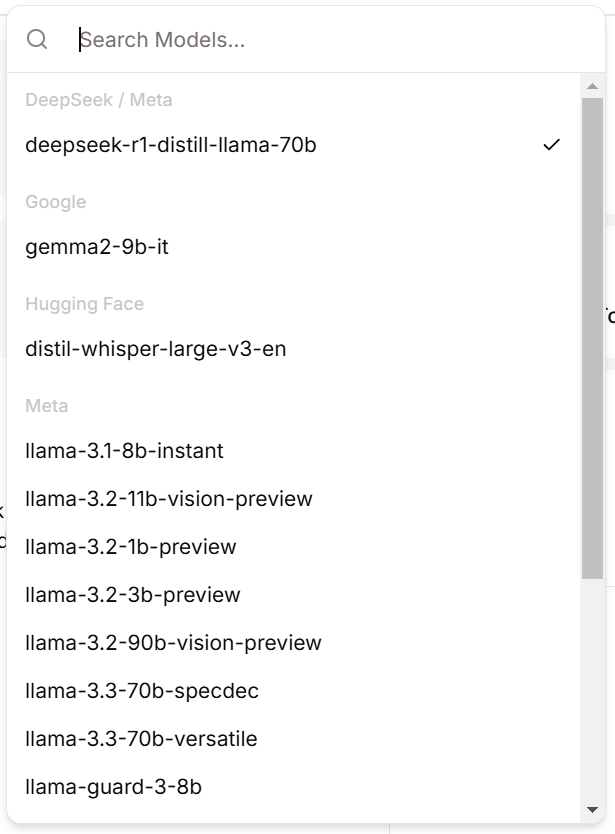
I would like to use the latest “deepseek-r1-distill-llama-70b” model from Groq Playground:
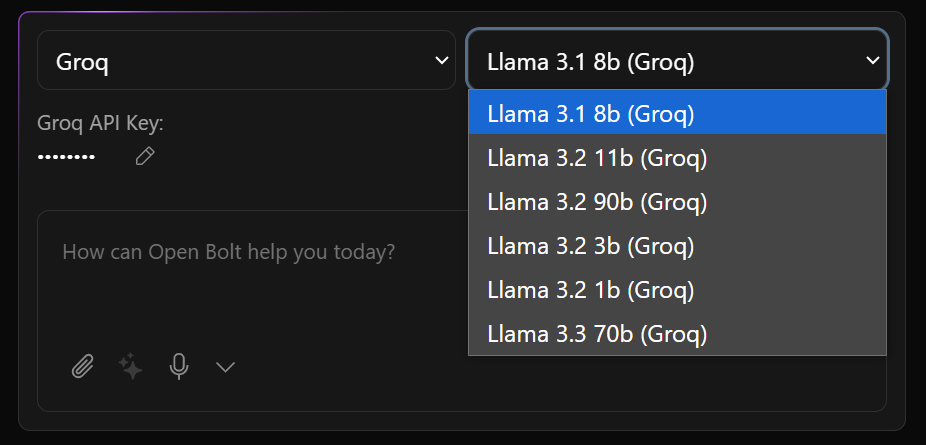
But it doesn’t show in the Groq Provider dropdown list in Bolt.diy (latest versions, either stable or main):
Because it’s API is still free right now (though limited) and it currently has no daily Token limit, just number of completions and rating limiting:
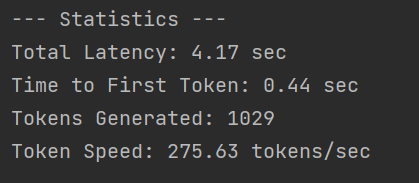
I tested this in Python and the results are very good (for FREE, lol):
And I also tested this out in Roo Code (Cline fork) last night and used no joke over 4.65 Million Tokens (Cline is very inefficient at token usage). From my testing Bolt.diy and Aider use a fraction of as many tokens.
@aliasfox for me it is showing 
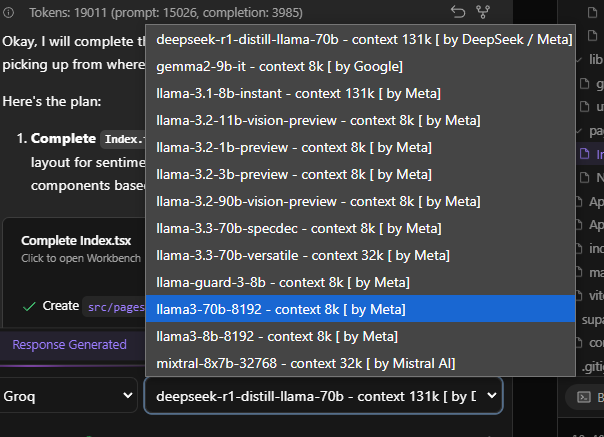
1 Like
I reached the token limit very fast:
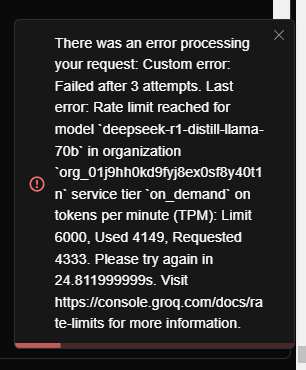
so not very usable after you got a initial app build.
1 Like
Like I said, there is a “rate limit” (30 requests per Minute and 1,000 requests per day, so a bunch of small requests will eat that up) but no “token” limit. Slow down, how fast did you reach 20K Tokens? lol
And I’ll try again. Thanks!
I did not watch, but slowing down feels not like a way I want to do with bolt.diy when I try to implement something  I want to get something done and not wait forever
I want to get something done and not wait forever
Just saying, that was a lot of token usage. Were you using optimized prompts and whatnot?
was on optimized prompt and also did nothing for a longer time now. postet 3 errors from dev-console and it could not even do that.
So this is at least for me no option at all.
1 Like
Thanks, I’ll test it out but maybe I’ll keep doing it the way I was. Still not as a bad as Cline/Roo Code on raw token usage but I wonder how many requests per second Bolt.diy makes to the API.
Thats a question for @thecodacus 
for if context optimization is enabled then it uses 3 calls per request
one to summarize the chat, one to finalize the code buffer then the final implementation
and just an fyi, the token usage stats shows the combined token counts of all 3 calls. not just the final one.
so all 3 calls take around 10k~15k tokens on a medium codebase
I didn’t know groq rate limits on request count. I thought I was using too many tokens per minutes 
Yeah, likely tokens per minute is the limiting factor (6K tokens)… but this also means about 10 requests (at 3 each @ 30 limit) per minute limit too. So maybe too limiting to use in real world use cases but was cool and Groq is blazing fast.
1 Like