Dear fellows,
first off, as this post might sound impolite: It is not intended to ![]()
I appreciate all contributor’s efforts a lot! I do think that mutli-file-code-assistants like Bolt.new will change the way software is evolving. I love that Stackblitz published its approach with MIT license and appreciate that @ColeMedin and others have started to sort-of democratize it by opening it for other LLMs.
However, to be honest, it seems that the overall quality of the fork is overall a bit low.
You can see this as a user in many places (such as the tag-names like <boltFileModification> which are rendered into the template or by the not verbose error handling when an LLM does not respond properly).
But also looking at the code and the development flow, there are some reddish flags which indicate that the product is far from being mature:
Some samples can be seen in this single screenshot
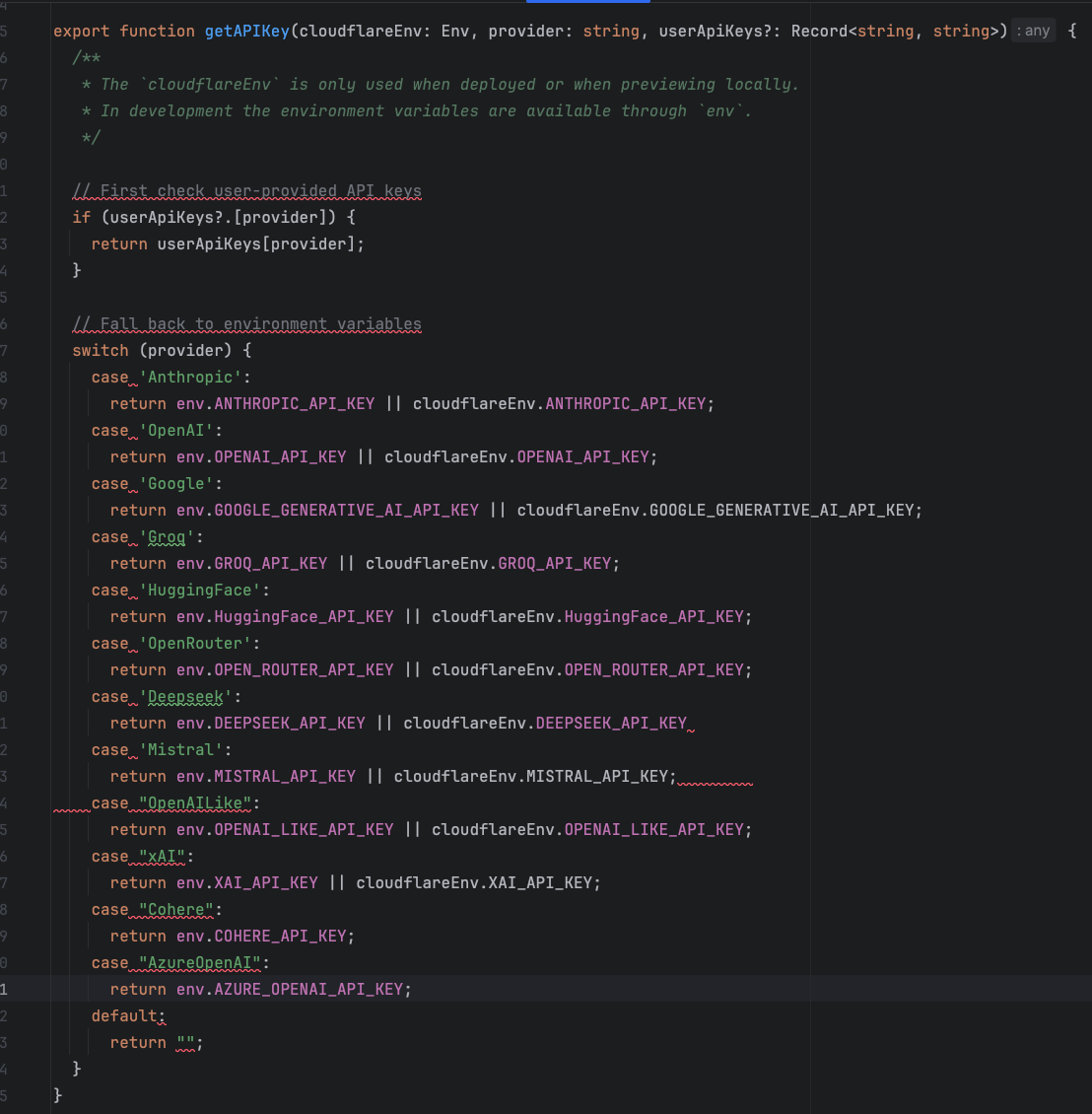
You can see that
- basic linting has not been done (whitespaces at the end of the lines)
- The comments also don’t match the linting rules. This presumably because they generated by Claude / bot.new when modifying itself.
Also, the overall mechanism of loading new LLMs is very … simple and relies on a couple of files being added. Usually, I’d expect some registry-mechanism here to allow for modification free extensibility when e. g. adding new providers.
What’s even more severe when looking at the overall diff to the (now unmaintained) stackblitz/bolt.new upstream is, that it seems there’s no architecture in place which is optimized for minimal invasive modifications.
Also, when checking the commit history on Github, this leaves the impression of a not mature process
We could discuss about linear history or merge commits, but at least commits from PRs should be squashed when merged, imho.
Also, there’s not CICD in place which checks for basic things like linting (see above). This leads to huge PRs which are tricky to review.
There is no mechanism to prevent regression with automated tests (ok, the upstream doesn’t provide this either, to be fair ![]() ).
).
And I could go on…
After all, this leaves me (as a software developer who’s been doing this for some time for a living) a bit in limbo:
Is this fork a solid foundation for building can contributing to a multi-file LLM-workbench or is this just a playground an I’d be better off building something with a solid foundation instead?
I’d love to read from the maintainers (particularly the most active @wonderwhy.er and of course @ColeMedin ) how you look at that.
From my experience, all these things are quite easy to set up, if you do it right from the beginning. All efforts for quality slow down progress a bit, but imho it pays off in the long run. So it would be great to know if you aim at a long running project afterall and how you plan to set things up.
This 3.5k ![]() it definitely shows how huge the potential is, so investing into that right from the “beginning” might be worth it.
it definitely shows how huge the potential is, so investing into that right from the “beginning” might be worth it.
Looking forward to your responses!
Oliver