Just wanted to share quickly that Qwen 2.5 Coder 32b was released yesterday and this is now my favorite model already for working with oTToDev. The 7b parameter version of Qwen 2.5 Coder has been around for a while, but this larger version is brand new and totally crushing it! I’d highly recommend giving it a shot if your machine is capable!
I’ll be making content around it this week. Also I’ll pin this post for the week since honestly this is a pretty big deal considering how well it is performing!
Here is a link to the model in the Ollama library:
Running a large language model like Qwen 2.5-Coder 32B on a laptop is likely to be challenging due to the significant computational and memory requirements of such models.
The RTX 4070 has 12GB of dedicated VRAM. While this is substantial, loading and running a 32B model would likely require more VRAM than is available. Even if you could fit the model into VRAM, the performance would likely be very slow. While the RTX 4070 and 16GB of RAM provide some capability for running large models, the combination of insufficient VRAM, limited system RAM, and the processor’s limitations make it impractical to run Qwen 2.5-Coder 32B on this setup. For practical use, you would likely need a more powerful system with at least 32GB of system RAM and a GPU with more VRAM, such as an RTX 3090 or RTX 4090. Alternatively, you could consider using cloud-based services that provide access to powerful GPUs and the necessary infrastructure to run such large models.
qwen coder 32b is a stretch for my M1 Max, so I decided to mess around with the 14b and 3b instruct models instead. According to the link @dsmflow posted, the instruct models compete fairly well against the larger base ones. Jury’s out if that’s the case, but doing some testing against oTToDev this week to find out.
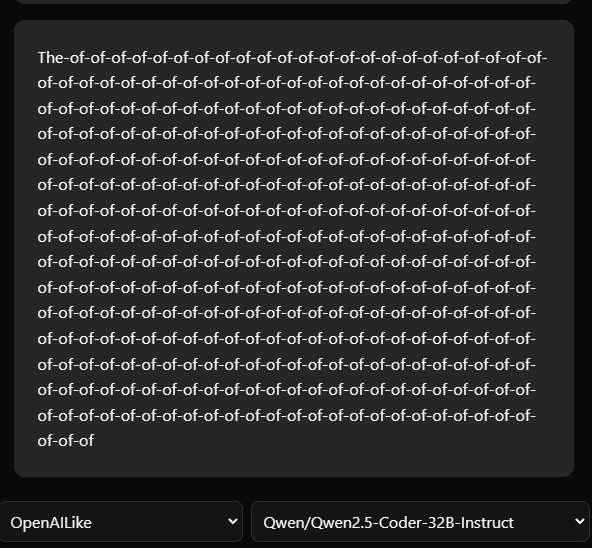
yeah, it’s still do that idk why
2-3 promts is okay, but then…of-of-of-of-of-of-of-of-of-of-of-of-of
maybe the problem on hyperbolic side, i used their api
upd.
it was hyperbolic
i changed base to DeepInfra and it works perfectly
15 prompts so far, there was a lot of errors that everyone is talking about (problems with loading previews, etc), but qwen fixed them all
Hey, how did you get to choose the provider? I tried setting it as staticModels in constants, but it doesn’t show in the list if the provider is any other than OpenRouter.
Seems weird that Hyperbolic would give worse results than other providers because DeepInfra and Fireworks have 33K context and 4K max output but Hyperbolic has 128K context and 8K output. The difference should be significant. Maybe it’s one of the next features of oTToDev – an interface to tune the model parameters and choose the provider?
@dinopio Did you install the default version that Ollama gives?
The default model is actually Q4 quantization so it’s not the actual full size of the model but still performs almost as well. I would make sure you are using that!