PORT=5173
- OLLAMA_API_BASE_URL=http://127.0.0.1:11434
- RUNNING_IN_DOCKER=true
- HUGGINGFACE_API_KEY=${HUGGINGFACE_API_KEY}
- OPENAI_API_KEY=${OPENAI_API_KEY}
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY}
- OPEN_ROUTER_API_KEY=${OPEN_ROUTER_API_KEY}
- GOOGLE_GENERATIVE_AI_API_KEY=${GOOGLE_GENERATIVE_AI_API_KEY}
- TOGETHER_API_KEY=${TOGETHER_API_KEY}
- TOGETHER_API_BASE_URL=${TOGETHER_API_BASE_URL}
- VITE_LOG_LEVEL=${VITE_LOG_LEVEL}
- DEFAULT_NUM_CTX=${DEFAULT_NUM_CTX}
networks:
- shared-network
restart: always
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5173/health"]
interval: 30s
timeout: 300s
retries: 3
env_file:
-my-keys.env
# -----------------------
# 6) PROMETHEUS
# -----------------------
prometheus:
image: prom/prometheus
container_name: prometheus
depends_on:
- watchtower
ports:
- "127.0.0.1:9090:9090"
volumes:
- prometheus_data:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=15d'
networks:
- shared-network
restart: always
# -----------------------
# 7) DATABASE
# -----------------------
db:
image: postgres
container_name: postgres
environment:
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
networks:
- shared-network
restart: always
# -----------------------
# 8) WEBUI
# -----------------------
webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
depends_on:
- watchtower
- ollama
- litellm
ports:
- "3000:8080"
runtime: nvidia
environment:
- OLLAMA_API_BASE_URL=http://ollama:11434/api
- OPENAI_API_BASE_URL=http://litellm:8000/v1
- NVIDIA_VISIBLE_DEVICES=all
- NVIDIA_DRIVER_CAPABILITIES=compute,utility
volumes:
- ./appdata:/app/backend/data
- ./shared-data:/app/shared
networks:
- shared-network
restart: always
# -----------------------
# 9) PIPELINES
# -----------------------
pipelines:
image: ghcr.io/open-webui/pipelines:main
container_name: pipelines
depends_on:
- watchtower
- webui
ports:
- "9099:9099"
runtime: nvidia
environment:
PIPELINES_URLS: "https://github.com/open-webui/pipelines/blob/main/examples/filters/detoxify_filter_pipeline.py"
volumes:
- pipelines:/app/pipelines
networks:
- shared-network
restart: always
# -----------------------
# 10) TIKA
# -----------------------
tika:
image: apache/tika:latest
container_name: tika
depends_on:
- watchtower
ports:
- "9998:9998"
networks:
- shared-network
restart: always
# -----------------------
# NETWORK & VOLUMES
# -----------------------
networks:
shared-network:
driver: bridge
volumes:
prometheus_data:
pipelines:
Thank you so much for developing this and giving us an opportunity to brainstorm together; this is going to really help me out in trying to develop my own workflow in agentic development and hopefully I’m able to pitch in with collaboration!!