Dear Community,
I discovered bot.diy today and excited about it. I managed to set it up and load up the main screen. I can also feed my API keys to start using with Gemini.
However, my motivation was to configure with a local LLM (I have Deepseek-r1:7b on my Macbook. I am unable to configure it. Whereas I can choose Ollama as the provider, the model list is empty and it seems to ask for an API key. As my Deepseek-r1:7b model is being served locally by Ollama, I am not sure how I configure it to work.
The second issue I have is that where I have tried to Sync the File, the explore section doesn’t seem to show the files that were apparently successfully synched…
Any support would be gratefully received. I have attached a screenshot
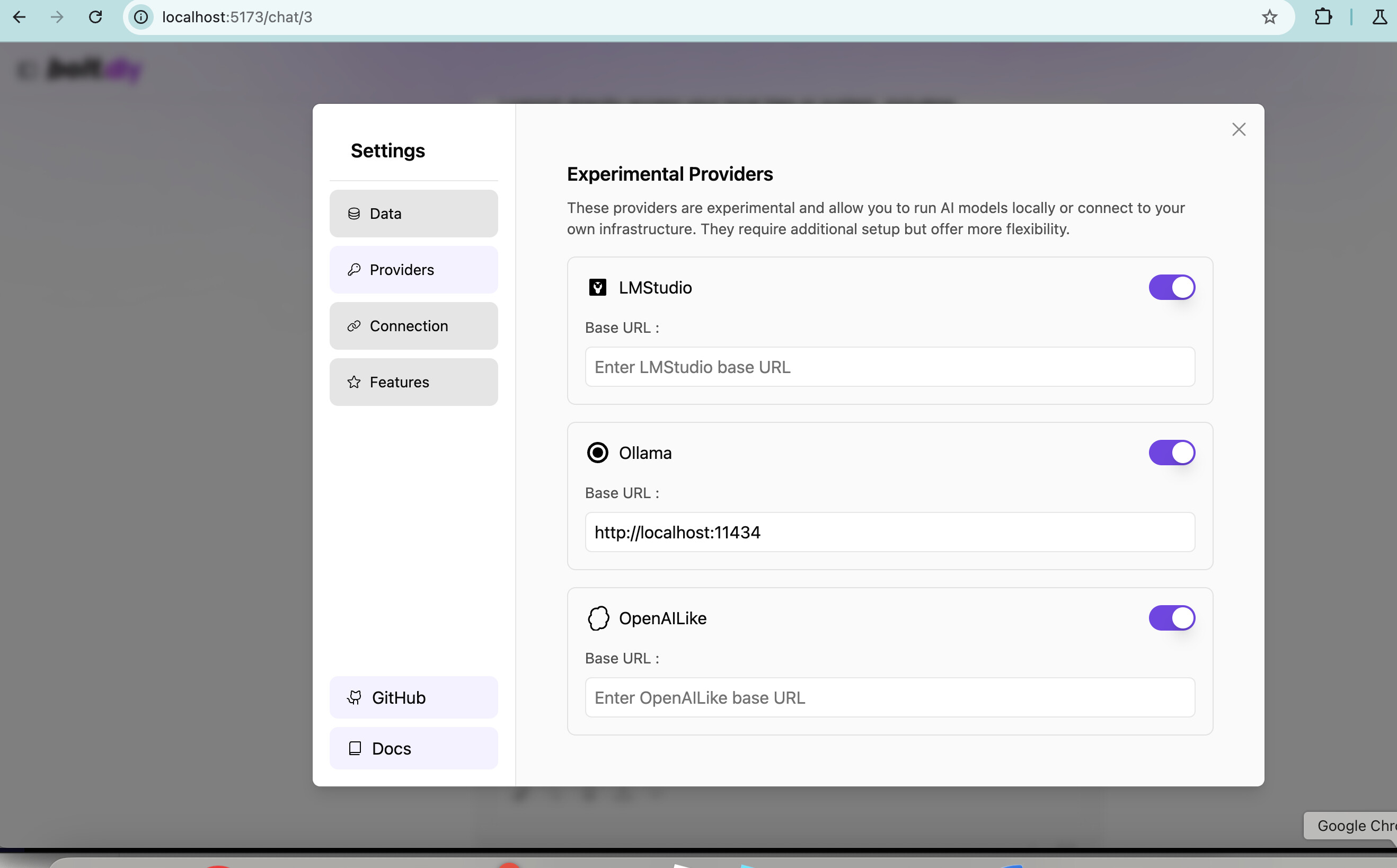
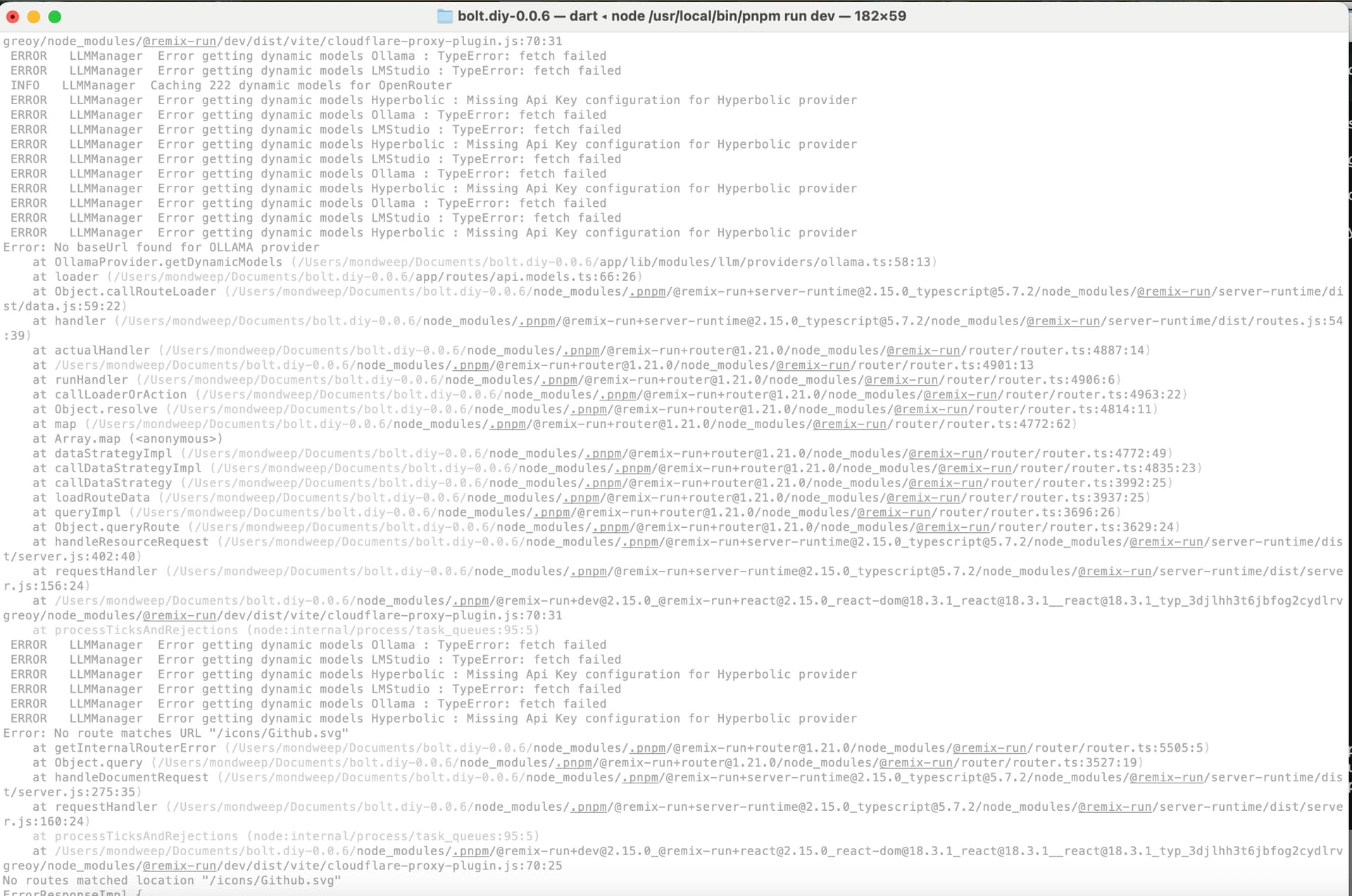
I was able to find the plan to update the Ollama base url. I then restarted the webapp. However, it fails to pick up the base url. I am also unsure how I specify my local deepseek-r1:7b model. Please see the screenshots
" INFO LLMManager Caching 0 dynamic models for OpenAILike
INFO LLMManager Caching 0 dynamic models for Together
ERROR LLMManager Error getting dynamic models Hyperbolic : Missing Api Key configuration for Hyperbolic provider
Error: No baseUrl found for OLLAMA provider
at OllamaProvider.getDynamicModels (/Users/mondweep/Documents/bolt.diy-0.0.6/app/lib/modules/llm/providers/ollama.ts:58:13)
at loader (/Users/mondweep/Documents/bolt.diy-0.0.6/app/routes/api.models.ts:66:26)
at Object.callRouteLoader (/Users/mondweep/Documents/bolt.diy-0.0.6/node_modules/.pnpm/@remix-run+server-runtime@2.15.0_typescript@5.7.2/node_modules/@remix-run/server-runtime/dist/data.js:59:22)
at handler (/Users/mondweep/Documents/bolt.diy-0.0.6/node_modules/.pnpm/@remix-run+server-runtime@2.15.0_typescript@5.7.2/node_modules/@remix-run/server-runtime/dist/routes.js:54:39"
From my testing, local “Distilled” models of DeepSeek-R1 don’t work with Artifacts (the bolt terminal and etc.) because they are not “Instruct” fine-tuned. You’ll want to try a different model. If you have a massive hardware constraints (or want to run an LLM on an RPI for example), you can try the smallest “Instruct” model (3B Parameters) I have seen work with bolt (and useable):
And for the size, the current best 7B Parameter LLM on the Hugging Face Open LLM Leader Board:
| Rank |
Type |
Model |
Average |
IFEval |
BBH |
MATH |
GPQA |
MURS |
MMLU-Pro |
CO2 Cost |
| #708 |
prithivMLmods |
QwQ-LCoT2-7B-Instruct |
28.57% |
55.61% |
34.37% |
22.21% |
6.38% |
15.75% |
37.13% |
1.37 kg |
You can install them for Ollama with:
ollama run hf.co/mradermacher/QwQ-LCoT-3B-Instruct-GGUF:Q4_K_M
ollama run hf.co/mradermacher/QwQ-LCoT2-7B-Instruct-GGUF:Q4_K_M
P.S. I do personally plan on creating a “Instruct” fine-tune set of the DeepSeek-R1 “Distilled” (1.5B - 32B) models to support Bolt.diy, but I’m still figuring out a few things and I will release them on both Hugging Face and Ollama. Maybe also write a how-to doc.
Lastly, I’d also go through your Bolt.diy settings to turn off all the extra stuff (like providers) that you aren’t going to use, and enable optimized prompts, etc.
Hope that helps!
2 Likes
I looked back through the messages and realized you put an API key for Ollama. Because it’s running locally, you don’t need to provide a Key… might be part of the issue.
1 Like
@private.winters.bf3 sorry for pinging you again, but this could also be done within the settings PR or a new one on the UI and hide the api keys for local providers at least on default and the user can enable if they got something 
@leex279 II will make a todo list for you that you can fill in so i know what issue i need to fix, enhance… or if you have a better idea let me know…
@private.winters.bf3 sounds good. Just create a internal topic here for UI Enhancements and we can add things there like the Agenda. As well all are Moderators, we (core team) can edit your post then and add things: https://thinktank.ottomator.ai/c/bolt-diy/bolt-diy-core-team/20