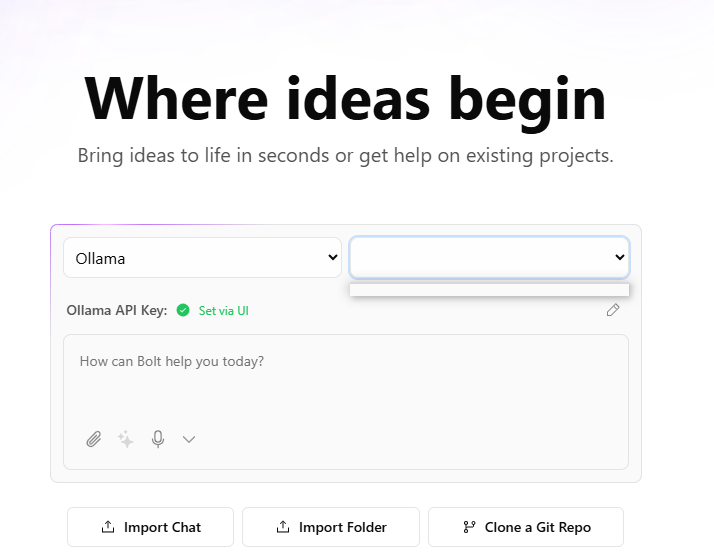
i have installed ollama to run some of the models for free. i have already downloaded the models that i want to use in Bolt.diy. However i am confused what exact api to use in the setui for the bolt.diy chat interface. i read the example .env file which says the following-
You only need this environment variable set if you want to use oLLAMA models
i watched the video and it was really helpful. ollama is running now however it hangs when i send a prompt within the bolt interface. when i chat within the terminal it responds quickly. i have 8 gb of ram and trying to run qwen 2.5 - 1.5b. Also i watched your video when it talks about # Example Context Values for qwen2.5-coder:32b
@mottobiz For the correct value just start with some value that is maybe working. Think about 6000 or so, then try it out with bolt and watch your used VRAM in task manager. It should at best use the available VRAM fully, but not exceed it, as it would then use normal RAM as well, which slows down, cause normal RAM is slower then VRAM.
At all, you should not expect this model/llm works with bolt. As in the docs the minimum suggestet is 8B, which is also very less. I did not find a single model which is working “good” with bolt, which is below 32B and even this is to less, to get good results.
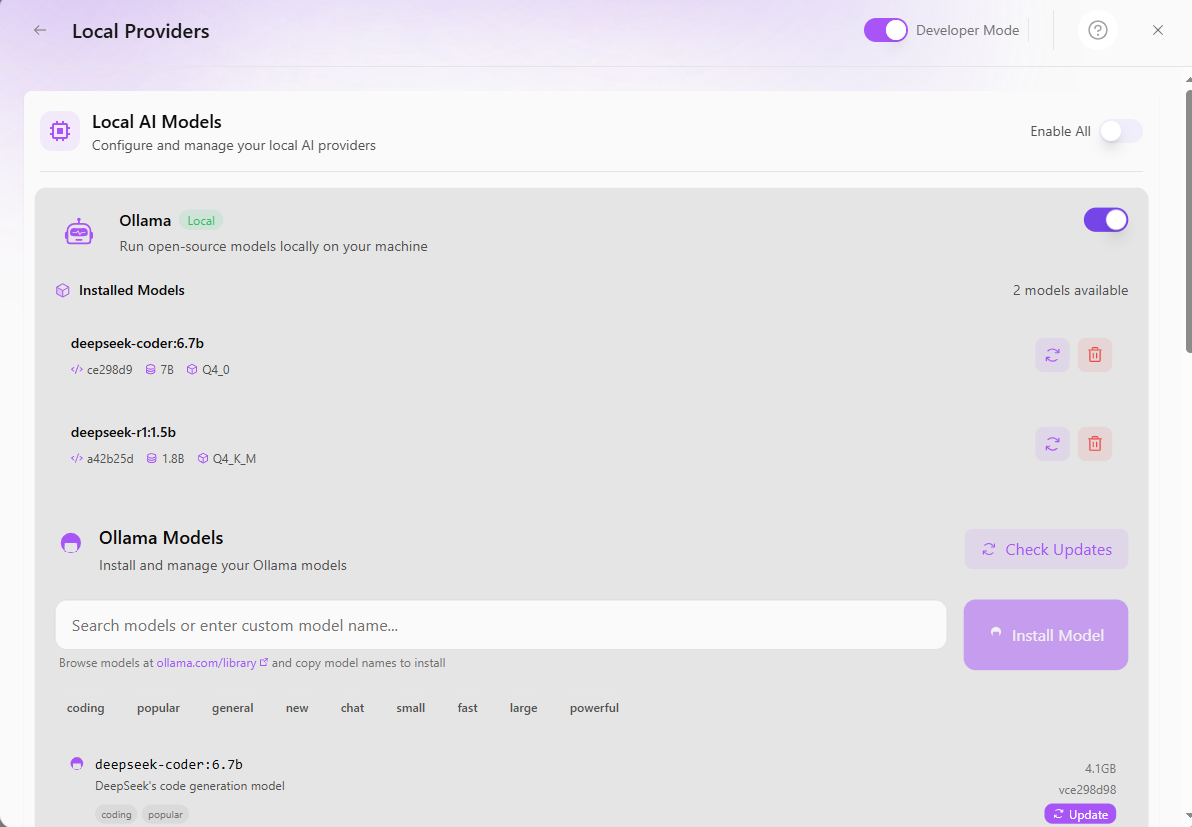
@leex279 - the latest version of bolt.diy from main branch not having the option to configure the base url for ollama. I set the env var as mentioned in the video but I’m getting the no base url error and my model list is empty as shown. I checked in cmd and my deepseek model is running good.