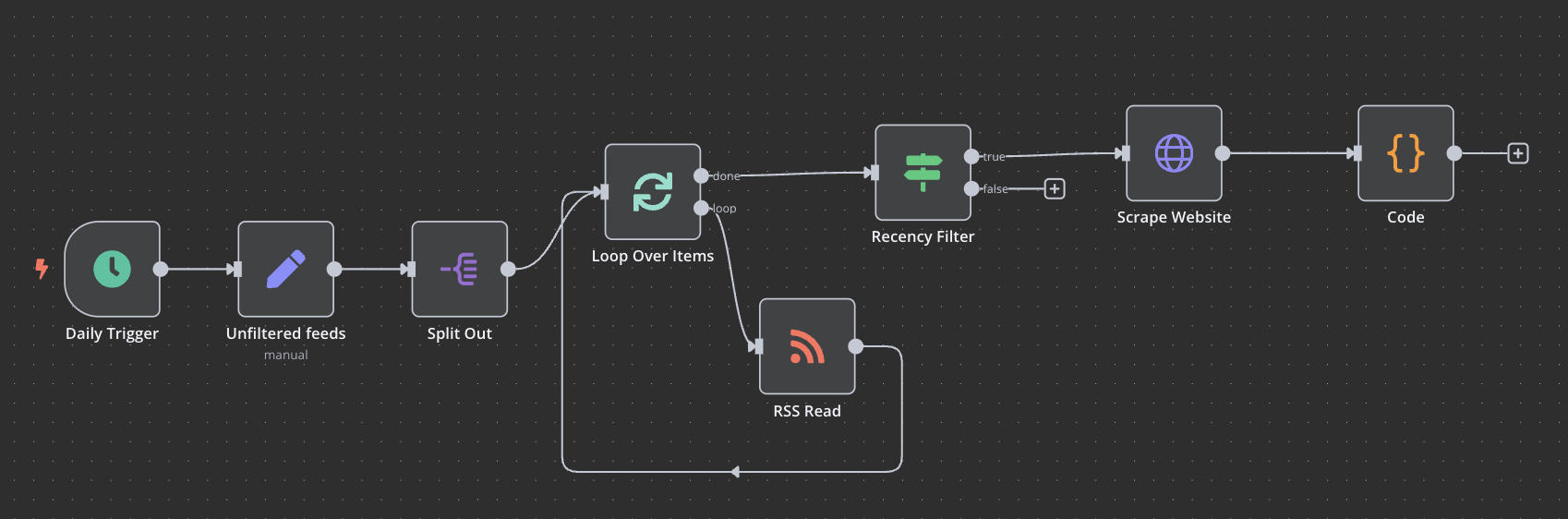
Keen to have the community’s advice. I was thrilled to get Cole’s Ultimate n8n RAG AI agent working, but I’d like to adapt it so that the content from various RSS feeds are ingested into the RAG system. I expect this involves passing the link from each RSS item into an HTTP node to scrape the content, and then using a code node to clean up the tags and metadata (I prompted Claude to generate javascript for this purpose).
I’ve experimented with the partial workflow below (if working I would plug it into the RAG AI workflow). I have no experience with scraping, but it doesn’t seem promising. I get various occasional errors from the HTTP node (e.g. “The connection to the server was closed unexpectedly, perhaps it is offline. You can retry the request immediately or wait and retry later. [item 5]”). Also some items’ content remains a mess with tags and metadata, even after being processed by the subsequent node.
Is there any hope of getting this working with the n8n native nodes, or is it necessary to use a 3rd party scraping API?
Another thing I tried was constructing Google news RSS feeds, but these result in redirect URLs that the n8n HTTP request node can’t handle properly when “follow redirects” is enabled.
Honestly for this I’d recommend a third party scraping service! You could even use an MCP server for Firecrawl within n8n! Google “n8n mcp node” and you’ll see what I mean.
Thanks for the pointer. For some reason I could never get the Firecrawl MCP tool working properly (based on Youtube tutorials by other ppl). It returns stuff like “Sorry, I couldn’t retrieve the content from the link. Please try again later” or something about the prompt containing too many tokens for the model’s maximum context length (i don’t even have a long prompt).
I’ve also tried your Crawl4AI workflow. It works, but when looping through a large number of items, it eventually throws out an error “The resource you are requesting could not be found Task not found”.
I’m new to all this and hoping to scrape just the article content from predominantly news sites. I’m guessing that Firecrawl would do a better job, while Crawl4AI would scrape the entire contents.
I do have the solution to your Crawl4AI issue though! When it eventually says the resource cannot be found, that’s because your instance hosting Crawl4AI ran out of CPU/memory. You can adjust the maximum memory used by Crawl4AI with a parameter for your container.
Thanks Cole. I had Crawl4AI set up on digitaocean with the $12 instance size plan. I don’t know if I’m jinxed or what…I went up incrementally to the most expensive option, but still - eventually I get the error after a few items (The resource you are requesting could not be found Task not found).
Since it’s presumably crawling one page at a time in a loop, I would have expected the resource intensity to be pretty stable.