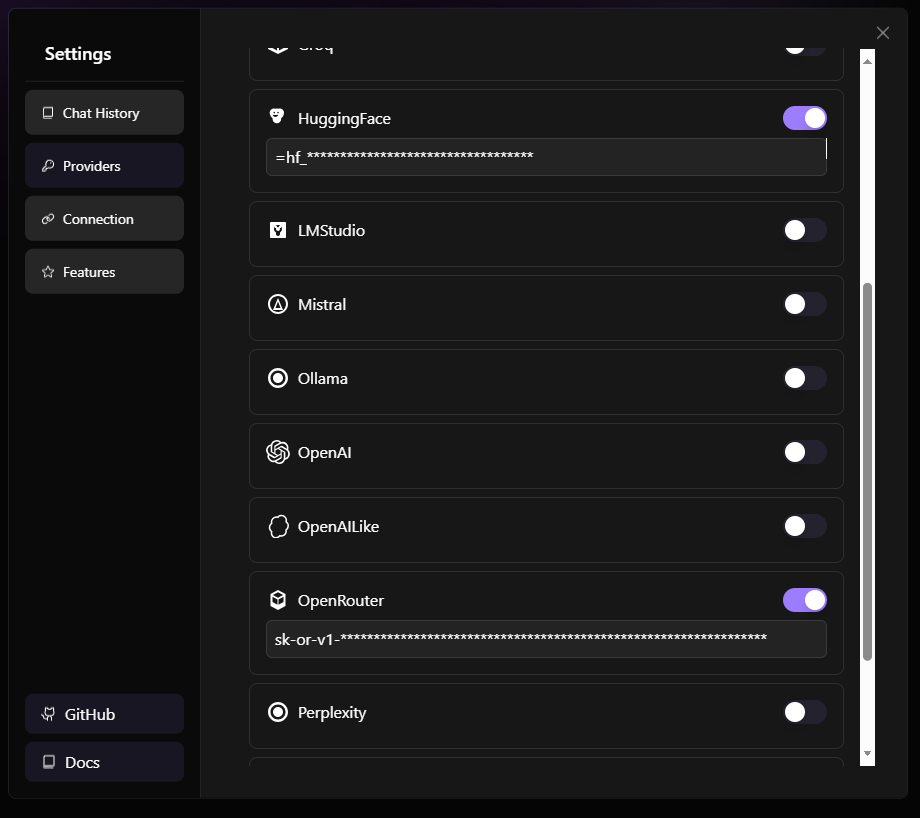
For HuggingFace models, I took a look.
I can filter the list from 1211176 to 3194 records, but there is no ability to filter by “Serverless” endpoints. So, some logic to search the records would be needed to check them and build a cache.
Pre-filter Criteria:
- pipeline_tag=text-generation
- library=transformers
- other=endpoints_compatible
- language=en
- search=instruct
- inference_api=true"
Additional Filter
- Interface API (serverless): requires checking the response
- Excludes: GGUF, GPTQ, AWQ, 4Bit, 4/8Int (Quantized) Models and those under 7B parameters.
hf_prefixes.json Code:
"provider_prefixes": [
"codellama",
"HuggingFaceTB",
"deepseek-ai",
"dnotitia",
"meta-llama",
"microsoft",
"mistralai",
"Qwen",
"tiiuae",
"unsloth"
]
script.js Code:
import fetch from "node-fetch";
import fs from "fs";
import path from "path";
// Define paths for cache and stats files
const CACHE_FILE = "./hf_cache.json";
const STATS_FILE = "./hf_stats.json";
const PROVIDER_PREFIXES_FILE = "./hf_prefixes.json";
const API_URL = "https://huggingface.co/api/models?pipeline_tag=text-generation&library=safetensors&transformers&other=endpoints_compatible&language=en&search=instruct&inference_api=true";
const useProviderPrefixes = true;
// Fetch models from the API
async function fetchModels() {
try {
const response = await fetch(API_URL);
const models = await response.json();
if (!models || models.length === 0) {
console.log("No models found in the API response.");
return [];
}
console.log("Found models: ", models.length);
return models;
} catch (error) {
console.error("Error fetching models: ", error);
return [];
}
}
// Check if the model is serverless
async function isServerlessModel(model) {
if (model && model.tags && model.tags.includes("endpoints_compatible")) {
return true;
}
return false;
}
// Simplify model data to only the required fields
function simplifyModelData(model) {
return {
modelId: model.modelId,
};
}
// Generate stats and write to stats.json
function generateStats(serverlessModels) {
const stats = {
totalModels: serverlessModels.length,
uniqueIds: new Set(serverlessModels.map(model => model.modelId)).size,
maxLikes: Math.max(...serverlessModels.map(model => model.likes), 0),
maxDownloads: Math.max(...serverlessModels.map(model => model.downloads), 0),
averageLikes: serverlessModels.reduce((sum, model) => sum + model.likes, 0) / serverlessModels.length || 0,
averageDownloads: serverlessModels.reduce((sum, model) => sum + model.downloads, 0) / serverlessModels.length || 0,
};
fs.writeFileSync(STATS_FILE, JSON.stringify(stats, null, 2));
console.log("Stats generated:", stats);
}
// Read provider prefixes from the json file
function getProviderPrefixes() {
try {
const data = fs.readFileSync(PROVIDER_PREFIXES_FILE, "utf8");
const json = JSON.parse(data);
return json.provider_prefixes || [];
} catch (error) {
console.error("Error reading provider prefixes:", error);
return [];
}
}
// Extract and validate the parameter size
function isValidSize(modelId) {
const sizeMatch = modelId.match(/(\d+(\.\d+)?)b/i); // Match for parameter sizes like 7B, 10B, 1.5B
if (sizeMatch) {
const size = parseFloat(sizeMatch[1]);
return size >= 7; // only accept models >= 7B
}
return false;
}
// Fetch and cache serverless models
async function fetchServerlessModels(refreshCache = false) {
if (!refreshCache && fs.existsSync(CACHE_FILE)) {
console.log("Cache exists, loading models from cache...");
const cachedData = JSON.parse(fs.readFileSync(CACHE_FILE, "utf8"));
generateStats(cachedData);
return cachedData;
}
console.log("Fetching models from Hugging Face API...");
const models = await fetchModels();
if (models.length === 0) return [];
const serverlessModels = [];
const providerPrefixes = useProviderPrefixes ? getProviderPrefixes() : [];
for (const model of models) {
const modelId = model.modelId.toLowerCase();
// Exclude quantized tags in modelId
const isExcluded =
modelId.includes("-awq") ||
modelId.includes("-4bit") ||
modelId.includes("-bf16") ||
modelId.includes("-fp8") ||
modelId.includes("-dpo") ||
modelId.includes("-gptq") ||
modelId.includes("-int4") ||
modelId.includes("-int8") ||
modelId.includes("-quantized") ||
modelId.includes("gguf") ||
/(\d+\.\d+bit)s?/.test(modelId); // Excludes XX.XXbit(s) in modelId
if (isExcluded || !isValidSize(modelId)) {
continue; // Skip models quantized and < 7B Parameters
}
const isProviderValid = useProviderPrefixes ? providerPrefixes.some(prefix => modelId.startsWith(prefix.toLowerCase())) : true;
if (isProviderValid) {
const isServerless = await isServerlessModel(model);
if (isServerless) {
serverlessModels.push(simplifyModelData(model)); // Use simplified model data
}
}
}
if (serverlessModels.length > 0) {
// Sort the models alphabetically by modelId
serverlessModels.sort((a, b) => a.modelId.localeCompare(b.modelId));
try {
fs.writeFileSync(CACHE_FILE, JSON.stringify(serverlessModels, null, 2));
console.log("Serverless models cached successfully.");
generateStats(serverlessModels); // Generate stats after caching
} catch (error) {
console.error("Error writing cache file:", error);
}
}
return serverlessModels;
}
// Trigger fetch only if cache doesn't exist or on command to refresh
fetchServerlessModels().then((serverlessModels) => {
if (serverlessModels.length === 0) {
console.log("No serverless models found.");
} else {
console.log("Serverless Models:", serverlessModels.length ? serverlessModels : "None found");
}
});
Returns 38 results (318 without prefix/provider filter; sorted):
Serverless Models: [
{ modelId: 'deepseek-ai/deepseek-coder-33b-instruct' },
{ modelId: 'deepseek-ai/deepseek-coder-7b-instruct-v1.5' },
{ modelId: 'deepseek-ai/deepseek-math-7b-instruct' },
{ modelId: 'dnotitia/Llama-DNA-1.0-8B-Instruct' },
{ modelId: 'meta-llama/CodeLlama-13b-Instruct-hf' },
{ modelId: 'meta-llama/CodeLlama-34b-Instruct-hf' },
{ modelId: 'meta-llama/CodeLlama-70b-Instruct-hf' },
{ modelId: 'meta-llama/CodeLlama-7b-Instruct-hf' },
{ modelId: 'meta-llama/Llama-3.1-405B-Instruct' },
{ modelId: 'meta-llama/Llama-3.1-70B-Instruct' },
{ modelId: 'meta-llama/Llama-3.1-8B-Instruct' },
{ modelId: 'meta-llama/Llama-3.3-70B-Instruct' },
{ modelId: 'meta-llama/Meta-Llama-3-70B-Instruct' },
{ modelId: 'meta-llama/Meta-Llama-3-8B-Instruct' },
{ modelId: 'mistralai/Mistral-7B-Instruct-v0.1' },
{ modelId: 'mistralai/Mistral-7B-Instruct-v0.2' },
{ modelId: 'mistralai/Mistral-7B-Instruct-v0.3' },
{ modelId: 'mistralai/Mixtral-8x22B-Instruct-v0.1' },
{ modelId: 'mistralai/Mixtral-8x7B-Instruct-v0.1' },
{ modelId: 'Qwen/Qwen2-57B-A14B-Instruct' },
{ modelId: 'Qwen/Qwen2-72B-Instruct' },
{ modelId: 'Qwen/Qwen2-7B-Instruct' },
{ modelId: 'Qwen/Qwen2-Math-72B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-14B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-32B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-72B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-7B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-Coder-14B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-Coder-32B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-Coder-7B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-Math-72B-Instruct' },
{ modelId: 'Qwen/Qwen2.5-Math-7B-Instruct' },
{ modelId: 'tiiuae/falcon-40b-instruct' },
{ modelId: 'tiiuae/falcon-7b-instruct' },
{ modelId: 'tiiuae/falcon-mamba-7b-instruct' },
{ modelId: 'tiiuae/Falcon3-10B-Instruct' },
{ modelId: 'tiiuae/Falcon3-7B-Instruct' },
{ modelId: 'tiiuae/Falcon3-Mamba-7B-Instruct' }
]
P.S. I did try parsing each site for the “Serverless” dropdown button, but it proved to be much slower. The method I did here takes <1 second and after the initial cache, doesn’t need to run unless triggered. So, after thinking about this, it could be executed in the build step and just cached for no performance penalty.
Maybe also filter by date and only keep those after a certain one or say updated within a year.