I’ve seen a lot of benchmarks on LLM’s but it bothers me there is no single list you can find for all of them. Maybe I could do some scraping to build that… the benchmark I have been the most interested in is HumanEval for Coding. And it got me thinking, the top 5 spots are using a workflow approach, two using Multi-Agent and two/three using Agent-Debugging/Testing. Note also, that #4 uses DeepSeek-Coder-v2-Lite and will likely rank to #1 with the latest V3. And if true, that would mean an almost perfect eval.
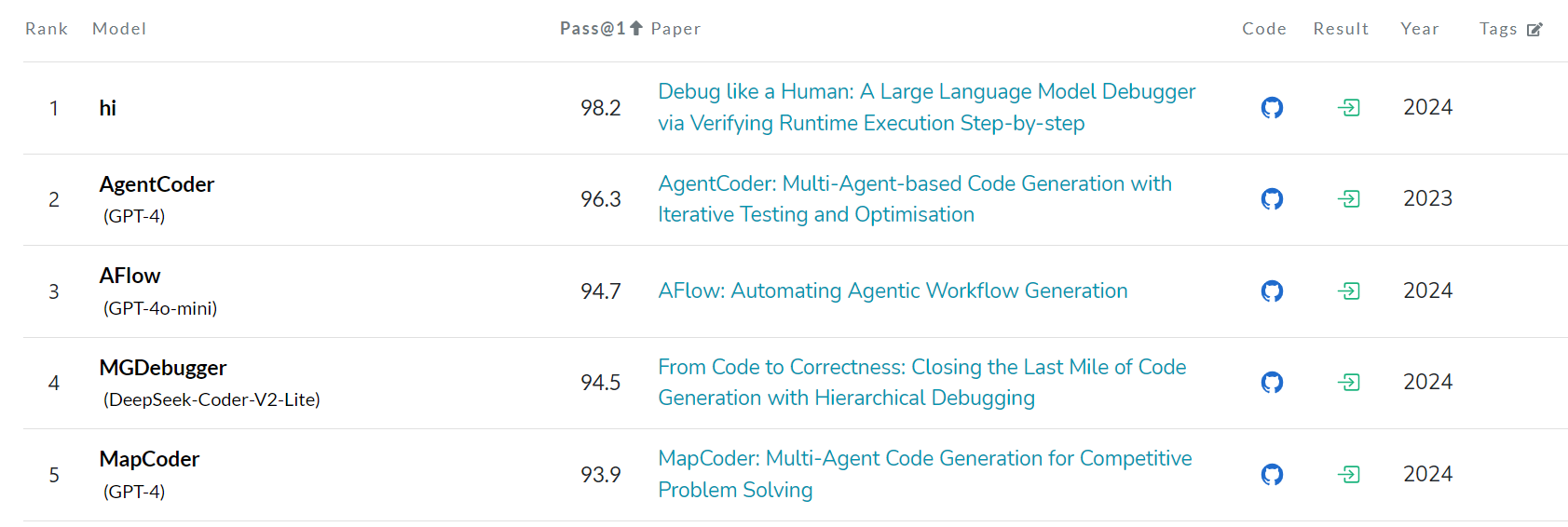
HumanEval Benchmark (Code Generation) | Papers With Code
And all these aproaches are fully documented with code available on GitHub:
- Floridsleeves/LlmDebugger
- AgentCoder
- Geekan/MetaGPT
- YerbaPage/MGDebugger
- md-ashraful-pramanik/mapcoder
- Luoji-zju/Agents4PLC
So, it would be a shame not to utilize them.
DeepSeek-V3 for example has shown very impressive results and it’s not even Instruct fine-tuned yet or available into Quantized version… and yet it’s also super cheap (the cheapest for the results) through Openrouter for < 20¢/MTok.
However, when it comes to real-world applications, benchmark tools fail to capture reality; a project is not a single task solved by a one-shot eval. Often AI fails at tasks because they are made up of many parts and failing even one step results in AI often getting deadlocked.
But with all that being said, I think we are likely very close to functional AGI for all intents and purposes, which to me is the ability for AI to complete projects and tasks without input from a human operator, which leads to the system being able to self-improve. I personally don’t think that removes the role of the developer though, it simply allows them to do more.
Thoughts?