I have noticed crawling the pydantic documentation fails on 6 pages consistently. It would be more efficient to crawl the llms.txt which contains all the documentation in a machine-readable format. You may want to check the other sites you’re considering for the project as they may have adopted this standard also.
Pydantic LLMs.txt
ai.pydantic.dev/llms.txt
Langraph LLMs.txt
LLMS-txt
2 Likes
Here is a google Dork to index other sites with an llms.txt or llms-full.txt
filetype:txt inurl:“llms” - Google Search
1 Like
I have thought of doing this, though part of the crawling for Archon specifically stores the content for each page. If everything is bunched together in llms.txt, wouldn’t it be difficult to segregate the info by page? Or are there markers for that kind of thing? I’m still learning how these llms.txt pages work myself!
1 Like
You are correct specifically with the llms-full.txt files can be rather large.
Thankfully the standard is built on the principals of markdown notation.
The process would be to split sections based on the heading Notation: For example # H1 Title ## H2 Title etc. An example from the https://llmstxt.org site
# Title
> Optional description goes here
Optional details go here
## Section name
- [Link title](https://link_url): Optional link details
## Optional
- [Link title](https://link_url)
To make it even easier there is a parser for python
pip install llms-txt
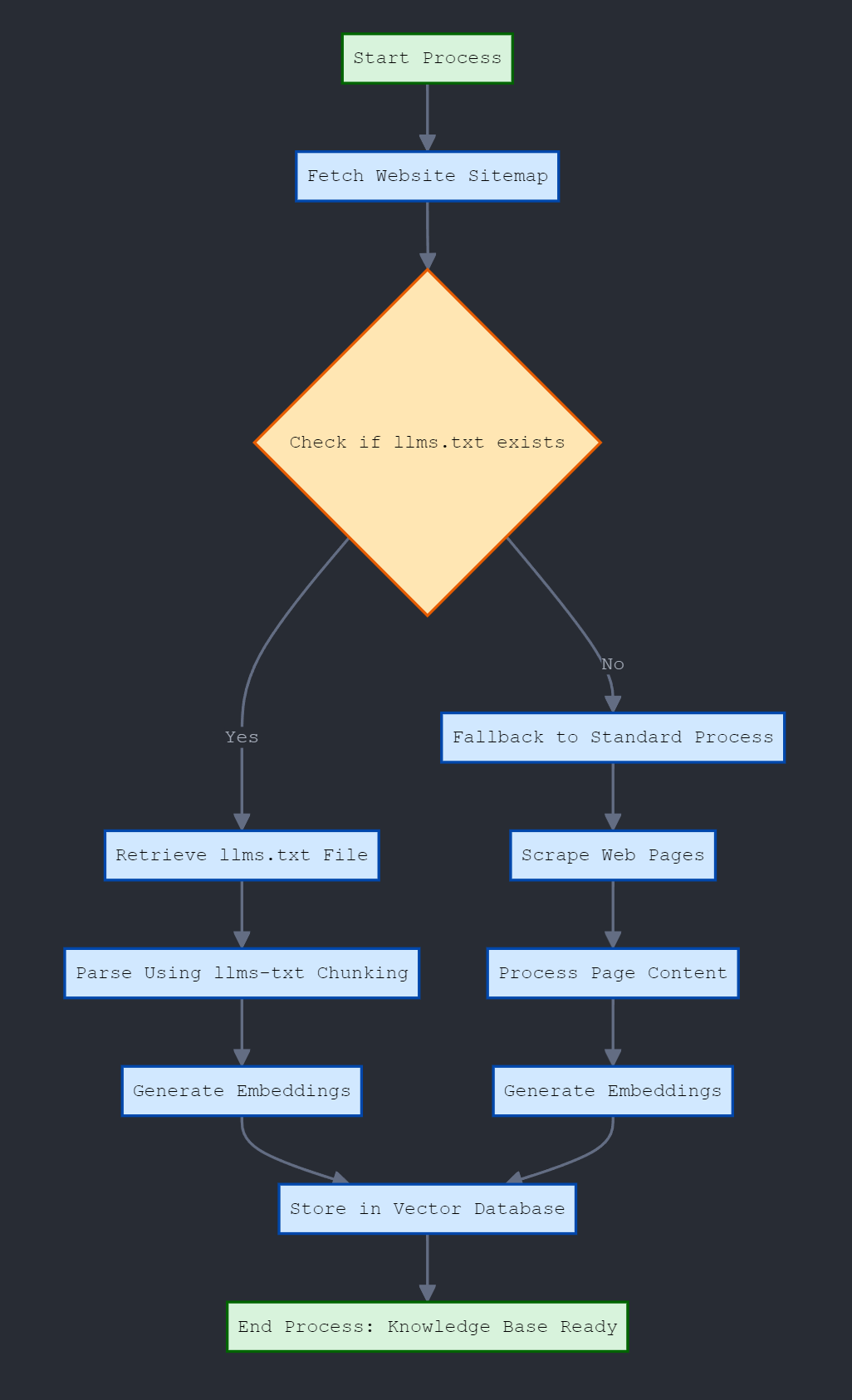
LLMs.txt takes what was unstructured multiple pages and turns it into a structured document which can be manipulated and converted in any which way. Basically, each heading becomes the category and all the text between the headings is the information you are chunking and storing in the vector db. Providing the retriever with sematic search. I haven’t seen anyone doing this yet just an idea that popped into my head yesterday.
A simple workflow would be:
2 Likes
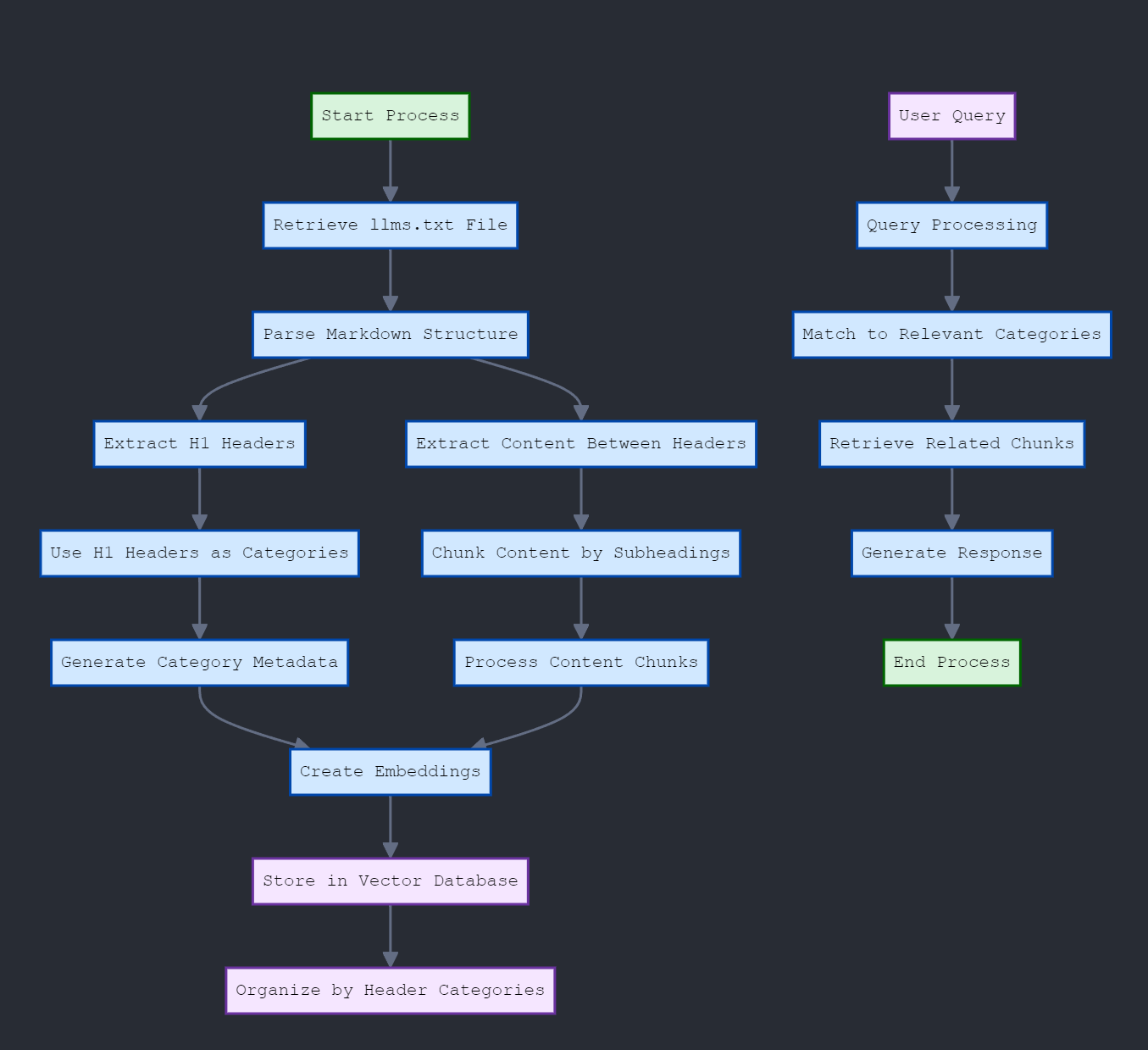
This process looks perfect, and your diagrams are beautiful haha! Seems like you really know what’s up here, any chance you would make a PR for Archon to include this functionality? ![]()
Sure, I’ll take a crack at it. I’ll have some time over the weekend to start working on it. I am curious to see if my theory holds true. Plus, it should result in a speed increase and increased retrieval accuracy.
1 Like
there was me working on a CLI ![]() I love it really.
I love it really.
But I love this I like Cole am still getting to grips with the llms.txt works. Very interesting stuff.
1 Like
Well, this looks promising so far
Step 1: Parsing document…
Step 2: Building hierarchy tree…
Step 3: Applying classification…
Processing complete.
Step 4: Generating hierarchical chunks…
- Creating initial chunks…
- Created 939 initial chunks.
- Adding hierarchical context…
- Context added.
- Establishing cross-references…
- Cross-references established.
3 Likes
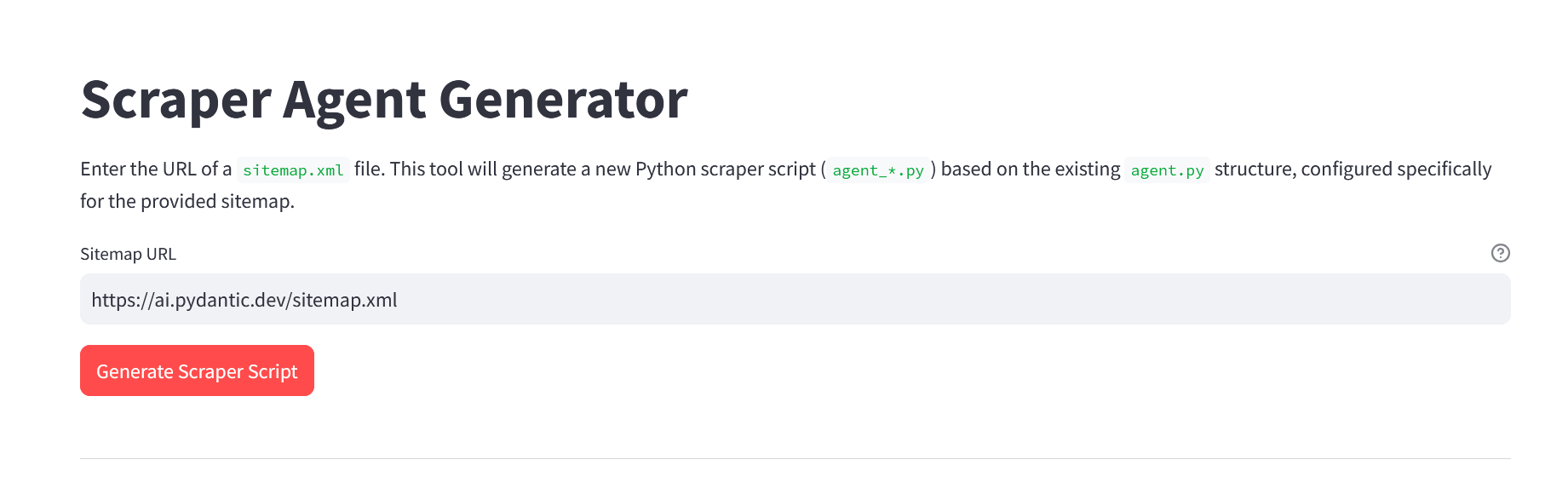
Looks great ![]() on the fallback I have finished the CLI tool for creating the crawl4ai agents and it works great giving nice clean markdown with no html left so this would work great for the fallback method. I have kept it mvp so creates the agents automatically based on sitemap if it exists it lists the chunks stored. Just using local DB atm for testing as I know some are working on this also, can we get a way to colab better? I used the HTML to structure the markdown before removal.
on the fallback I have finished the CLI tool for creating the crawl4ai agents and it works great giving nice clean markdown with no html left so this would work great for the fallback method. I have kept it mvp so creates the agents automatically based on sitemap if it exists it lists the chunks stored. Just using local DB atm for testing as I know some are working on this also, can we get a way to colab better? I used the HTML to structure the markdown before removal.
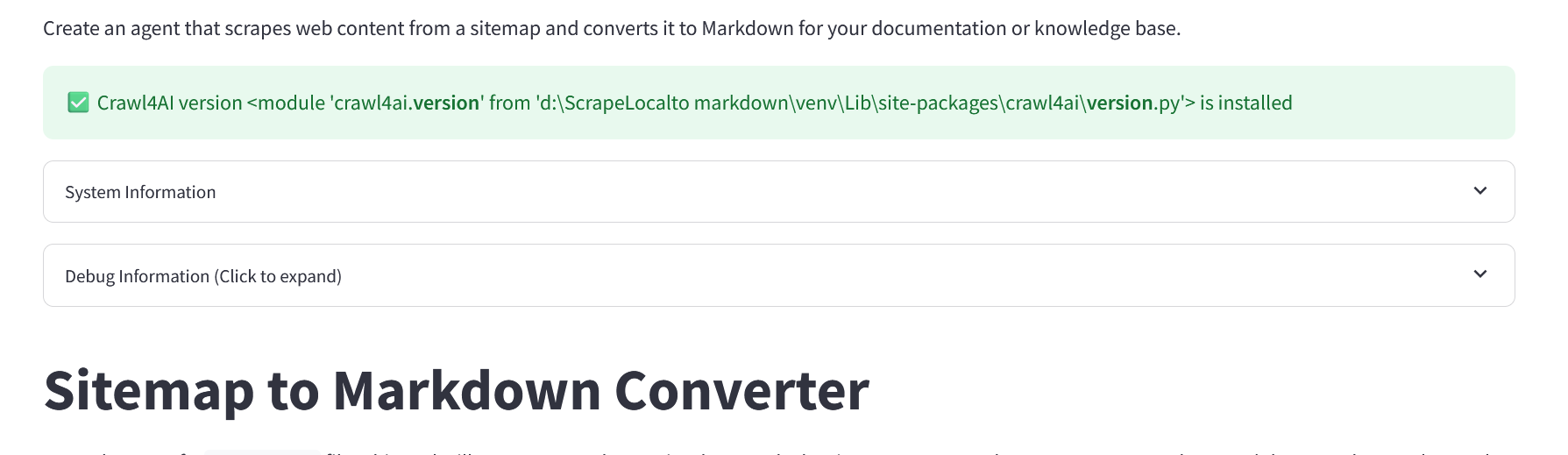
@info2 Thats looking good I got basic retrieval working tonight.
I’ll need to test a little further with a wider variety of llms.txt files
One thing that has been bothering me is with the wider adoption of llms.txt as this functionality is built into agents and tools, the potential for a malicious actor to copy and inject malicious code into a seemingly harmless document as a regular instruction would be trivial.
For example: someone spins up a fake llms.txt index site which aggregates the most popular llms.txt into an easy to access site. Some simple SEO tricks later and all the searches for Anthropic llms.txt point to the malicious site. They then modify the txt files with malicious code which will instruct the llm’s to add a backdoor to your application, or code to steal your api keys, spread malware.
There is no way to validate the llms.txt has not been modified from the original site. Web scraping is already vulnerable to this type of attack so it’s not long before this one is exploited as well. I am pondering a few options to limit the exposure.
I digress, I should have a PR in a few days for review needs more testing.
--- Running Retrieval Query ---
Query: 'how do you reset memories in crewai?'
Match Count: 10
Initializing retrieval components...
OpenAI client initialized successfully.
Using OpenAI embedding model: text-embedding-3-small
QueryProcessor: OpenAIEmbeddingGenerator initialized.
Supabase client initialized successfully.
Retrieval components initialized.
Executing retrieval...
Performing semantic search with match_count=10
Found 10 raw results.
--- Retrieval Results ---
[
{
"id": 7238,
"path": "{'title': 'Changelog', 'level': 0} > {'title': 'Memory', 'level': 1} > {'title': 'Introduction to Memory Systems in CrewAI', 'level': 2}",
"title": "Introduction to Memory Systems in CrewAI",
"content_snippet": "The crewAI framework introduces a sophisticated memory system designed to significantly enhance the capabilities of AI agents.\nThis system comprises `short-term memory`, `long-term memory`, `entity me...",
"score": 0.577142527444065
},
2 Likes
I totally agree, malicious actor using fake index sites, SEO poisoning, and injecting harmful instructions into copied llms.txt files is entirely plausible and mirrors existing web security threats like typosquatting and watering hole attacks. I think the core issue is trust and validation.
Canonical Domain Enforcement. Archon will only attempt to retrieve llms.txt from the canonical domain of the website it’s interacting with (e.g. for www.example.com, fetch https://www.example.com/llms.txt). not rely on third-party index sites for fetching these files. This directly counters the fake index site attack vector.
Strict HTTPS Enforcement: use HTTPS with proper certificate validation (checking validity, expiration, and matching the domain). This prevents Man-in-the-Middle (MitM) attacks during transit.
Instruction Sandboxing and Filtering (Limiting the Damage):
Strict Parsing and Allowlisting: Define a very strict schema for what constitutes a valid instruction in llms.txt. Reject any file that doesn’t conform precisely. Crucially, implement an allowlist approach for actions, parameters, and target domains/APIs mentioned in the instructions. Only permit known, safe directives.
For example:
Only allow Disallow: directives targeting specific URL paths.
allowing API calls, only permit calls to specific, pre-approved API endpoints with expected parameter formats.
Explicitly disallow instructions that look like code execution attempts, file system access, or requests targeting sensitive internal resources.
Least Privilege Principle: The agent processing the llms.txt and executing instructions should run with the absolute minimum privileges necessary.
It should not have access to:
Sensitive API keys (unless specifically required for an allowed action, and handled securely).
Local file systems.
Operating system command execution.
Internal network resources.
User credentials or session data?
Instruction Sanitisation: Attempt to sanitise retrieved instructions, removing or neutralising potentially malicious parts. However, this is notoriously difficult to get right and attackers are adept at finding bypasses (e.g., using different encodings, obfuscation). Relying solely on sanitisation is risky.
Resource Limiting: Impose strict limits on the resources (CPU, memory, network bandwidth, number of API calls) that can be consumed based on instructions from a single llms.txt file. This can prevent denial-of-service attacks.
User Control and Transparency
Configuration Options: Allow users to configure how llms.txt files are handled. Options could include:
Disabling llms.txt processing entirely.
Setting trust levels for different domains.
Requiring manual approval for certain actions instructed by llms.txt.
Logging and Auditing: Log all retrieved llms.txt files, the source they were retrieved from, and any actions taken based on their instructions. This is crucial for forensic analysis if something goes wrong.
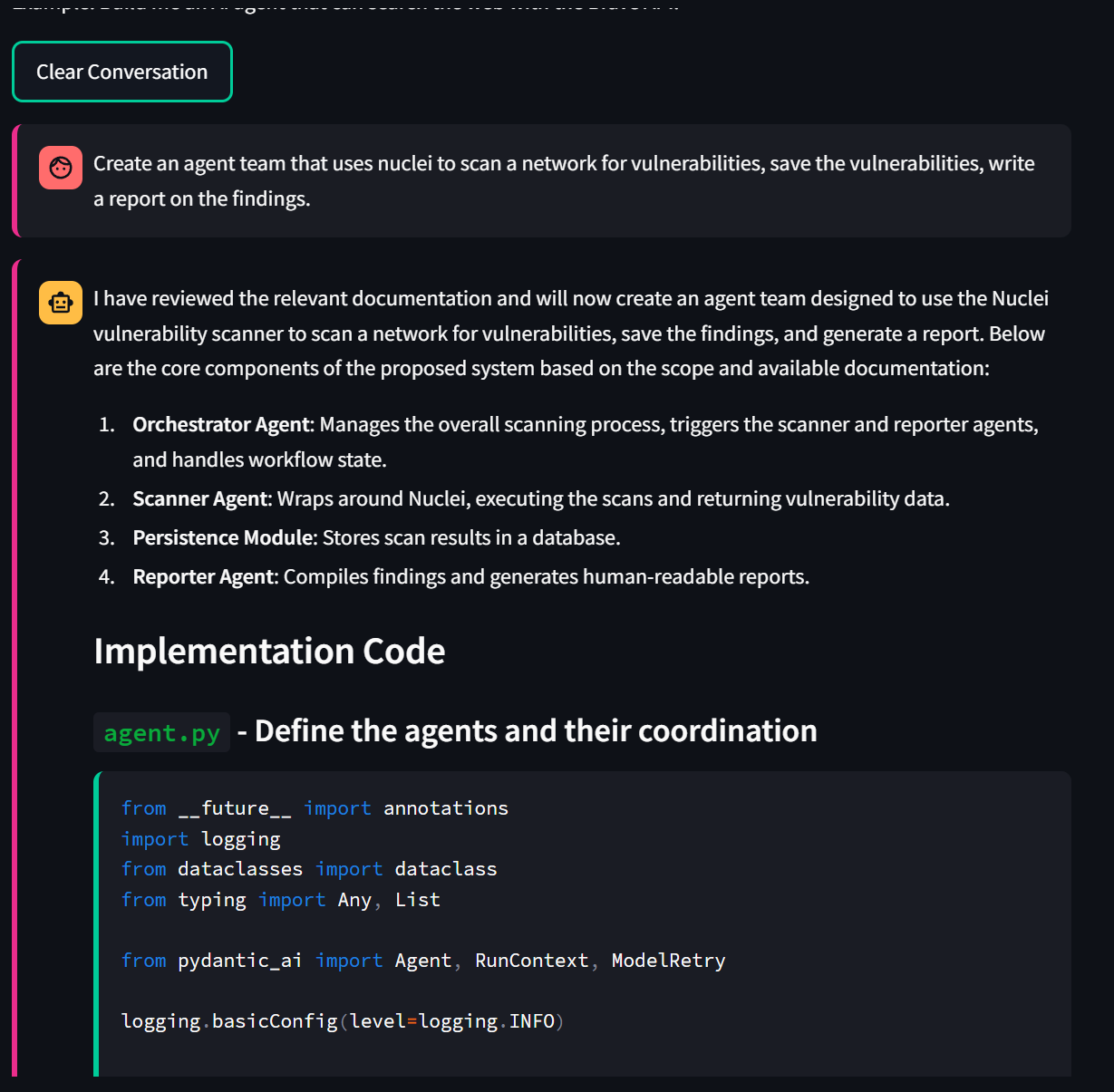
Well I think I have hit a major milestone with Archon:
I imported the llms-full.txt from project discovery about their nuclei vulnerability scanner. The sematic search was able to find all the relevant information needed to build a vulnerability scanning team from Supabase which was really cool to see.
17:14:28.086 reasoner run prompt=
User AI Agent Request: Create an agent team that uses nuc...o creating this agent for the user in the scope document.
17:14:28.105 preparing model and tools run_step=1
17:14:28.106 model request
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
17:14:42.039 handle model response
17:14:42.050 pydantic_ai_coder run stream prompt=Create an agent team that uses nuclei to scan a network for vu...ies, save the vulnerabilities, write a report on the findings.
17:14:42.059 run node StreamUserPromptNode
17:14:42.065 preparing model and tools run_step=1
17:14:42.068 model request run_step=1
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
17:14:42.925 handle model response
17:14:42.954 running tools=['list_documentation_pages']
INFO:httpx:HTTP Request: GET https://<redacted>.supabase.co/rest/v1/site_pages?select=url&metadata-%3E%3Esource=eq.pydantic_ai_docs "HTTP/2 200 OK"
17:14:43.161 run node StreamModelRequestNode
17:14:43.170 preparing model and tools run_step=2
17:14:43.170 model request run_step=2
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
17:14:49.699 handle model response
17:14:49.777 running tools=['retrieve_relevant_documentation', 'retrieve_relevant_documen...ve_relevant_documentation', 'retrieve_relevant_documentation']
--- Performing Hierarchical Retrieval for: 'Nuclei scanning tool usage, configuration, and integration with Pydantic AI.' ---
Supabase client initialized successfully.
--- Performing Hierarchical Retrieval for: 'Pydantic AI agent creation and management best practices.' ---
Supabase client initialized successfully.
--- Performing Hierarchical Retrieval for: 'Database persistence for vulnerability storage.' ---
Supabase client initialized successfully.
--- Performing Hierarchical Retrieval for: 'Report generation libraries and usage.' ---
Supabase client initialized successfully.
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://<redacted>.supabase.co/rest/v1/rpc/match_hierarchical_nodes "HTTP/2 200 OK"
--- Hierarchical Retrieval Found 4 Chunks ---
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://<redacted>.supabase.co/rest/v1/rpc/match_hierarchical_nodes "HTTP/2 200 OK"
--- Hierarchical Retrieval Found 4 Chunks ---
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://<redacted>.supabase.co/rest/v1/rpc/match_hierarchical_nodes "HTTP/2 200 OK"
--- Hierarchical Retrieval Found 4 Chunks ---
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://<redacted>.supabase.co/rest/v1/rpc/match_hierarchical_nodes "HTTP/2 200 OK"
--- Hierarchical Retrieval Found 4 Chunks ---
17:14:55.282 run node StreamModelRequestNode
17:14:55.284 preparing model and tools run_step=3
17:15:54.321 router_agent run prompt=
The user has sent a message:
Expand the impleme... "refine" the agent, respond with just the text "refine".
17:15:54.322 preparing model and tools run_step=1
17:15:54.323 model request
INFO:openai._base_client:Retrying request to /chat/completions in 0.412000 seconds
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
17:15:56.400 handle model response
17:15:56.404 pydantic_ai_coder run stream prompt=Expand the implementation
17:15:56.404 run node StreamUserPromptNode
17:15:56.409 preparing model and tools run_step=1
17:15:56.409 model request run_step=1
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
17:15:57.790 handle model response
17:15:57.791 response stream text
3 Likes
This is incredible, amazing work @HillviewCap!!
1 Like
Wow using openrouter with Claude 3.7 and DeepSeek R1 as the reasoner results in waaay better results and detail. This tools file includes much better detail and capability than the gpt4o with o3 interesting stuff.
import asyncio
import json
import os
import subprocess
import uuid
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
import aiosqlite
import jinja2
from loguru import logger
# Configure base directories
BASE_DIR = Path(__file__).parent
DATA_DIR = BASE_DIR / "data"
REPORTS_DIR = BASE_DIR / "reports"
DB_PATH = DATA_DIR / "vulnerabilities.db"
async def initialize_database() -> None:
"""Initialize the SQLite database with the required schema."""
# Create directories if they don't exist
DATA_DIR.mkdir(exist_ok=True)
REPORTS_DIR.mkdir(exist_ok=True)
async with aiosqlite.connect(DB_PATH) as db:
await db.execute("""
CREATE TABLE IF NOT EXISTS scans (
id TEXT PRIMARY KEY,
target_host TEXT NOT NULL,
scan_date TEXT NOT NULL,
options TEXT,
status TEXT NOT NULL
)
""")
await db.execute("""
CREATE TABLE IF NOT EXISTS vulnerabilities (
id TEXT PRIMARY KEY,
scan_id TEXT NOT NULL,
name TEXT NOT NULL,
severity TEXT NOT NULL,
description TEXT,
template_id TEXT,
matched_at TEXT,
cvss_score REAL,
proof TEXT,
discovered_date TEXT,
FOREIGN KEY (scan_id) REFERENCES scans (id)
)
""")
await db.execute("""
CREATE TABLE IF NOT EXISTS reports (
id TEXT PRIMARY KEY,
scan_id TEXT NOT NULL,
report_path TEXT NOT NULL,
generation_date TEXT NOT NULL,
format TEXT NOT NULL,
FOREIGN KEY (scan_id) REFERENCES scans (id)
)
""")
await db.commit()
async def run_nuclei_scan(target: str, options: Dict[str, Any]) -> Dict[str, Any]:
"""
Execute a Nuclei scan against the target with the provided options.
Args:
target: The target URL or IP to scan.
options: Dictionary of scan options.
Returns:
A dictionary containing the scan results.
"""
logger.info(f"Starting Nuclei scan against {target}")
# Create scan ID
scan_id = str(uuid.uuid4())
scan_date = datetime.now().isoformat()
# Output files
json_output = DATA_DIR / f"scan_{scan_id}.json"
# Build Nuclei command
cmd = ["nuclei"]
cmd.extend(["-target", target])
cmd.extend(["-json", "-o", str(json_output)])
# Add options
if "severity" in options:
severities = ",".join(options["severity"])
cmd.extend(["-severity", severities])
if "tags" in options:
tags = ",".join(options["tags"])
cmd.extend(["-tags", tags])
if "rate-limit" in options:
cmd.extend(["-rate-limit", str(options["rate-limit"])])
if "concurrency" in options:
cmd.extend(["-c", str(options["concurrency"])])
if "templates-dir" in options:
cmd.extend(["-templates-dir", options["templates-dir"]])
# Store scan metadata in the database
await initialize_database()
async with aiosqlite.connect(DB_PATH) as db:
await db.execute(
"INSERT INTO scans (id, target_host, scan_date, options, status) VALUES (?, ?, ?, ?, ?)",
(scan_id, target, scan_date, json.dumps(options), "running")
)
await db.commit()
# Run Nuclei
try:
logger.info(f"Executing command: {' '.join(cmd)}")
process = await asyncio.create_subprocess_exec(
*cmd,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE
)
stdout, stderr = await process.communicate()
if process.returncode != 0:
logger.error(f"Nuclei scan failed: {stderr.decode()}")
# Update scan status
async with aiosqlite.connect(DB_PATH) as db:
await db.execute(
"UPDATE scans SET status = ? WHERE id = ?",
("failed", scan_id)
)
await db.commit()
return {
"scan_id": scan_id,
"status": "failed",
"error": stderr.decode(),
"target": target
}
# Parse results
findings = []
if json_output.exists():
with open(json_output, "r") as f:
for line in f:
try:
finding = json.loads(line)
findings.append(finding)
except json.JSONDecodeError:
logger.warning(f"Could not parse line: {line}")
# Update scan status
async with aiosqlite.connect(DB_PATH) as db:
await db.execute(
"UPDATE scans SET status = ? WHERE id = ?",
("completed", scan_id)
)
await db.commit()
return {
"scan_id": scan_id,
"status": "completed",
"target": target,
"findings": findings,
"timestamp": scan_date,
"options": options
}
except Exception as e:
logger.exception(f"Error during Nuclei scan: {str(e)}")
# Update scan status
async with aiosqlite.connect(DB_PATH) as db:
await db.execute(
"UPDATE scans SET status = ? WHERE id = ?",
("failed", scan_id)
)
await db.commit()
return {
"scan_id": scan_id,
"status": "failed",
"error": str(e),
"target": target
}
async def save_vulnerability_data(scan_results: Dict[str, Any]) -> Dict[str, Any]:
"""
Save vulnerability data from a scan to the database.
Args:
scan_results: The results from a Nuclei scan.
Returns:
Confirmation and metadata about the storage operation.
"""
scan_id = scan_results.get("scan_id")
findings = scan_results.get("findings", [])
if not scan_id:
raise ValueError("Scan ID not found in scan results")
await initialize_database()
async with aiosqlite.connect(DB_PATH) as db:
for finding in findings:
vuln_id = str(uuid.uuid4())
# Extract relevant data from the finding
name = finding.get("info", {}).get("name", "Unknown Vulnerability")
severity = finding.get("info", {}).get("severity", "unknown")
description = finding.get("info", {}).get("description", "")
template_id = finding.get("template-id", "")
matched_at = finding.get("matched-at", "")
cvss_score = finding.get("info", {}).get("classification", {}).get("cvss-score", 0.0)
proof = json.dumps(finding)
discovered_date = datetime.now().isoformat()
# Store vulnerability
await db.execute(
"""
INSERT INTO vulnerabilities
(id, scan_id, name, severity, description, template_id, matched_at, cvss_score, proof, discovered_date)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""",
(vuln_id, scan_id, name, severity, description, template_id, matched_at, cvss_score, proof, discovered_date)
)
await db.commit()
return {
"status": "success",
"scan_id": scan_id,
"vulnerabilities_saved": len(findings),
"timestamp": datetime.now().isoformat()
}
async def get_scan_details(scan_id: str) -> Tuple[Dict[str, Any], List[Dict[str, Any]]]:
"""
Retrieve scan details and vulnerabilities for a given scan ID.
Args:
scan_id: The ID of the scan to retrieve.
Returns:
A tuple containing scan metadata and vulnerability list.
"""
await initialize_database()
async with aiosqlite.connect(DB_PATH) as db:
# Get scan details
db.row_factory = aiosqlite.Row
cursor = await db.execute(
"SELECT * FROM scans WHERE id = ?",
(scan_id,)
)
scan_row = await cursor.fetchone()
if not scan_row:
raise ValueError(f"Scan with ID {scan_id} not found")
scan_details = dict(scan_row)
scan_details["options"] = json.loads(scan_details["options"])
# Get vulnerabilities
cursor = await db.execute(
"SELECT * FROM vulnerabilities WHERE scan_id = ? ORDER BY severity",
(scan_id,)
)
vuln_rows = await cursor.fetchall()
vulnerabilities = [dict(row) for row in vuln_rows]
# Process vulnerability data
for vuln in vulnerabilities:
try:
vuln["proof"] = json.loads(vuln["proof"])
except json.JSONDecodeError:
vuln["proof"] = {"raw": vuln["proof"]}
return scan_details, vulnerabilities
async def generate_report(scan_id: str, format: str = "html") -> Dict[str, str]:
"""
Generate a vulnerability report for a completed scan.
Args:
scan_id: The ID of the scan to generate a report for.
format: The output format (html, pdf, markdown).
Returns:
A dictionary with the report details.
"""
logger.info(f"Generating {format} report for scan {scan_id}")
# Get scan data
try:
scan_details, vulnerabilities = await get_scan_details(scan_id)
except ValueError as e:
return {
"status": "error",
"message": str(e)
}
# Create report directory if it doesn't exist
REPORTS_DIR.mkdir(exist_ok=True)
# Report filename
report_id = str(uuid.uuid4())
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
report_filename = f"vulnerability_report_{scan_id}_{timestamp}"
# Group vulnerabilities by severity
severity_order = {"critical": 0, "high": 1, "medium": 2, "low": 3, "info": 4, "unknown": 5}
vulnerabilities.sort(key=lambda v: severity_order.get(v["severity"].lower(), 999))
vulnerabilities_by_severity = {}
for vuln in vulnerabilities:
severity = vuln["severity"].lower()
if severity not in vulnerabilities_by_severity:
vulnerabilities_by_severity[severity] = []
vulnerabilities_by_severity[severity].append(vuln)
# Load Jinja2 template
env = jinja2.Environment(
loader=jinja2.FileSystemLoader(BASE_DIR / "templates"),
autoescape=True
)
try:
template = env.get_template("vulnerability_report.html")
except jinja2.exceptions.TemplateNotFound:
# Create a basic template if none exists
template_dir = BASE_DIR / "templates"
template_dir.mkdir(exist_ok=True)
with open(template_dir / "vulnerability_report.html", "w") as f:
f.write("""
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Vulnerability Scan Report - {{ scan.target_host }}</title>
<style>
body { font-family: Arial, sans-serif; line-height: 1.6; margin: 0; padding: 20px; color: #333; }
.container { max-width: 1200px; margin: 0 auto; }
h1, h2, h3 { color: #2c3e50; }
.header { border-bottom: 2px solid #3498db; padding-bottom: 10px; margin-bottom: 20px; }
.summary { background: #f8f9fa; padding: 15px; border-radius: 4px; margin-bottom: 20px; }
.vuln-critical { border-left: 5px solid #e74c3c; }
.vuln-high { border-left: 5px solid #e67e22; }
.vuln-medium { border-left: 5px solid #f1c40f; }
.vuln-low { border-left: 5px solid #2ecc71; }
.vuln-info { border-left: 5px solid #3498db; }
.vuln-unknown { border-left: 5px solid #95a5a6; }
.vulnerability { background: white; padding: 15px; margin-bottom: 15px; border-radius: 4px; box-shadow: 0 1px 3px rgba(0,0,0,0.12); }
.severity { display: inline-block; padding: 3px 8px; border-radius: 3px; color: white; font-weight: bold; }
.severity-critical { background-color: #e74c3c; }
.severity-high { background-color: #e67e22; }
.severity-medium { background-color: #f1c40f; color: #333; }
.severity-low { background-color: #2ecc71; }
.severity-info { background-color: #3498db; }
.severity-unknown { background-color: #95a5a6; }
.footer { margin-top: 30px; border-top: 1px solid #eee; padding-top: 10px; font-size: 0.9em; color: #777; }
pre { background: #f8f9fa; padding: 10px; overflow-x: auto; }
table { width: 100%; border-collapse: collapse; margin-bottom: 20px; }
th, td { text-align: left; padding: 8px; border-bottom: 1px solid #ddd; }
th { background-color: #f2f2f2; }
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>Vulnerability Scan Report</h1>
<p>Target: <strong>{{ scan.target_host }}</strong></p>
<p>Scan Date: {{ scan.scan_date }}</p>
<p>Scan ID: {{ scan.id }}</p>
</div>
<div class="summary">
<h2>Executive Summary</h2>
<p>This report contains the results of a vulnerability scan performed on {{ scan.target_host }}.</p>
<table>
<tr>
<th>Severity</th>
<th>Count</th>
</tr>
{% for severity in ['critical', 'high', 'medium', 'low', 'info', 'unknown'] %}
{% if severity in vulnerabilities_by_severity %}
<tr>
<td>
<span class="severity severity-{{ severity }}">{{ severity|upper }}</span>
</td>
<td>{{ vulnerabilities_by_severity[severity]|length }}</td>
</tr>
{% endif %}
{% endfor %}
<tr>
<th>Total</th>
<th>{{ vulnerabilities|length }}</th>
</tr>
</table>
</div>
{% for severity in ['critical', 'high', 'medium', 'low', 'info', 'unknown'] %}
{% if severity in vulnerabilities_by_severity %}
<h2>{{ severity|title }} Severity Vulnerabilities</h2>
{% for vuln in vulnerabilities_by_severity[severity] %}
<div class="vulnerability vuln-{{ severity }}">
<h3>{{ vuln.name }}</h3>
<p>
<span class="severity severity-{{ severity }}">{{ severity|upper }}</span>
{% if vuln.cvss_score > 0 %}
<strong>CVSS Score:</strong> {{ vuln.cvss_score }}
{% endif %}
</p>
<p><strong>Description:</strong> {{ vuln.description }}</p>
{% if vuln.template_id %}
<p><strong>Template ID:</strong> {{ vuln.template_id }}</p>
{% endif %}
<p><strong>Matched at:</strong> {{ vuln.matched_at }}</p>
<p><strong>Discovered:</strong> {{ vuln.discovered_date }}</p>
<h4>Evidence</h4>
<pre>{{ vuln.proof|tojson(indent=2) }}</pre>
<h4>Remediation</h4>
<p>Recommended actions to address this vulnerability:</p>
<ul>
{% if severity == 'critical' or severity == 'high' %}
<li>Apply vendor patches immediately if available</li>
<li>Implement temporary mitigations if patches are not available</li>
<li>Consider isolating affected systems</li>
{% elif severity == 'medium' %}
<li>Apply vendor patches as part of regular maintenance</li>
<li>Consider configuration changes to mitigate the issue</li>
{% else %}
<li>Address during regular maintenance cycles</li>
<li>Update configurations or apply patches when available</li>
{% endif %}
<li>Retest after remediation to confirm the vulnerability has been resolved</li>
</ul>
</div>
{% endfor %}
{% endif %}
{% endfor %}
<div class="footer">
<p>Report generated on {{ generation_date }} using Nuclei Vulnerability Scanner</p>
</div>
</div>
</body>
</html>
""")
template = env.get_template("vulnerability_report.html")
# Render HTML report
html_content = template.render(
scan=scan_details,
vulnerabilities=vulnerabilities,
vulnerabilities_by_severity=vulnerabilities_by_severity,
generation_date=datetime.now().strftime("%Y-%m-%d %H:%M:%S")
)
# Save HTML report
html_path = REPORTS_DIR / f"{report_filename}.html"
with open(html_path, "w") as f:
f.write(html_content)
# Save PDF report if requested
pdf_path = None
if format.lower() == "pdf":
try:
import weasyprint
pdf_path = REPORTS_DIR / f"{report_filename}.pdf"
weasyprint.HTML(string=html_content).write_pdf(pdf_path)
except ImportError:
logger.warning("WeasyPrint not installed. PDF generation skipped.")
# Save Markdown report if requested
markdown_path = None
if format.lower() == "markdown":
import html2text
markdown_converter = html2text.HTML2Text()
markdown_converter.ignore_links = False
markdown_content = markdown_converter.handle(html_content)
markdown_path = REPORTS_DIR / f"{report_filename}.md"
with open(markdown_path, "w") as f:
f.write(markdown_content)
# Store report reference in database
await initialize_database()
async with aiosqlite.connect(DB_PATH) as db:
await db.execute(
"""
INSERT INTO reports
(id, scan_id, report_path, generation_date, format)
VALUES (?, ?, ?, ?, ?)
""",
(report_id, scan_id, str(html_path), datetime.now().isoformat(), format)
)
await db.commit()
return {
"status": "success",
"scan_id": scan_id,
"report_id": report_id,
"report_path": str(html_path),
"pdf_path": str(pdf_path) if pdf_path else None,
"markdown_path": str(markdown_path) if markdown_path else None,
"format": format,
"vulnerabilities_count": len(vulnerabilities),
"generation_date": datetime.now().isoformat()
}
2 Likes
So I have had to have a dabble with the LLM.txt — so using “Full Context CAG” and graph retrieval, particularly with Google Exp 2.5 and new embedding model, and I can see a shift in how we approach code generation coming.
LLM.txt
It keeps the data footprint smaller while somehow packing in even more relevant information, which seems to work incredibly well with large context models like Gemini.
I really feel like we’re on the cusp of moving beyond traditional Augmented RAG.
What I’ve seen is that conventional agentic RAG, with its reliance on fragmented document chunks, often falls short when it comes to truly understanding the nuances of a code framework.
You lose so much crucial contextual information, and the generated code, while maybe syntactically sound, can lack a deeper grasp of the framework’s intricate relationships, dependencies, and overall architecture.
But with this “Full Context CAG” approach, especially when you combine it with the semantic richness and relational understanding you get from graph retrieval, it feels fundamentally different.
Instead of just getting snippets, you’re retrieving entire relevant sections of documentation and code. This gives the agent a much more holistic and nuanced understanding, which translates to:
Code that feels much more coherent and integrates seamlessly with the existing codebase, really adhering to the framework’s design principles.
The agent seems capable of much better reasoning and problem-solving because it can consider larger spans of information and understand the broader implications.
The graph structure inherently captures the connections between different concepts within the framework, which allows the agent to understand the “why” behind certain coding patterns and conventions in a way that traditional RAG just can’t.
And the new embedding models are a game-changer here. They capture such subtle semantic nuances within the text, making the retrieval from the graph so much more accurate and relevant. This combination of full-context retrieval and really sophisticated semantic understanding feels like a massive leap forward. It makes me think that traditional chunk-based RAG might become significantly less effective for complex code generation, especially when we’re dealing with novel and intricate frameworks.
Honestly, playing with this new approach, I really feel like I’ve just seen the future of AI-assisted coding. It’s incredibly exciting!
you can put war and peace into gemini almost 4 times, really insane.
1 Like
I couldn’t agree with you more. It opens up the possibility of applications running with-in context windows while the model is monitoring and adjusting the application live. Imagine a 10 million token context window running an app with the latest knowledge, coding practices, company goals, profit targets? All baked into the application being adjusted as people and machines use the program.
Another problem that LLMs.txt solves is getting the highest quality data into your frontier models as quickly and efficiently as possible. The turnaround time for training new models with cut off dates in the weeks to months’ time frame will become much more possible if you can scrape all the web application, API knowledge in an afternoon and parse it in minutes. Shit they can continuously monitor the code bases and retrain models when a threshold of divergent knowledge is reached. Say 30% of the data you trained your model with is no longer relevant because of application changes, revisions, upgrades etc. The large labs have the resources to know when their model’s knowledge has grown stale enough to start a new training run or optimize the existing models. Or not train them on the data anymore at all and just provide the highly relevant data to the model on the back end via tool calls etc. Why search the internet if you have the data neatly packaged inches away on a server next to your inference.
The one major problem with the CAG approach are the smaller model context windows. Its efficient for Google to do it because they are Google. For smaller cheaper applications RAG will still have a place for a long time. It will take re-imagining how we store the data needed for small context window retrievers. If you want to have privacy focused home agents, they are going to need a cost-effective way to store and retrieve unstructured data. This is where Graph Rag will really help bridge that gap but it’s still very expensive and time consuming to process and create the relationships. I am mostly interested in how we can exploit the small models efficiently locally or offline which I hope this contextual rag approach helps.
This leads me back to why I was excited to try separating the knowledge into nodes and paths using the metadata. having a well-structured document such as the llms.txt it allows us to programmatically split the documents into relevant sections so when an LLM needs information on
a specific topic it can easily retrieve it via context aware searches. The models are also smart enough to know they can search multiple times with different key words. This can also be reinforced in the prompt as well.
One idea I am toying with is contextual code snippets since we know the code snippet is a part of the eg. LangGraph Quickstart (level 0) → How to review tool calls (Functional API) (level 1) section we can match it with the rest of that section gaining back our context by joining the level 1 How to review sections together. Or if the model just needs an example code snippet to fix a syntax error fetching just that section would be more helpful than joining together a bunch of context, flooding the context window with information it doesn’t need.
1 Like
I’m back! I was in Brazil for two weeks for work and got sidetracked by another project.
I was trying build build an LLMS.txt index for Archon and realized it needed to be its own service. So I created it. Currently we are indexing over 700 llms.txt and llms-full.txt for people to discover new services and tools.
Next step will be to build an API so that agent frameworks cans query the index to find services for tools etc. I’ll be using Archon to tes that in the future.
I’ll be jumping back onto getting the llms for rag bandwagon shortly
Here is my forked repo with the working llms rag code if anyone wants to review and test
3 Likes
Awesome @HillviewCap !!
I was really looking forward to the LLMs.txt approach, in my eyes a much efficient approach… But I lack the technical skills to implement it myself. I thank you for your effort.
The only way I can give something back is to test it. It worked flawlessly I must say. But if you do not mind, I’d like to point 2 things:
- An update on the install instructions
- How environment configuration is processed.
Let me explain:
- On your git repo, presently you are still pointing to Cole’s, so I think you could change the instructions to clone yours:
git clone https://github.com/HillviewCap/Archon.git
cd archon
- Since I only run Archon container when I need it, I use the .env file to store all the configuration to save me from the hassle of having to enter it manually on every run.
The first scrap of the LLM.txt failed because it was pulling the config from the environment “webpage” of Archon and not picking it up from the .env file.
Once entered manually, everything worked.
But if it could get the info from the .env I’d be easier for me.
Anyhow, as I said before, many thanks for this.
1 Like