Managing files is at the core of Bolt.
Since we already had a couple of PRs/improvements which deal with files and we faced alternative implementation principles, I thought it might be worth to discuss how this should be handled architecturally in order to improve further down the road.
I’m not an expert in the bolt-architecture, so this is my current understanding. I welcome every correction!
Status quo
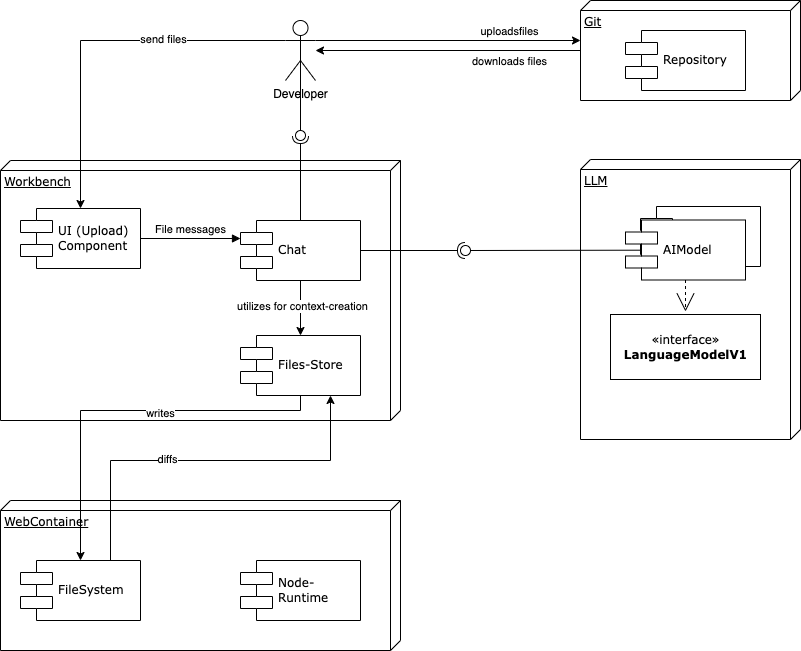
I’ll try to sketch what’s currently there:
Different stages
When talking about “files”, we actually talk about three different locations / stages:
- Files inside the web container. These are the files which are available to the engine that runs the application under development (vite, webpack.). I call the “webcontainer-files”.
- Files within the bolt-application. The component is called “workbench” in the original code, so let’s call them “workbench files”.
- Then, there’s the files content. It makes up the context that is sent to the LLM for inference. In order to do that, the content is translated into specially tagged chat messages. Let’s call them “context files”.
- Files that reside outside the application, e. g. in a git repository or on the local file-system. I call them “remote files”.
Existing mechanisms
-
Webcontainer-filesystem
The webcontainer is accessible from~/lib/webcontainerand provides a file-system APIawait wc.fs.writeFile(entryPath, content). -
The files store in the workbench
Inapp/lib/stores/files.ts, there’s already a mechanism that syncs workbench-files with webcontainer-files: If t file is modified inside the workbench (e. g. by editing it in the right-hand-side editor), it’s tracked using#modifiedFiles. When sending the next message, these files are diffed and this diff is sent to the LLM as context-file -
Direct manipulation of messages
Current implementations of file-upload / sync of remote files has been done by creating special chat messages (<boltArtifact>)
Why should we think
It seems there is no mechanism in place to keep files in sync both ways, from a remote down to the webcontainer – and vice versa.
However, we’re going to see a need to make this a stable process going forwards (thinking about undo/redo, reloads of the page and a workflow back to the developer’s local or remote repo).
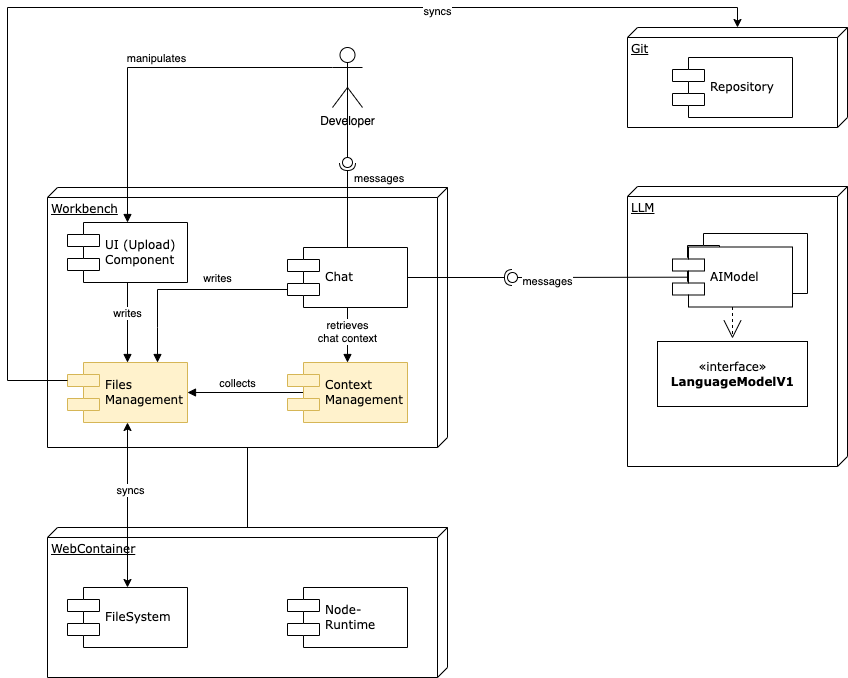
Ideas
A files-façade
If there was an API in place, which made sure that files are propagated throughout the whole stack, we’d be much more flexible to add processes. I’d propose to provide a façade (maybe as a hook) which allows to push files into the workbench (and implicitly propagates them to context and wc)
Use of git within the full chain
Git is made for managing different storage locations, including conflict resolution. @thecodacus introduced isomrphic-git recently, so we would check whether implementing the façade by means of git was an option: a commit could be used as transport container for changes also between workbench and webcontainer, not only to the remotes.
If changes e. g. had been performed in the webcontainer (which should in future also trigger a commit via the façade), a push from the workbench to the wc could trigger the well-known conflict resolution mechannisms
A git commit could also be created after each prompt (with the prompt and meta-information about the model as commit-message). This would also allow for proper undo and allow for a transparent development workflow.
Your ideas?
I’m very sure that at least @wonderwhy.er and @thecodacus have already had ideas themselves, so I’d much like to read from you!
Cheers,
Oliver