When I use Bolt in my application to fix an issue in a specific file, such as ProfilePage.tsx, and Bolt modifies exactly this file, an excessive number of tokens are consumed during the process.
Hi,
Thank you for your detailed response! I appreciate the information regarding the token usage and the ongoing optimizations. It’s great to hear that improvements are being made.
However, what I don’t understand is how the high token consumption occurs and what is sent to the LLM when only one code file is affected by a change. In bolt.new, this was handled better. I look forward to testing the experimental features in the Main Branch.
the prompt tokens includes the system prompt as well as the the entire chat history which includes all the writes and rewrites of file content done till now. so if your chat is long the token usage increases.
but like @leex279 said we are working on experimental context optimization which aims to reduce this
Firstly, can I just say how cool Bolt.diy is - coming over from Pinegrow (which is good too) it’s a heck of a lot quicker to learn/experiment with.
Now, probably a dumb question - I am using deepseek (although also was with GPT4.0) but my queries (even really simple) are turning out really fat, and i’m hitting the max token error on almost every submission? I cleared chat history and reimported my project as per last download (it’s still small and rudimentary - i’m no coder (obvs)).
I couldn’t see how to trim, or limit the query size sent to GPT, so tried deekseek (higher limits) but soon hit them too
I’m clearly doing something wrong here (p.s. also used AI enhance prompt where i could too).
Hi @GJW,
you not doing something wrong. The feature is very new and without it was/is like you describe, cause bolt sent always everything again to the llm.
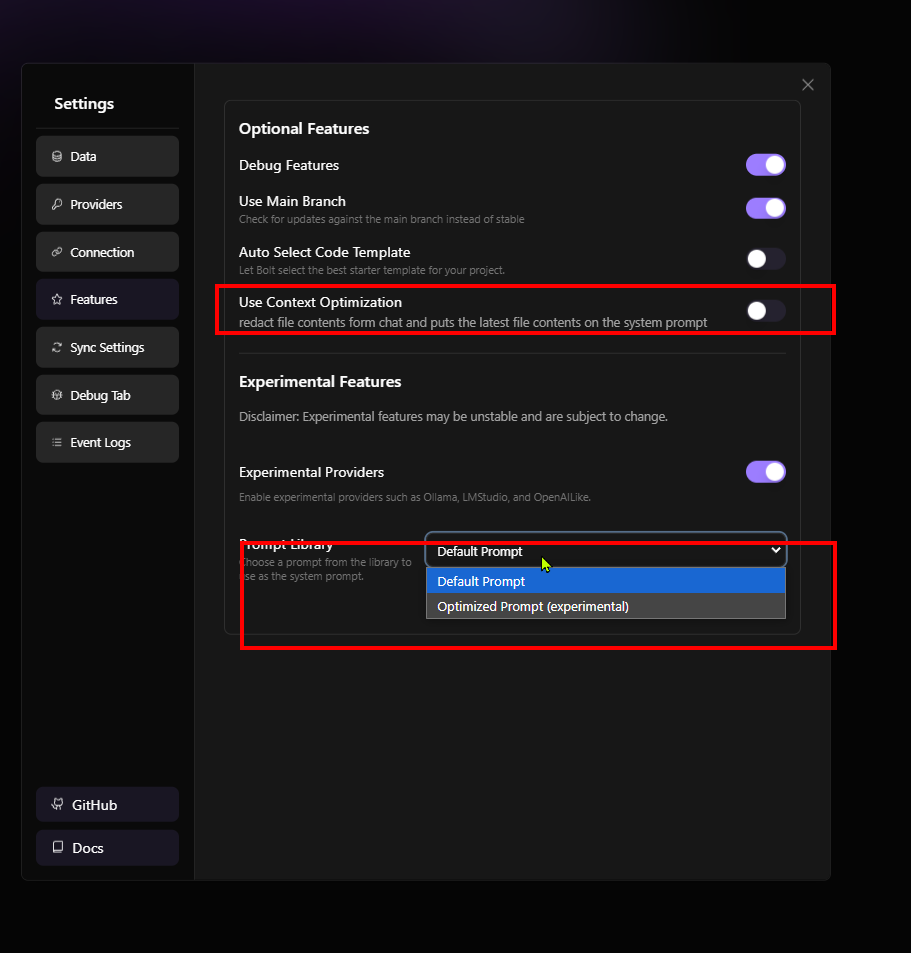
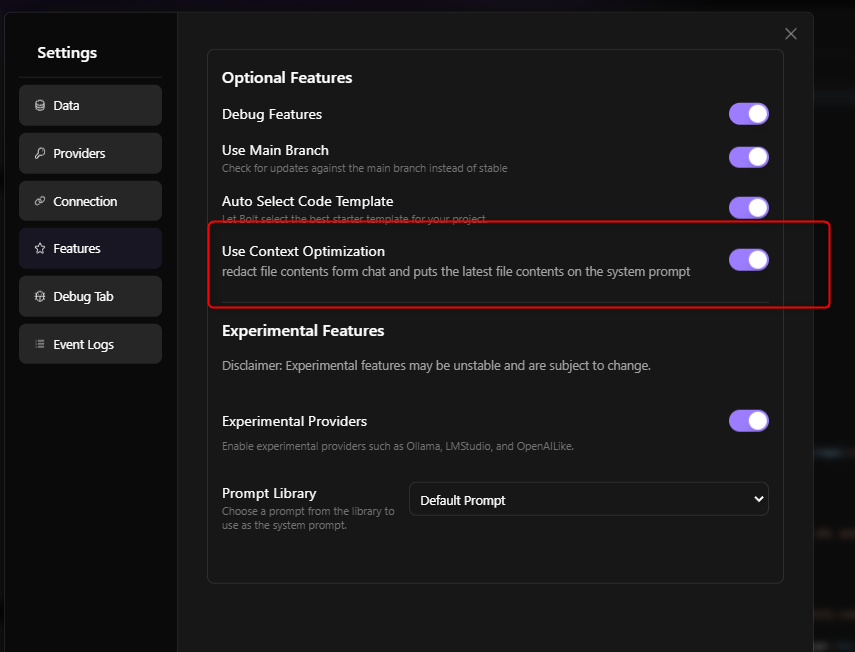
Yesterday came the new v0.0.6 Version. Make sure you got these and activate the Context Optimization in Feature Settings:
Hey guys, complete newbie to all of this. Never wrote a single line of code before, but I managed to somehow download bolt.diy locally on my computer last night successfully & have been playing around with it since. I have no idea how to use docker, but it seems people are having a better UI experience there.
My question is about optimizing tokens on the local platform. I’m currently using OpenAI API because I’m experiencing some trouble with deepseek, but as soon as I start making real progress on a project, I get hit with a token limit error message & I can no longer continue with that chat.
I notice people have mentioned adding some code to help fix this, but I don’t even know where to paste that code in my local bolt.diy. I don’t see the same UI experience being shared in the screenshots here, nor do I see a settings panel in the local bolt.diy, so I’m a bit lost.
Please be patient with me because this is all extremely new to me & I have no idea what I’m doing here.
The settings option is accessed by moving your mouse cursor to the far left and a panel will pop out. You will see a gear icon and a light/dark mode toggle at the bottom. Select the gear icon → Features and make sure optimized prompt is enabled. That may help.