have you ever seen bolt.diy putting the end tag of an artifact in the code and the rest of the explanation prompt in the code as well ?
1 Like
Yes, happens mostly with Models which are to small or no instruct models, or just not fit for bolt.
Which one do you use?
Edit: Just saw you collapesed it and its qwen-coder:32. But yeah compared to the big models like Antrophic or Google Gemini 2.0 Flash its still very small.
Did you use the “Default prompt” or the “Optimized” one?
i use the default prompt, and all the default parameters,
also tried code llama (which is terrible), and llama 3.3 70B which is slow and for code - qwen-coder is better (even the small ones)
Ok, maybe try using the optimized prompt and see if its better. I think you cant do anything else at the moment instead of this or trying to prompt better.
Ah I just saw you are implementing python code. The prompts and bolt is not capable of implementing python code. It´s also not runnable within the webcontainer.
So thats the main problem.
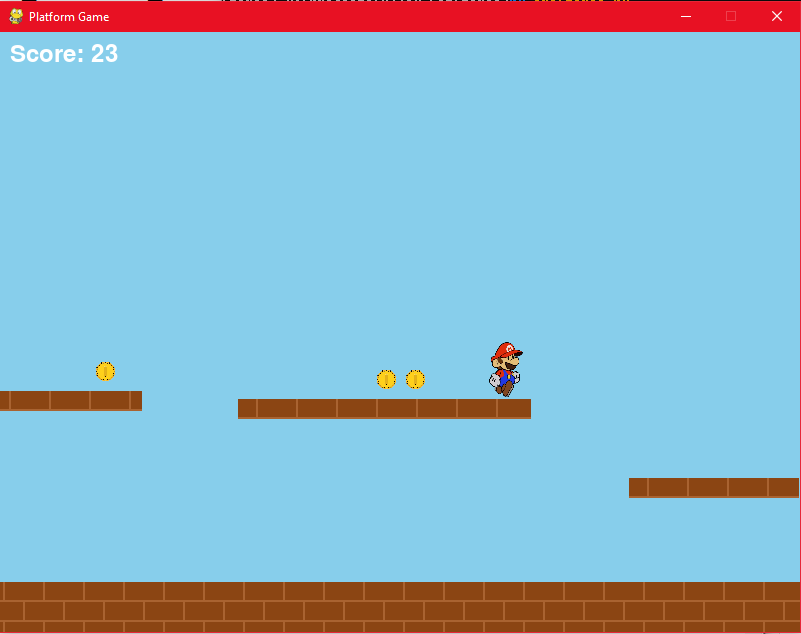
so i have been working on several python samples just to try it out, and it works perfectly (although not able to preview), i also tried java and javascript, they all seem to work
it basically wrote me a simple mario game
2 Likes
b.t.w
once the end tag and text are in the code - you can’t get rid of them
i tried deleting the lines and pressing save, but when i prompt for the next task the line returns
Sure it will do the job anyhow but as said, bolt is not optimized at the moment to do it. So its likely to fail, what we can see in your initial post.
bolt is just using the chat history and does not recognize manual changes at the moment. It´s on the roadmap, but not working yet.
You would need to workaround by exporting it and importing again before continue with prompting.
2 Likes
i got to admit, it worked perfectly for few days and occurred only today - i think if i will restart everything it should go away (until it will re-occur)
do you have a suggestion of which model to use (i only have 2X3090)
i will try this workaround - thanks
ONLY ![]() I think most people would be very happy to have this.
I think most people would be very happy to have this.
I think @ColeMedin has the same setup and can tell you better whats working best ![]()
3 Likes
@warehousehd take a look here: My 2x 3090 GPU LLM Build
1 Like
Haha. Hold my beer…!
Did you see Jensen Huang at CES showing the new tech including the 50 series. Price drop and increase in performance that’s insane…

1 Like
Yeah it’s pretty awesome! Though for LLM inference the most important thing is VRAM and the 5090 is the only GPU that has more VRAM than a 3090. So you’d have to justify paying $2,000 for a new 5090 vs $700 for a used 3090 to get 32GB of VRAM instead of 24GB.
1 Like