Sorry I missed those and yes that was a question I was expecting - I have 64m memory so plenty but need to set context also. Will do that now and let you know the result.
No, you got 64GB of RAM, which is not GPU VRAM. But this is what you need to run local models. A dedicated GPU which lots of VRAM ![]()
What graphics card you got?
I’m hopeless. Drove 50km into Melbourne yesterday and bought 2 x 32G DDR5 Ram only to get home and realise my machine only takes DDR4/PC4 so had to swap them today. I’d read it needed to be read into memory. Not Vram. I didn’t know this although I know video memory is often used in commercial setups.
Might be a good notice on any guides to make it clear the user needs the video resources because it just may be assumed by others.
Do I have enough graphics memory available or can I reconfigure memory to get this up for now.
If I need another graphics card, I’ll source one tomorrow.
Ok, thats not very much and not capable of running Models which work well with bolt. You could try some quantized models and try these.
I understand your frustration now, but this is nothing that is directly related to bolt.diy.
You can try this one: qwen2.5-coder:3b
The question here is, what the benefit is for you to buy an expensive graphic card to run local models properly, instead of e.g. using OpenRouter with some very cheep models in there.
If you e.g. want to see colemedin´s setup take a look here:
https://pcpartpicker.com/user/coleam00/saved/#view=3zHNvK
To match this, you would need to spent 3000 Dollars on 2 Nvidia 3090. Even If you just buy one its 1500 Dollars ![]()
You could try to get some older models etc., as discussed here in other topics, but I dont think this is something you should do if you dont want to spent a lot of time configuring, trying out etc.
Recommendation: Use OpenRouter with Qwen-Coder 32B Model or Google Gemini what is actually free to use at the moment.
Just asked ChatGPT for some information what is needed in general, see: ChatGPT - New chat
Think it gives a brief overview.
Thanks so much for your effort - really appreciate it.
In the short term it’s probably better and cheaper to go that route. I had already spent a bit with Bolt.new and their support was terrible and kept going to the next tier just to be disappointed. Multiple circular errors and went back to restart an app based on what I’d learned. It’s well worth pursuing and I can see once done right, it will be brilliant.
My Macbook pro was never going to cut it either. LOL.
Thank you legend and I will make sure when I’m sorted I’ll come back and potentially help some others get on their way.
I’m just getting over Chemo and my neck being fused and had cancer removed - been a year of hell and slowly getting back on my feet - I love coding and worked with developers for years. But as I heal and repair I need something to keep me going too.
Thank you.
1 Like
Happy I could help you a bit.
Wish you all the best.
1 Like
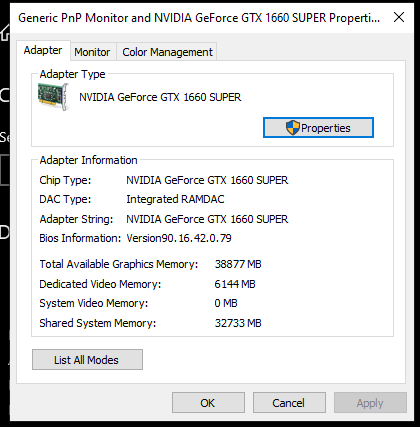
I had one of those (GTX 1660 Super), because they were arguably the last chip on the cusp of RTX, they don’t support mixed precision. Mine gave me a lot of issues with AI, so I replaced it. You are going to be limited on what makes you can run, but modern quantized models should work… There’s a lot more support then there used to be for then. But I remember it being a pain.
2 Likes
@aliasfox @leex279
Thanks so much Thomas and Michael.
Once doing some digging I find some resources that help understand the requirements a lot more.
ChatGPT offered this advice.
 on NVIDIA Jetson Development Board")
I did see Nvidia’s new release a few days ago. Do you think this would run Bolt.diy Ollama and Qwen2.5-32b ok…??
There should be some benchmarks that stand out for you guys. If not now, at least it’s something you’ll get a good understanding for very soon…?
1 Like
Might have something here. While these are not apples to apples, specs put the nano between the performance of an RTX 4080 and 4090, with a compelling price. Keep in mind this is a development board and I’m not sure what all can run on it, but intriguing none the less. But even more so is the AGX series that comes in an ITX Mini-PC formfactor. Despite the low clock speed, the v4 boards appears to be a huge leap in performance (they claim 8X), and a powerhouse.
I’d like to test that thing out!
| Model | Perf. | Bandwidth | CPU Freq. | Memory | Cost |
|---|---|---|---|---|---|
| NVIDIA GeForce RTX 3070 | 20.3TF | 448GB/s | 1.5Ghz | 8GB | $420 |
| NVIDIA GeForce RTX 3080 | 29.8TF | 760.3GB/s | 1.44Ghz | 10GB | $520 |
| NVIDIA GeForce RTX 3090 | 35.5TF | 936.2GB/s | 1.4Ghz | 24GB | $1000 |
| NVIDIA GeForce RTX 3090 Ti | 40TF | 1.01TB/s | 1.56Ghz | 24GB | $1600 |
| NVIDIA GeForce RTX 4080 | 48.7TF | 716.8GB/s | 2.2Ghz | 16GB | $1150 |
| Jetson Orin Nano Developer Kit | 67TF | 102GB/s | 1.7Ghz | 8GB | $249 |
| NVIDIA GeForce RTX 4090 | 82.5TF | 1.01TB/s | 2.24Ghz | 24GB | $2800 |
| Jetson AGX Orin 64GB Dev. Kit | 275TF | – | 1.3Ghz | 64GB | $2000 |
Note: Please keep in mind, this is for the latest gen development boards.
Other considerations: Memory Bus, Boost Clock, TDP, Tensor Cores, Cuda, etc.
Resources:
1 Like
why not add 3060 to the list is has 12GB vram, and buying 2 of them will still be half the price of 3090 with same vram. with ofcource lower speed but at least you can load larger model then buying 3080 with similar price.
and at the cost of one 4080 which has 16GB vram, you can have 4, 3060 with 48GB of vram. ![]()
2 Likes
Due to overhead, that’s sadly not always true for performance. But as for VRAM and multiple GPU support now, it should be. But if we are going down that road, another option that I’m hesitant to bring up is the Intel A770 16GB. I was hopeful and bought two when they were first released at $270/ea, but the support for them on anything was horrible… but now mostly everything seems to support them. And you can buy 4 for the price of a 3090 (if you can fit them in a tower).
Basically, the same performance as a 3090 Ti on paper and half the 4090.
| Model | Performance | Bandwidth | CPU Frequency | Memory | Cost |
|---|---|---|---|---|---|
| NVIDIA GeForce RTX 3060 12 GB | 12.7TF | 360.0 GB/s | 1.3Ghz | 16 GB | $280 |
| Intel A770 16GB | 39.3 TF | 512.0 GB/s | 2.1 GHz | 16 GB | $270 |
Just food for thought!
P.S. I didn’t know there was even more I didn’t know about the Discourse forum, but you can Edit Tables! Pretty awesome, lol. And added the RTX 3060 for comparison, as @thecodacus mentioned.
2 Likes
yes its more of a vram recommendation, to get a single 24GB vram card you have to spend lot more than a dual, 3060 card, I will rather spend my budget on vram (if I am on a tight budget and cannot afford higher tier cards). that way at least, i will be able to load the model. performance comes 2nd to me (no point on having performance if the model cannot be loaded).
Intel I am not very much sure as most of the inference framework is optimized for cuda. unless it become widely adopted, might not be worth the risk and money
1 Like
Yes and no. I think there’s always a fine line. By no means the best cards, but I tested this theory on a low-budget AI Build. Older off lease server/workstation hardware with 2x Xeon CPU’s, 48GB VRAM (2x Tesla M40’s), 18TB HDD + 1TB SSD, and 192GB ECC Memory < $850. It works well but I haven’t tested it with other cards (though now that there is support for the Intel A770, I’d like to compare the two).
And I might also be interested in buying the Jetson ITX Mini-PC.
| Model | Performance | Bandwidth | Frequency | Memory | Cost |
|---|---|---|---|---|---|
| NVIDIA Tesla M40 | 6.8TF | 288.4 GB/s | 948Mhz | 24 GB | $190 |
DISCLAIMER ![]() : This is a server GPU and does not come with a fan or Display output. Not recommended for most users; technical and troubleshooting skills are required!
: This is a server GPU and does not come with a fan or Display output. Not recommended for most users; technical and troubleshooting skills are required!
2 Likes
Hi leex279… I saw you were trying to help and I also have an issue. I’m starting to think that the problem is my computer.
I think I did everything right… But when I try to connect codellama 7B I get an error message.
Have a look at these screenshots to see if you can help me figure it out.
I can only add one image… but I have Ollama working for sure…
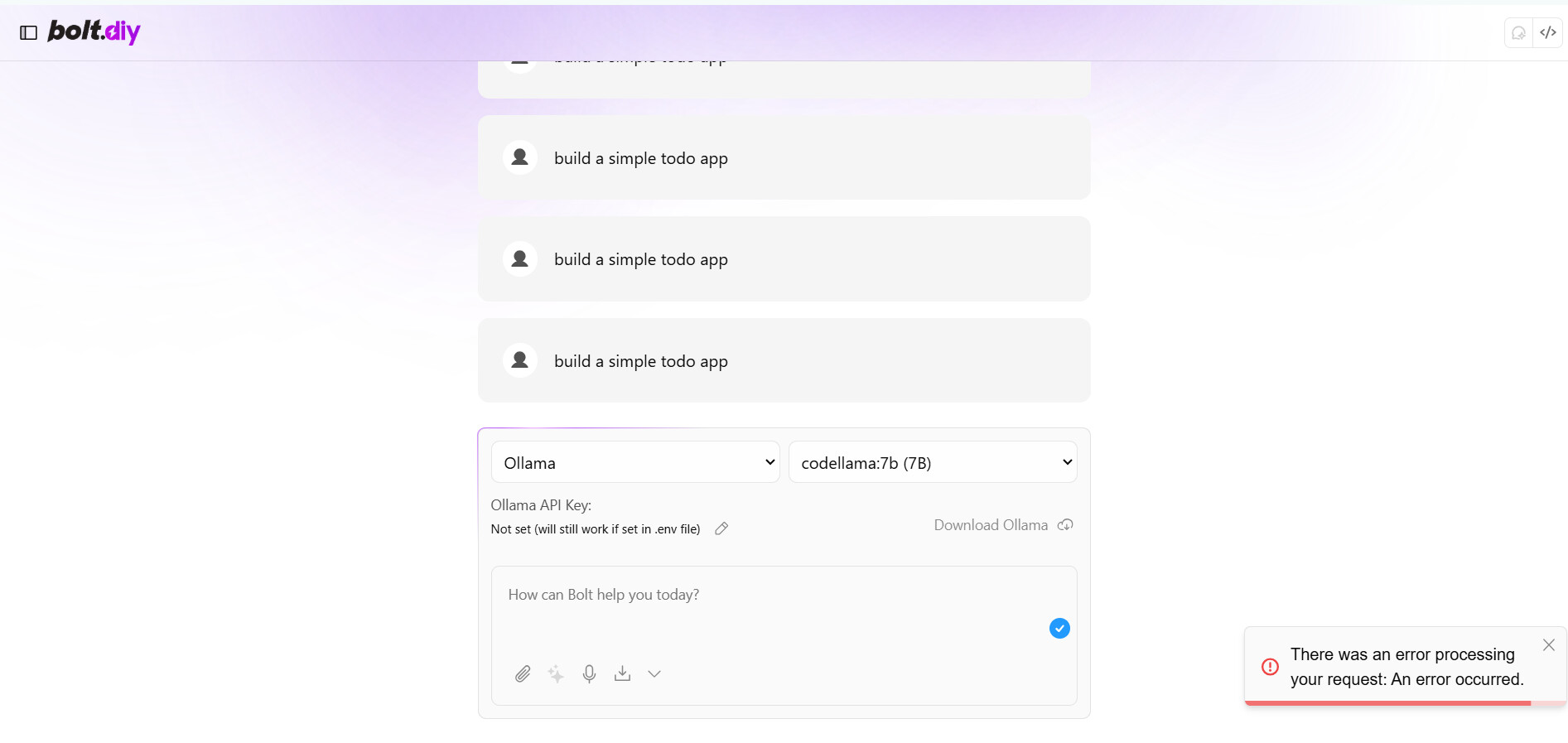
did you test your Ollama Model via the API and also checked the ollama logs when the error in bolt occurs?
curl -X POST http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "your-model-name",
"prompt": "Your prompt here"
}'
Anyone testet with / has experience AMD GPUs?
Hi leex…
So I run the Ollama test and got this:
C:\WINDOWS\system32>curl -X POST http://localhost:11434/api/generate -H “Content-Type: application/json” -d “{"model": "codellama:7b", "prompt": "Say hello"}”
{“error”:“model requires more system memory (7.5 GiB) than is available (6.6 GiB)”}
So I’m guessing my computer is not suited for this… ![]()
1 Like