I’m new to this community and not a really technical person so it was hard for me to get even to this point, but now I ask for a “little help” with an error.
Just installed bolt.diy and Ollama (both locally, NOT in docker) but when i try to use it, it doesn’t respond. I send some screenshot about the (I think) important details, do you know what is the problem and how can I solve it?
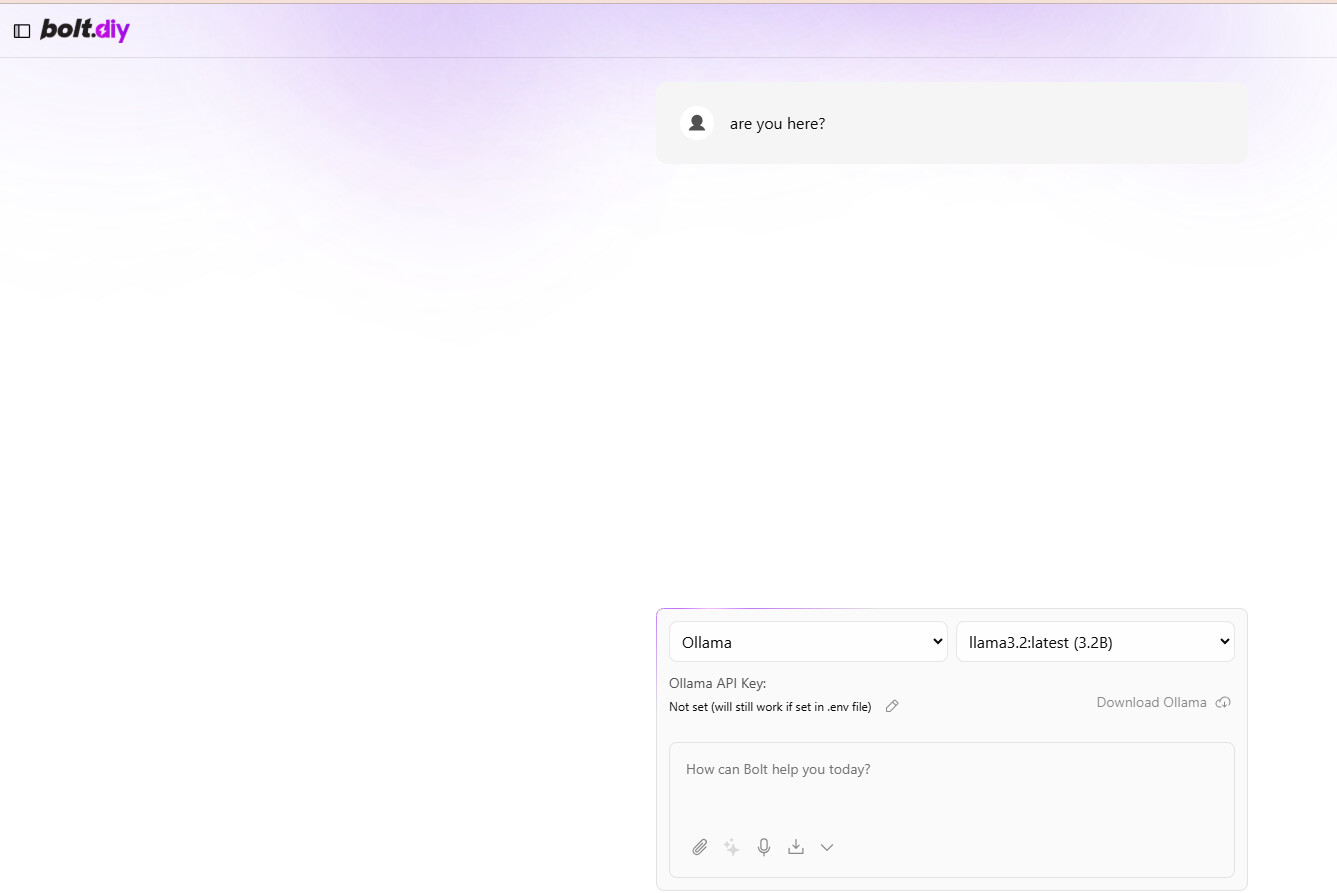
I reach the bolt.diy as well, configured the base URL and it sees Ollama as well.
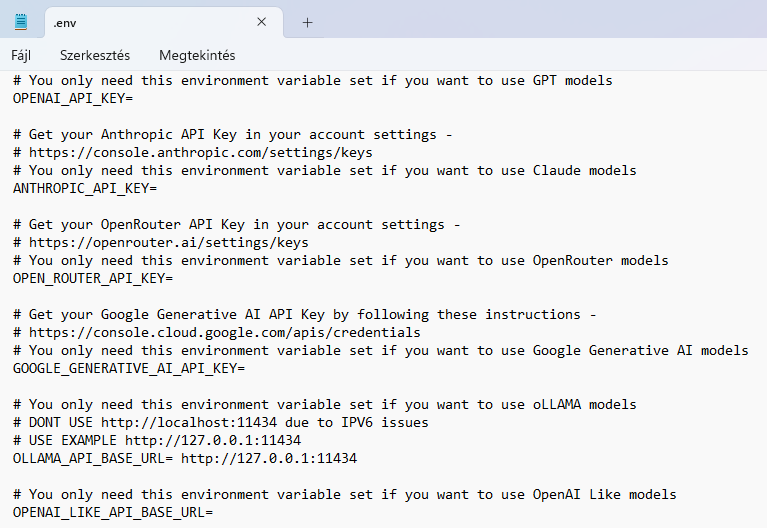
I filled the Ollama part of the env file like this and renamed the file just simply to “.env”.
But when I try to speak with Ollama trough bolt, I get this error.
I hope I was detailed enough. Can I get some help with it please? Thank you. (As I can just embed 1 media in a post as new user, I will put them in comments.)
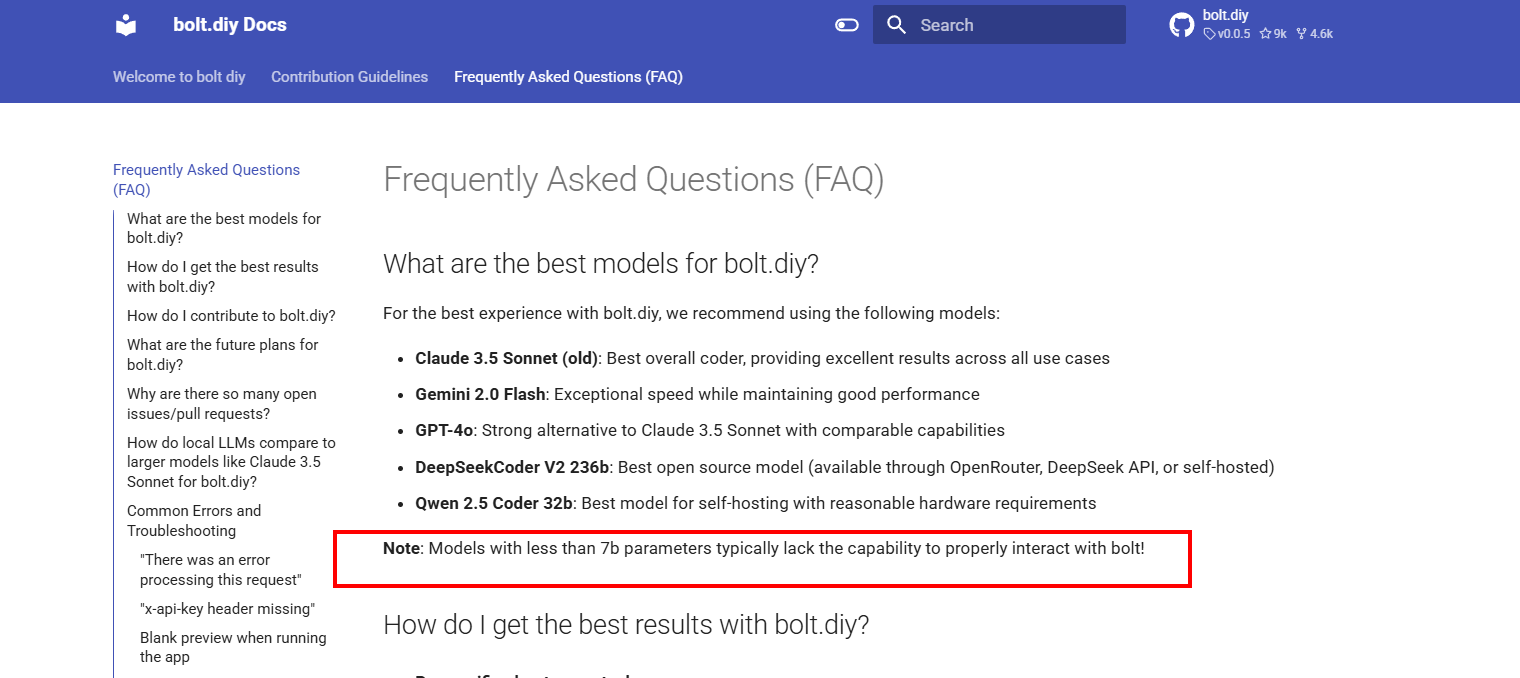
Even with 14b and partly 32b you can get problems or not very good results compared to the big ones online.
I would suggest to use Google Gemini 2.0 Flash, as it is free, if you cant run bigger models. In my view there is no reason to try with local Ollama if you really want to develop something good (unless you get some very good hardware at home, what most private users not have)
Hi @leex279 ! Thank you for the fast answer! I don’t really have the resource for those more robust models (my pc has just i7-7700, rtx2070 etc…not to mention my work laptop ). I’ll try to integrate with something else, as you said!
As @leex279 states, generally only “Instruct” models > 7B work with artifacts. If you need a super small model to work with bolt, the only one I have seen work is QwQ-LCoT-3B-Instruct
Command to install it: ollama run hf.co/mradermacher/QwQ-LCoT-3B-Instruct-GGUF:Q4_K_M
Other than that, you would probably need to run a larger model. Generally you want to make sure it’s also an “Instruct” model, but this can vary.
Thank you for the answer! Tried it but even with that model I get the same error, so I guess I have to wait. At my workplace the infra team is trying to set it up so I guess I just wait until they finish it, I just wanted a local version until that.
Before I even try to configure it, reading those numbers it worth to mention, that my workplace laptop has just az integrated video card and my home pc 2070 has just 8gb RAM, is it possible/even worth trying to set it? What would be the right context here?
The VRAM estimated usage I believe is assuming non-quantized models and I believe maybe a 14B+ model (probably larger). For the 3B quantized model, 32,768 should be fine and only add a GB or two. So basically context RAM size is not static like that.
And with 8GB VRAM, maybe just use the 7B model, uses like 3.6GB: ollama run hf.co/mradermacher/QwQ-LCoT-7B-Instruct-GGUF:Q4_K_M
You should have better luck.
P.S. The 4bit Quantized models only seem to use about half of their size worth of RAM. So you may be able to run the Qwen2.5-Coder-14B-Instruct model, which is pretty good. You can find this one officially on Ollama’s website and just choose the parameter (0.5B to 32B). Go with the largest one your system can handle (probably the 14B). Based on the size of 9.0GB, it should run < 5GB (but I’m not sure as I don’t remember). So even bumping up the context size, your system should still have leg room.
I’d have to test to get accurate numbers. I just know from my testing… bumping up the 7B 4bit quantized model to 32k I believe only used like an extra < 1GB of RAM. So, I see it more of a % of the model size, not static values… But the ratio and whatnot, idk.
Worth a check.
Update: Reading up online, it basically seems to be an unknown thing, with people making clearly false claims (and just rounding up). Would be nice to see if there was a consistency to this with perhaps a formula (and then just handle it dynamically in the UI?). Maybe token/sec performance could also be calculated (but would also need to take into account system specs, so idk).
Hell, I would also like to know what platform (vLLM, Ollama, LMStudio, etc.) gives you the best bang for your buck (best performance given the hardware). Based on my reading though, I believe this is vLLM > Ollama > LMStudio, etc. And maybe it sounds dumb but taking this even further I do wonder about BF16 “simulation” because only commercial Tesla Ada cards have hardware support for it (the math is simple though), but the performance of BF16 vs FP16 is literally 4x the TFLOP/S (with some accuracy loss perhaps, but hey!).
Considerations to determining VRAM/RAM usage for a model: