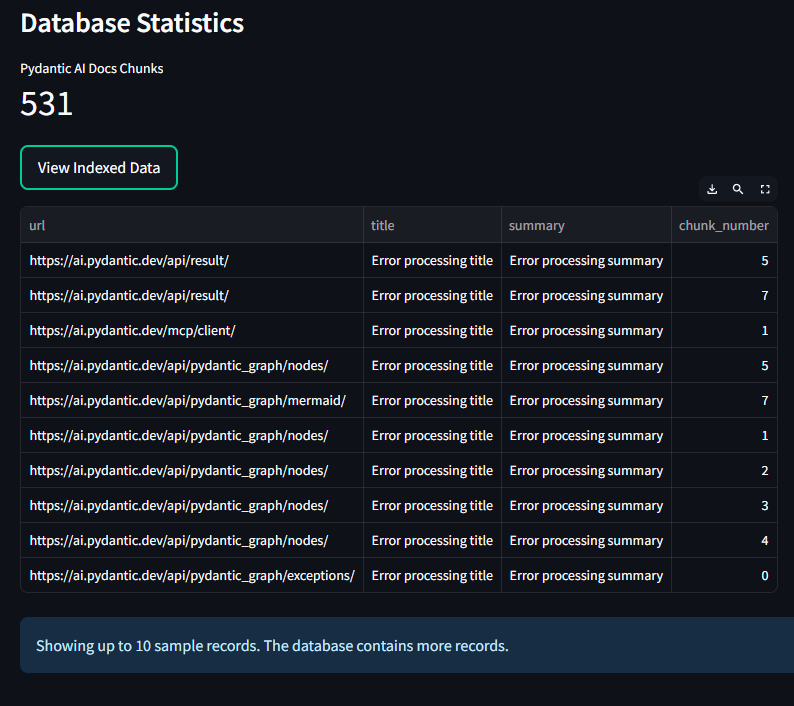
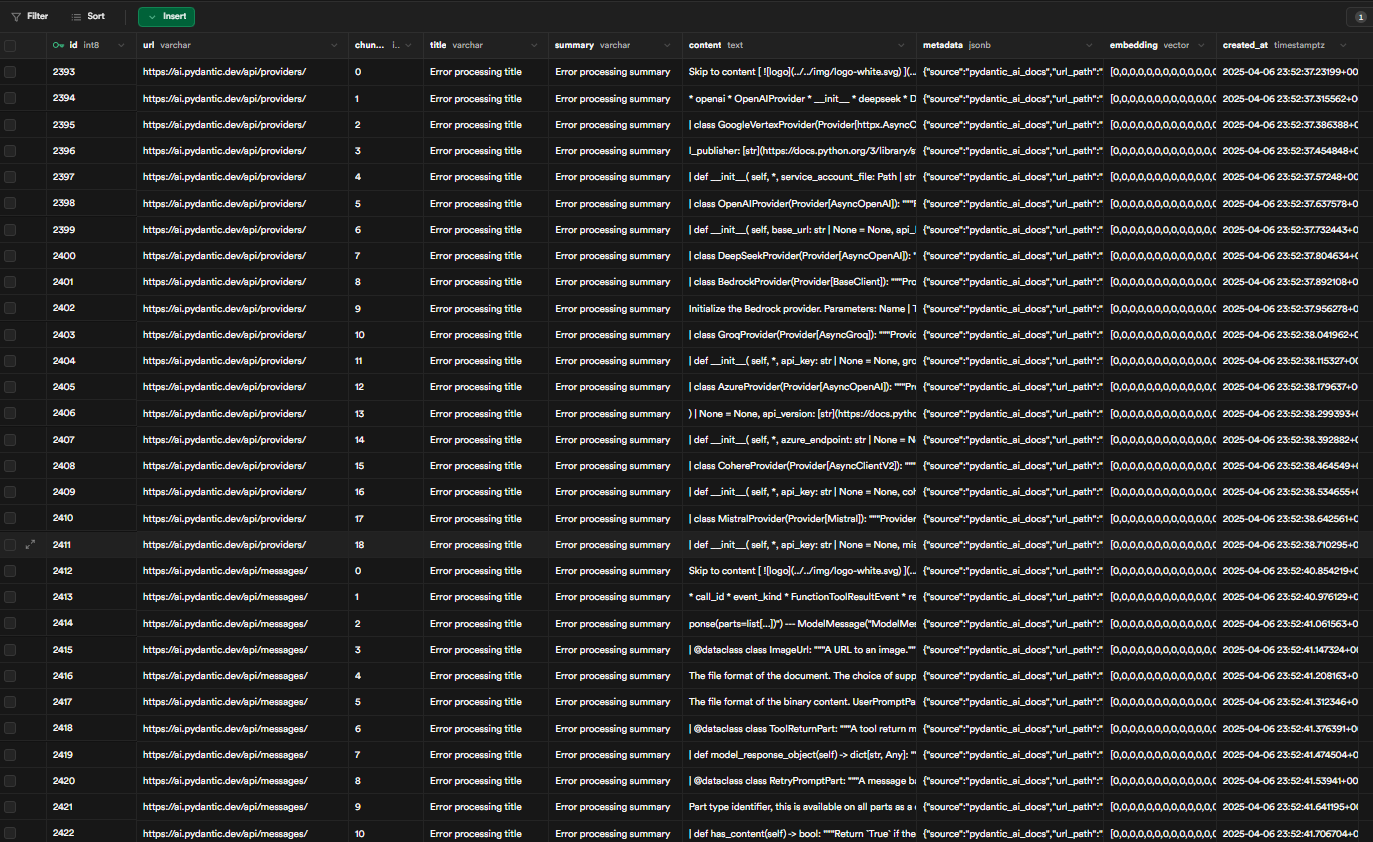
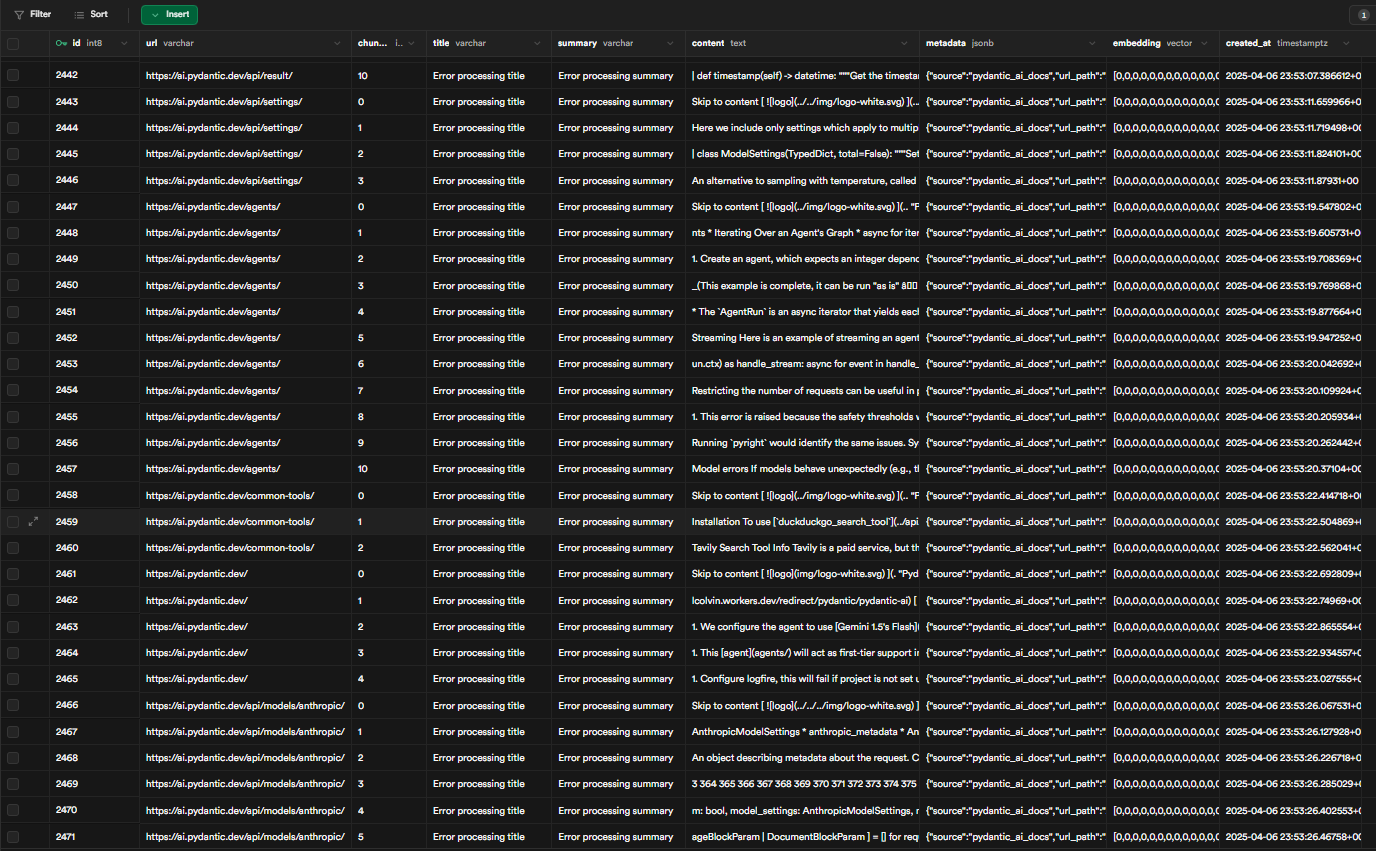
Update: After debugging SQL script in supabase, I found the following will correct the run error, "-- Enable the pgvector extension
CREATE EXTENSION IF NOT EXISTS vector;
– Create the site_pages table if it doesn’t exist
CREATE TABLE IF NOT EXISTS site_pages (
id bigserial PRIMARY KEY,
url varchar NOT NULL,
chunk_number integer NOT NULL,
title varchar NOT NULL,
summary varchar NOT NULL,
content text NOT NULL,
metadata jsonb NOT NULL DEFAULT ‘{}’::jsonb,
embedding vector(768),
created_at timestamp WITH TIME ZONE DEFAULT timezone(‘utc’::text, now()) NOT NULL,
UNIQUE(url, chunk_number)
);
– Create an index for vector similarity search if it doesn’t exist
CREATE INDEX IF NOT EXISTS site_pages_embedding_idx
ON site_pages USING ivfflat (embedding vector_cosine_ops);
– Create an index on metadata for faster filtering if it doesn’t exist
CREATE INDEX IF NOT EXISTS idx_site_pages_metadata
ON site_pages USING gin (metadata);
– Create or replace the function to search for documentation chunks
CREATE OR REPLACE FUNCTION match_site_pages (
query_embedding vector(768),
match_count int DEFAULT 10,
filter jsonb DEFAULT ‘{}’::jsonb
) RETURNS TABLE (
id bigint,
url varchar,
chunk_number integer,
title varchar,
summary varchar,
content text,
metadata jsonb,
similarity float
)
LANGUAGE plpgsql
AS $$
#variable_conflict use_column
BEGIN
RETURN QUERY
SELECT
id,
url,
chunk_number,
title,
summary,
content,
metadata,
1 - (site_pages.embedding <=> query_embedding) AS similarity
FROM site_pages
WHERE metadata @> filter
ORDER BY site_pages.embedding <=> query_embedding
LIMIT match_count;
END;
$$;
– Enable RLS on the table (this is safe to run multiple times)
ALTER TABLE site_pages ENABLE ROW LEVEL SECURITY;
– Create a policy for public read access (replaces if it exists)
CREATE POLICY “Allow public read access”
ON site_pages
FOR SELECT
TO public
USING (true);"