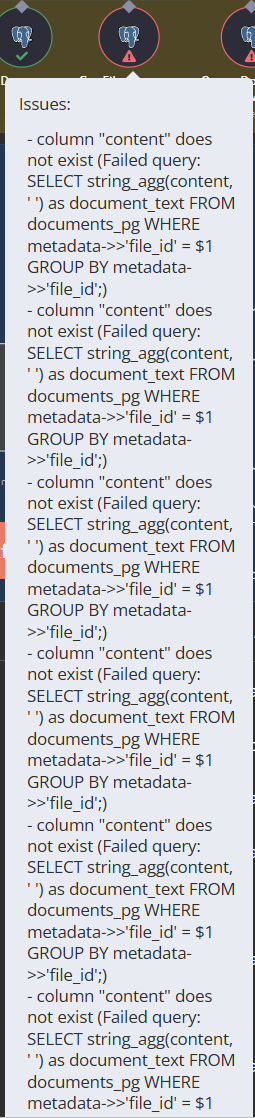
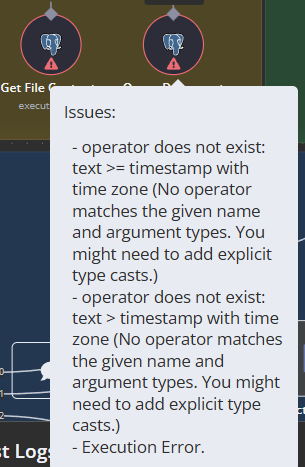
I’ve run into some issues where the agent can’t read the data from the database. So I went back to your original V3 that you recently released a video on and run it exactly how you configured it out of the box.
I’m still getting a few error codes while it’s trying to execute though, and they’re the following:
The ai-agent goes back and forth for a while, until it stops with the following message. “Agent stopped due to max iterations.”
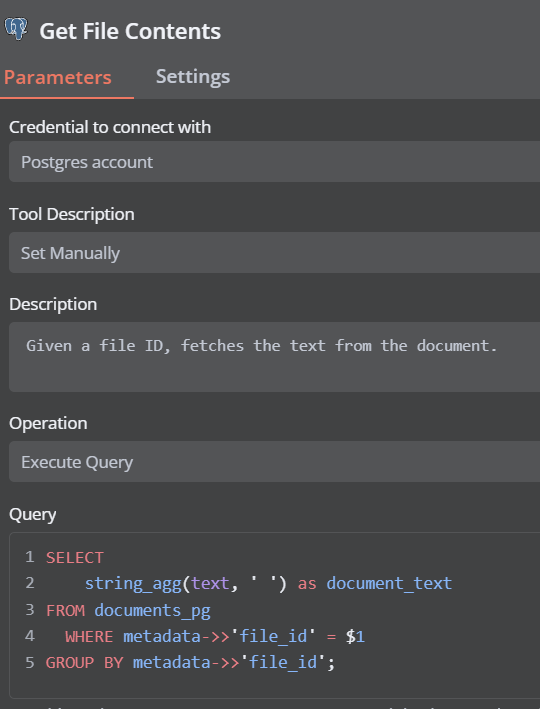
Why is it failing to execute the get file contents, saying it doesnt exist?
I’m using some performance logfiles from azure, saved as CSV, to do this testing.
Had to post second image here of error code, since I’m a new member.
It looks like you haven’t setup your Postgres credentials. I see a red triangle in the picture you posted above. Do you have your Postgres credentials added?
1 Like
No issues wih credentials, I changed “content” into “text” and now it works. however it doesn’t perform very well when I use these logfiles. It’s struggling to get the full context, when I spesifically tell it to. It’s reply is very clearly lacking a lot of context that’s needed for dataanalyzing.
1 Like
column “cputime” does not exist
Failed query: SELECT CpuTime, MemoryWorkingSet, Requests, BytesReceived, BytesSent, HttpResponseTime, timestamp FROM document_rows WHERE dataset_id = ‘/data/shared/azure_metrics.csv’ AND timestamp > NOW() - INTERVAL ‘7 days’;
Getting this from “Query Document Rows”… so that’s why the agent doesn’t get the context. It’s trying to run some queries that it shouldn’t. Not sure how to fix that…
Unless the issue is with how the data is handled in the first place?
The plot thickens… This is very confusing but it seems the data is being processed very different than expected.
All the chunks are ending up in document_pg for some reason and the documents as a whole is actually ending up in Rows… wtf xD
I wish I could help, but I think Cole might need to jump in here. I think there should be chunks in the documents_pg (assuming you are using Postgres).
I’d have to see your workflow to know exactly where the tables aren’t quite being set up right, but if I were you I’d go through all the Postgres nodes one by one and make sure that they are referencing the right table!
But also the setup does seem right to me (maybe I’m misunderstanding) - chunks go to document_pg, that is correct. Then the document metadata (titles and table schemas) go to document_metadata. Then document_rows should contain all the rows for your table files.
ah okay, then I’m the one who got it wrong.
I’m using your exact template, only added credentials and ran the nodes to create DB.
I guess the issue then lies with the query it tries to run when I’m asking it to analyze the data. I want it to look at the documents as a whole rather than chunks, but it fails it every time running different queries.
Could it be because of the modell I’m running? I’m using qwen2.5:7b-instruct-q5_K_S. Also been trying the q6_K version.
another cause could be bad data, I tried converting it into excel and it looks very different than some other datalogs I had to run testing with. I’ll delete the database tomorrow and do some retesting with other data to see if I run into the same issue or not. It might just be bad data and nothing wrong with workflow/agent.
I’ll post my findings after some more testing tomorrow!
Sounds good! And to your earlier comment it certainly could be the LLM - 7b parameters is pretty small even with Q5/Q6! You’ll get much better results even with Qwen 2.5 14b Q4
after tons of testing for the past two days, whenever I found the time. I found it was simply bad data. I don’t know exactly what causes the issue but I couldn’t get the workflow to process the data correctly. I messed around a lot with the script I use to get the data from azure, and after converting it to xlsx it finally works correct. Even with a 7b model it performs NIGHT AND DAY. It actually can manage to do amazing things with this data.
Thanks for taking your time try and help but it’s all sorted now! and thank you again for this template. it’s amazing. 
1 Like
@techzonereal I appreciate you posting this. I ran into the issue with the ‘content’ column in the ‘document_pg’ table not existing. Changing this to ‘text’ seems to have fixed the issue I had with that query failing.
Well I do not think that using ‘text’ can be correct solution. It is returning full content and ends up rate limiting calls to the llm