First of all , Thank you OTTODEV |OTTOMATOR team for your hard work ![]()
![]()
![]()
My issue:
I wanted to use bolt.diy locally then I followed the instruction , in this video of @Cole Medin in youtube How to Use Bolt.new for FREE with Local LLMs (And NO Rate Limits) step by step, and I had ollama is running in port:11434
The steps I did :
Note : I have Node and Git in my machine:
git -v
// git version 2.43.0
node -v
// v18.20.4 // this the defalut i have also downloaded v 22
1- Clone the repo:
git clone https://github.com/stackblitz-labs/bolt.diy.git
cd bolt.diy
2 - Doownload Ollama:
curl -fsSL https://ollama.com/install.sh | sh
3- Pull the LLM to the target folder
ollama pull qwen2.5-coder
ollama create -f Modelfile qwen2.5-coder:7b
4 - Create modelfile using Vscode in the target repo:
# bolt.diy/Modelfile
FROM qwen2.5-coder:7b
PARAMETER num_ctx 32768
4 - Ensure LLM is runnig :
ollama list
// output is:
// NAME ID SIZE MODIFIED
//qwen2.5-coder:latest 2bxxxx37 4.7 GB 11 seconds ago
//qwen2.5-large:7b c00xxxxa0 4.7 GB 8 days ago
$ ollama pull qwen2.5-coder:latest
pulling manifest
pulling 60exxxxxx07... 100% ▕████████████████▏ 4.7 GB
pulling 66bxxxxxb5b... 100% ▕████████████████▏ 68 B
pulling e94xxxxx327... 100% ▕████████████████▏ 1.6 KB
pulling 83xxxxxxa68... 100% ▕████████████████▏ 11 KB
pulling d9xxxxxx869... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
http://localhost:11434 #open in browser
# output is : Ollama is running
Then I followed these steps to install it: from Bolt.diy documentation
Run Without Docker
- Install dependencies using Terminal (or CMD in Windows with admin permissions):
pnpm installIf you get an error saying “command not found: pnpm” or similar, then that means pnpm isn’t installed. You can install it via this:
sudo npm install -g pnpm
- Start the application with the command:
pnpm run dev
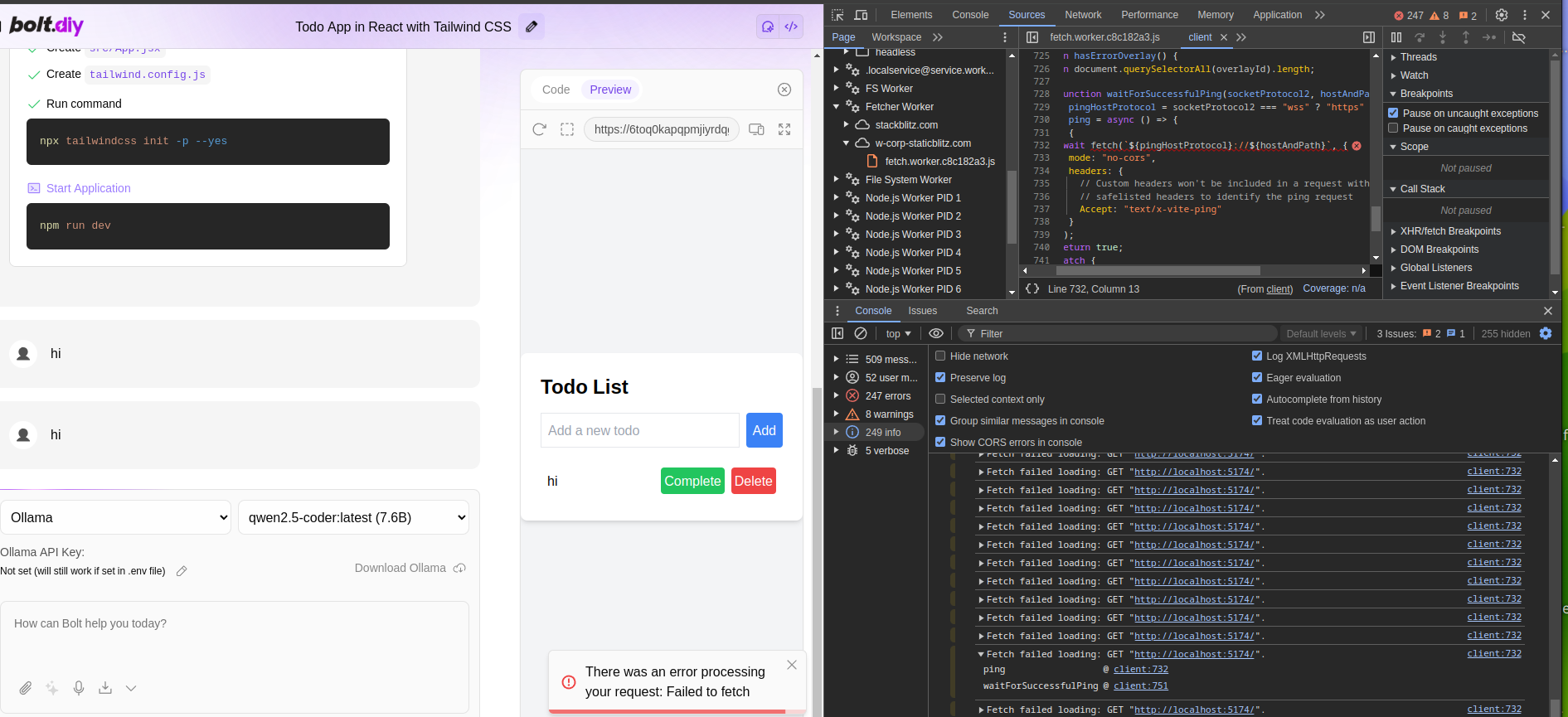
but I still get error message:
There was an error processing your request: An error occurred.
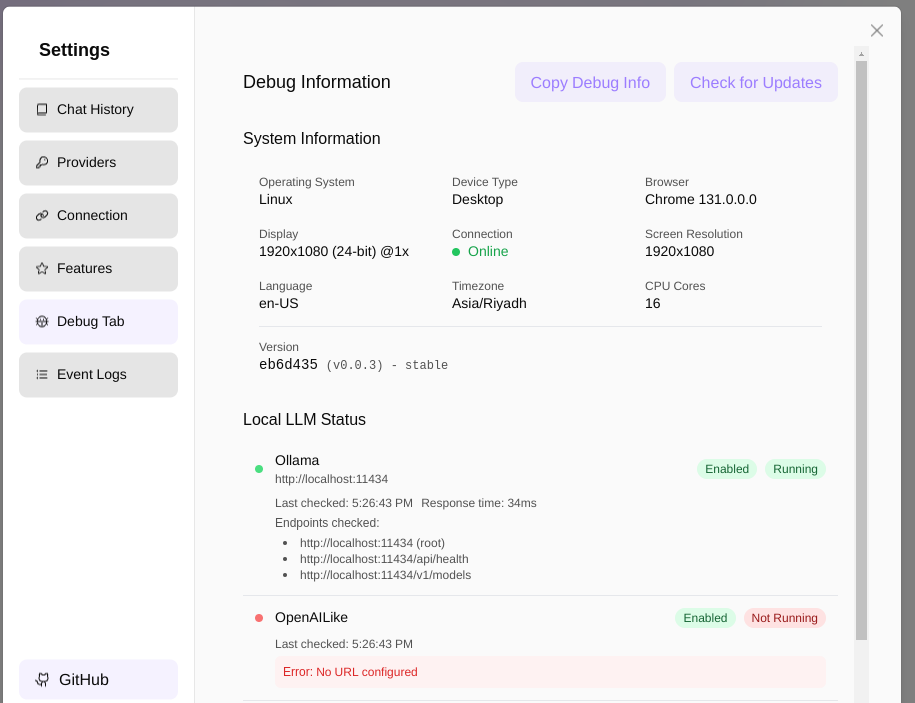
The debug info:
Also note that: if I use api key for other models , it works perfectly with no errors
But When I want to use local model that i downloaded [qwen2.5-coder:7b] , it return the error shown in the image :
There was an error processing your request: An error occurred.
Anyone could help, i woul be so grateful for the help, thank you for your great work you do to help the world ![]()
My hardware:
Ubuntu 24.04 | Ram: 32 GB DDR4| CPU : i7-11800H | GPU: 4GB Nividia (T1200)