Just testet the new LLama3.3-Model in bold (see Screenshot). It did not write the code into the files, instead just writing in the chat.
is this a known problem or do I need to do anything to get it working?
Just testet the new LLama3.3-Model in bold (see Screenshot). It did not write the code into the files, instead just writing in the chat.
is this a known problem or do I need to do anything to get it working?
Testet a bit more and looks like its not happening all the time. Further files were written into the files.
Llama 3.3 was working for me fine, but I can’t say I extensively tested this model yet. I will take a look later to see if I can replicate this issue (generally it happens with smaller models).
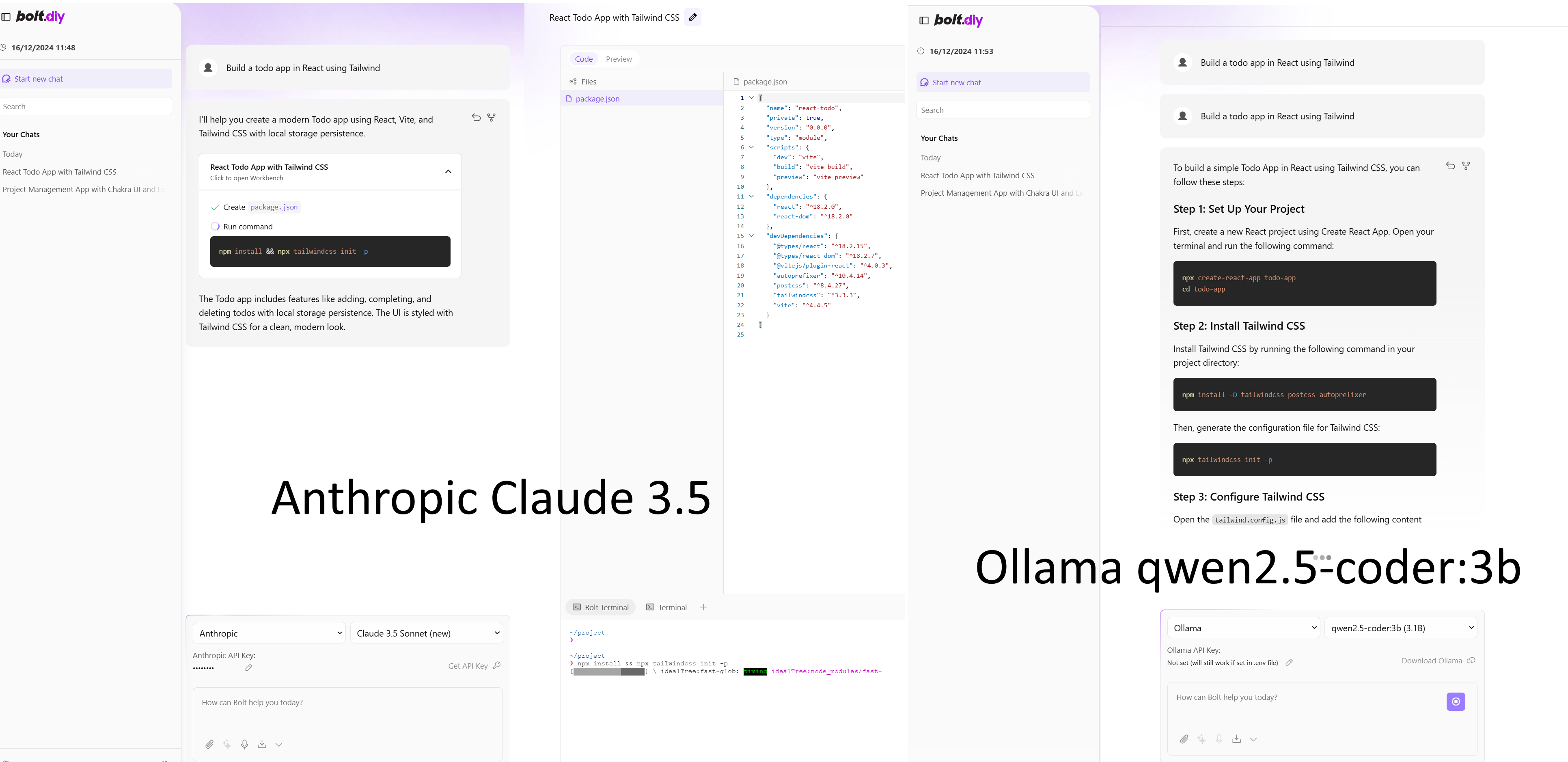
I am adding here as I am also having the same issue with using Ollama models. When I ask the locally run LLM some questions, I get the suggested files needed output in the chat not the code panel. This means, I get no benefit from the integration unless I use a cloud LLM such as Anthropic for example. Using the same prompt for both, I get the output from Anthropic Claude 3.5 (new) but only chat suggestions for Ollama.
To be clear, I am a total newb so I may be doing something fundamentally wrong so please forgive the stupidity.
See image below:
The other interesting thing is the chat history is not updated with anything that is fired at Ollama.
Is this a limitation of running a local LLM with far less memory and resource available compared to Anthropic?
Yes this is a limitation for any LLM that is 3b parameters or less! Unfortunately those models just aren’t able to handle the large Bolt prompting under the hood so they don’t generate artifacts correctly for the web container to display everything like larger LLMs can.
If you could, I would try using at least the 7b parameter version of Qwen 2.5 Coder! 32b if you want the best results and you can always use OpenRouter if your machine wouldn’t run that large of a model.
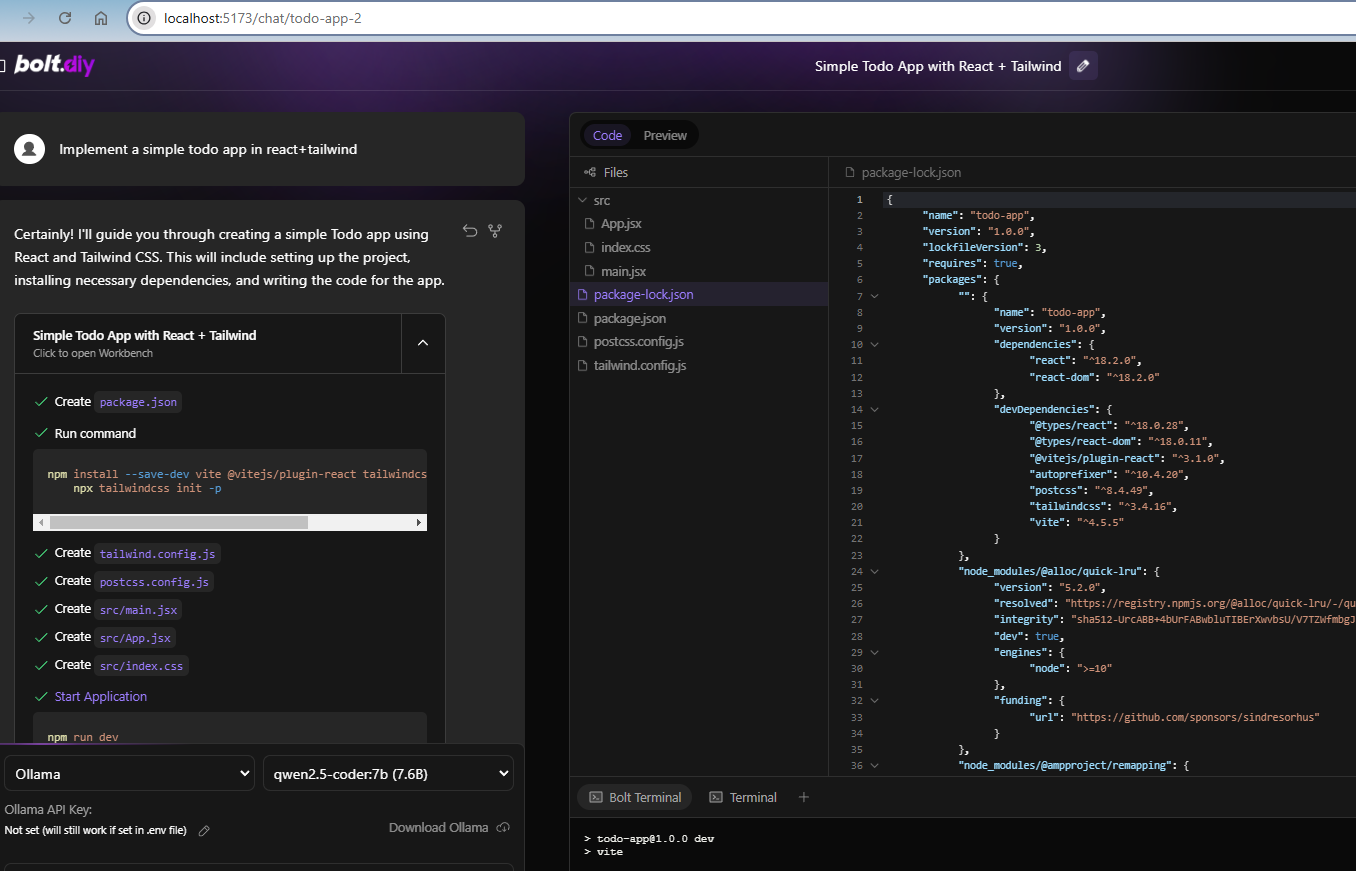
Nope, i try with a qwen2.5-coder:7b and nothing change, all code write in chat screen
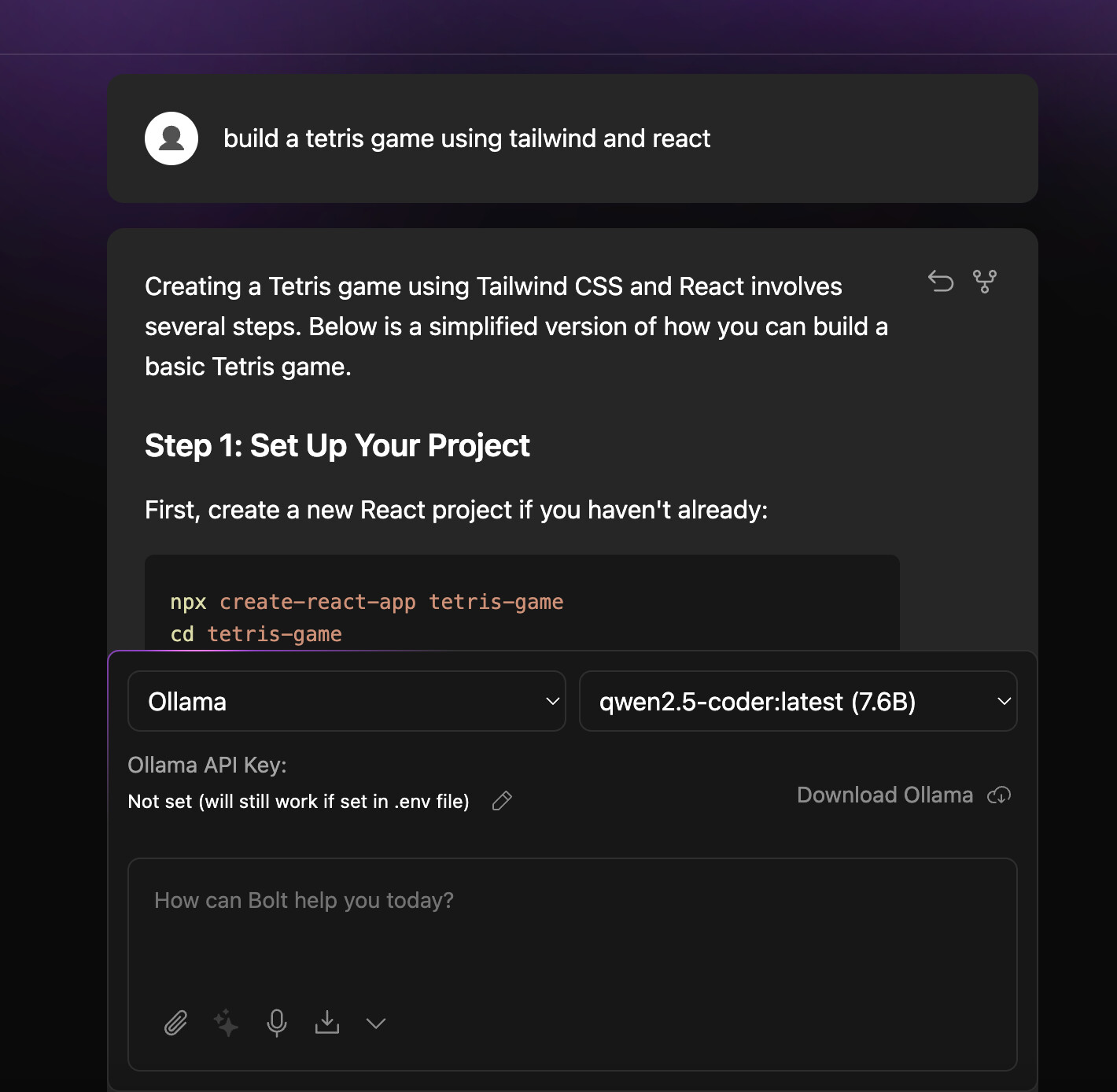
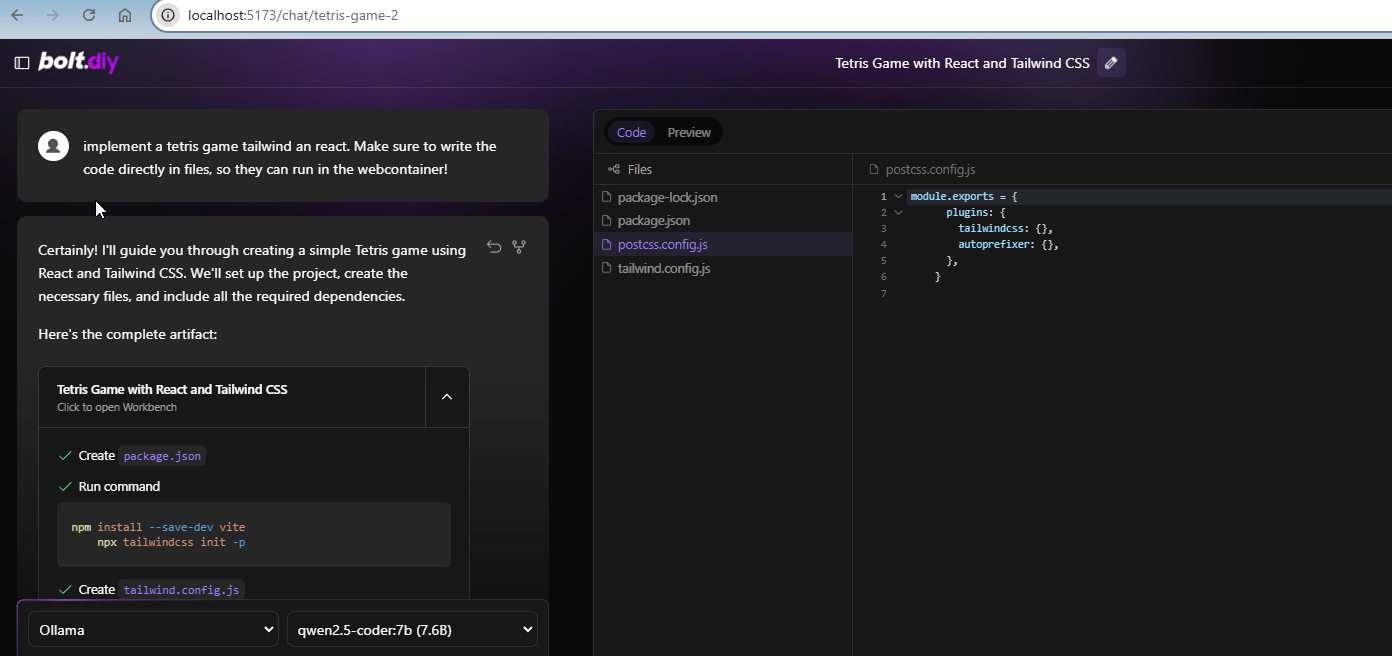
I could verify it. Same for me with your prompt, but if you enhance your prompt a bit you can get it working:
Implement a tetris game tailwind an react. Make sure to write the code directly in files, so they can run in the webcontainer!
PS: I agree that bolt.diy should this handle itself instead of enhancing the prompt yourself for smaller LLMs
I was working on optimized system prompt, which is when i tested these models thoroughly, 3B and 7B models doesn’t always follow the artifact instructions well. and that happens 90% of the time it doesn’t create an artifact. llama 3.2 3B works sometimes but not always
I had good luck with a new model. A few days back I mentioned QwQ seemed promising, but did not interact with the shell. Interestingly, two Instruct models based on it were just posted on HuggingFace:
Both Models interact with the Terminal and files, which is quite fascinating. The 7B did it constantly whereas the 3B model struggled every now and again. But very promising to see in such a small model. You can’t get them through the Serverless API though, so they have to be ran locally. But the 7B was very light and used only ~1.4GB of RAM.
But of course you aren’t going to get the output of larger models, but they are surprisingly good for the size (from my limited testing). I can’t wait until a 14B or 32B Instruct model drops. Might need to bite the bullet and built them, lol.
yeah… models are getting better in quality and smaller in sizes. I am waiting for 7B and 3B llama 3.3 models. llama 3.3 70B is comparable to 405B llama 3.2, so it will be interesting to see how the smaller variants performs
OOOh! very exciting test to be run later on then. I have been running everything on a underpowered laptop without GPU etc just to try it out. I will now move bolt.diy to my desktop as it has a GPU and more RAM. I will report back and will try the LLMs you suggested above.
VERY EXCITING!!!
Sounds great @ottomator79, let us know how it goes!