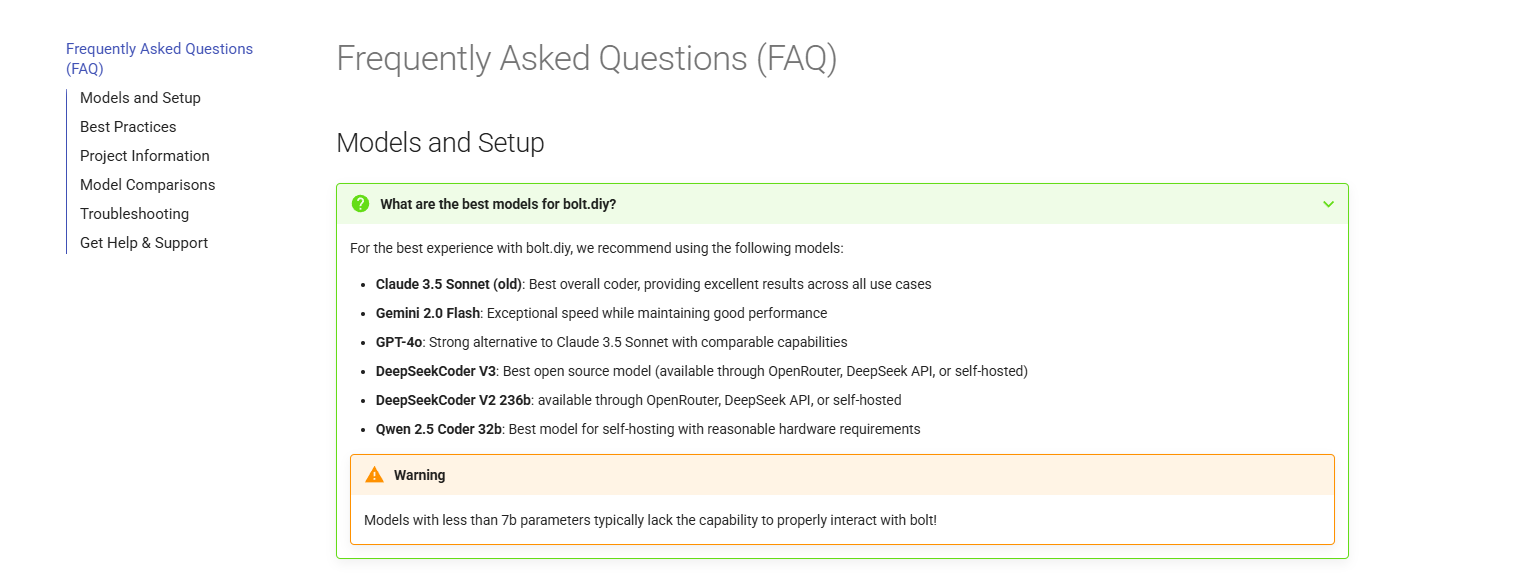
I have bolt.diy up and running in a Docker container which seems to work well but all the LLM’s I run don’t seem to be aware they are working in bolt.diy.
I’m hooked up to the OpenRouter API and am trying out some different LLM’s.
Deepseek V2.5: can be a bit slow (avg 20tps) but after creating a project, won’t modify my files.
Google Gemini Flash 1.5 8B: is really fast (avg 180tps) but doesn’t seem to be aware of my project in bolt.diy (if I ask it to modify my project it makes recommendations rather than modifying the project)
Microsoft Phi-3 Medium 128K Instruct: is fast enough (avg 55tps) but isn’t aware that it’s running in bolt at all (just responds in the chat with code snippets but the bolt project is not created)
Does anyone else have the same experience?
I’m wondering if there is something wrong with my set up. I’d like to get to use an LLM which responds and writes code in bolt.diy as quickly if possible.
hi, so i used google provider and it was fine i asked in the chat and it modify in the files, but when i switched to “openrouter” and every free model seem to respond with code in the chat.
thank you, first thing i just started a new chat and when i uploaded my project again it worked with the openrouter provider, but as you said, i just checked and i was trying to use almost only the 7B models (free ones, qwen, mistral…) and when i used “llama 3.1 70b-instruct” it worked again.