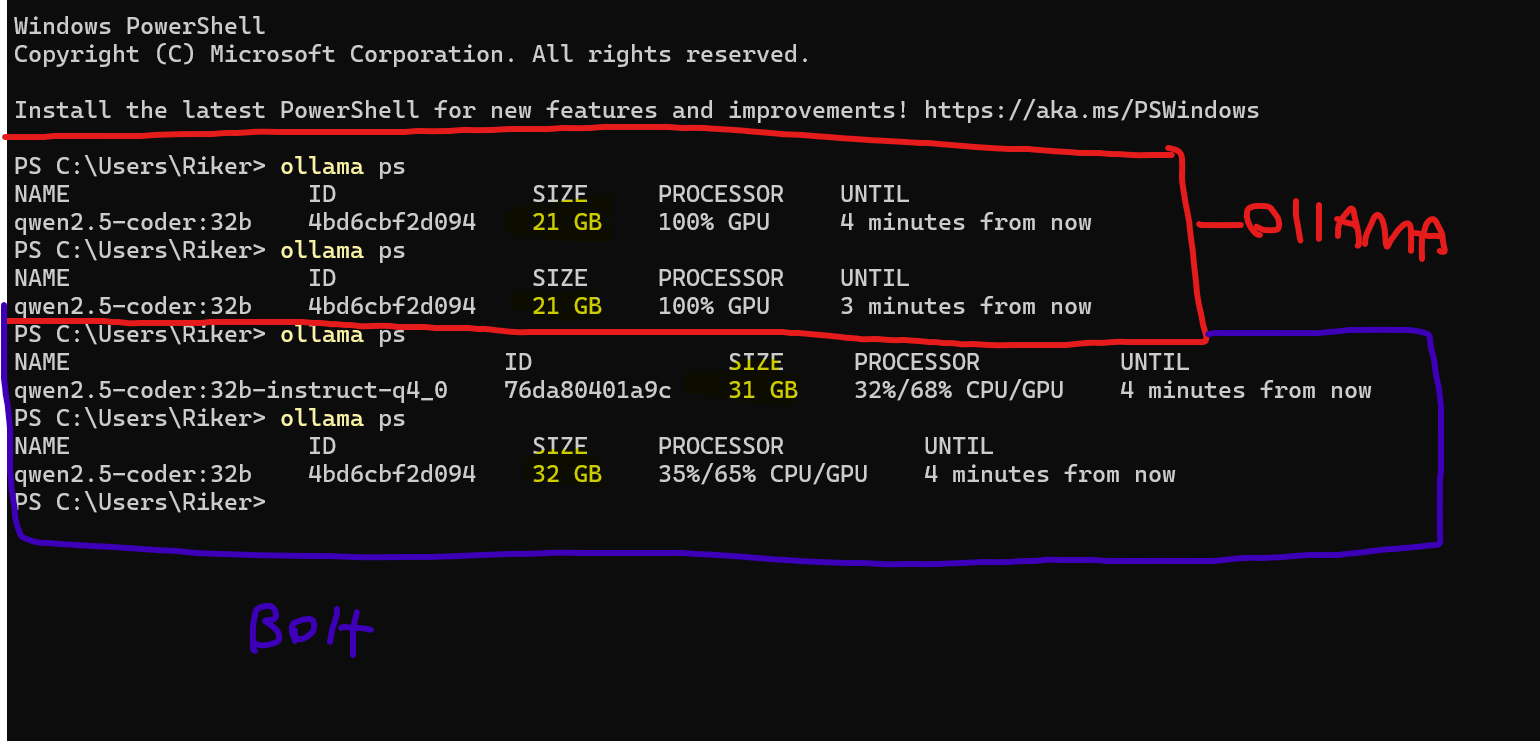
Hello everyone, stumbled upon this great looking project today but have stumbled at this hurdle.
My GPU is a 4090 so there should be no issue loading qwen2.5-coder:32b into memory, and when running locally on OLLAMA there is no issue (as seen in the red highlighted area). However when loading the same model via bolt.diy the size balloons to around 32GB instead of the 21GB which it would normally be operating at by just running OLLAMA.
Not sure if im missing something here but help would be greatly appriciated!