Hi everyone, kinda new to AI and development.
I have a RTX4070ti trying to use qwen 2.5b coder 14b or 32b as i have 64gb ram. At the moment its using only my CPU, any idea why thats the case?
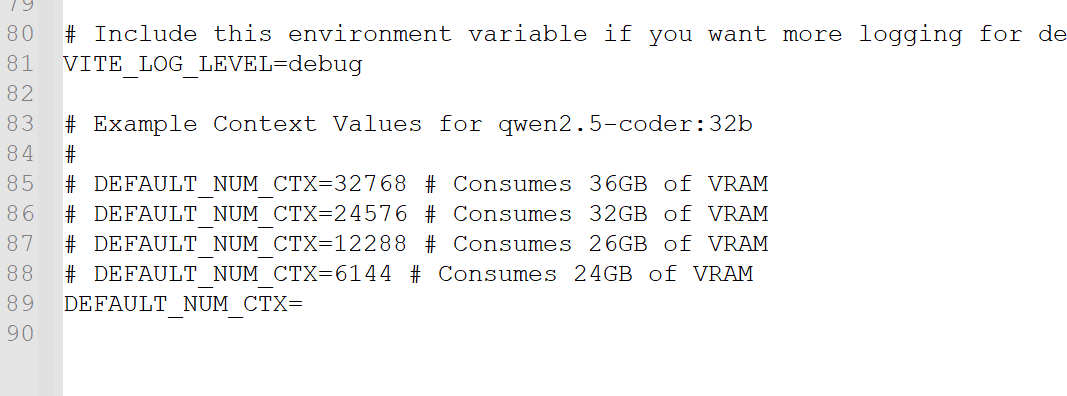
Is it the context size? In that case any idea what is a better context size to fit my gpu and also share 16gb of VRAM with 4GB of DDR5 to run qwen 2.5 32b? Thanks