Is there a way to configure the DeepSeek R1 and V3 API endpoints to allow output token limits higher than 8,000? On bolt.new, I was able to create a website with 100,000 tokens, but bolt.diy currently restricts usage to a maximum of 8,000 tokens. How can this limit be adjusted or expanded?

I believe that is referring to Max Output Tokens which is 8K.
From Deepseek’s website:
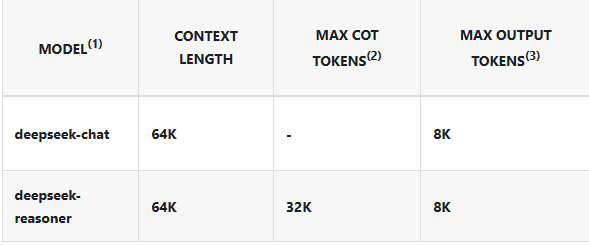
Other providers can have different limits. From OpenRouter’s website:
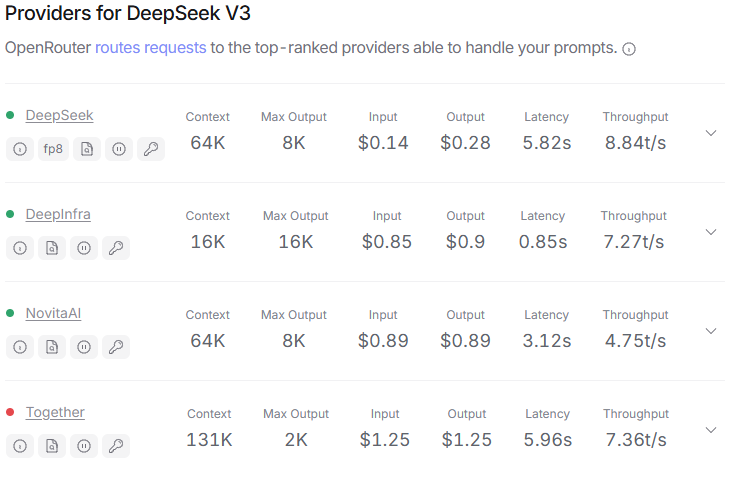
I already updated the maxTokenAllowed parameter in the deepseek.ts file, but it throws an error stating the maximum token limit is 8000. For Hyperbolic, the output limit should theoretically be 130k tokens. I configured Deepseek there(hyperbolic.ts) and set the max token to 100k, but even so, it doesn’t exceed 8000 tokens in usage. However, in this case, it doesn’t flag an error about the 8000-token limit, it simply doesn’t utilize more tokens. Could there be other parts of the code that also need adjustments?
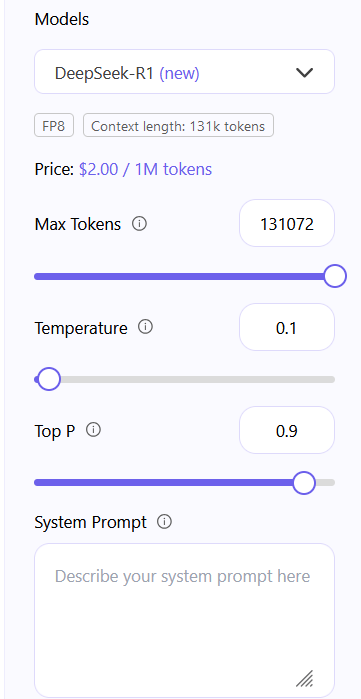
This is the input context size. not the output
Same here, as @sfason65 said. You just mix up context size with output tokens.
Where is your screenshot from? LMStudio with a local model Deepseek-R1 running?
It says “the maximum number of tokens that will be generated for each user prompt”
So its the input token, not the output right?
As far as I know, Deepseek’s own API has a maximum token limit of 8k for outputs, but when running locally, this can be scaled arbitrarily (though I’m not entirely sure about this). I assumed that the Hyperbolic provider operates by running models on their own local machines, thereby offering larger output sizes through their own API.
My screenshot is available here, in the right-hand sidebar: “Hyperbolic AI Dashboard”.
@farkasricsi2030 thanks for clarifying and showing the screenshot.
I think it does.
No this is the output token as you guessed, but I think hyperbolic did not make sure here this settings matches the max of the model you choose, its also 0 - 131k. That just a generic slider and if you choose the max there is limited by the model internal specification before reaching the max you set there.
Thats at least what would make sense for me, but you could ask their support ![]()