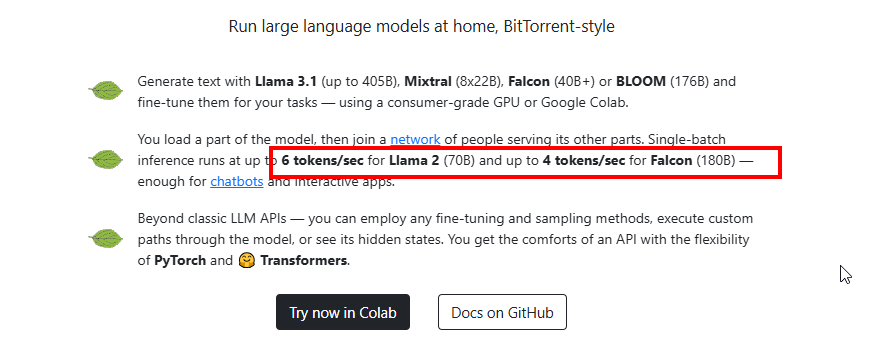
I’m looking for ways to run powerful language models without needing a high-end GPU, and I recently discovered Petals. It seems like a fantastic solution because it uses distributed computing, similar to BitTorrent, which makes it possible to run models like Code Llama even on less powerful hardware.
Has anyone here successfully integrated Petals with Bolt.diy? If so, I would love to hear about your experience and any tips or steps you can share to help set it up.